K8s - 安装部署Kafka、Zookeeper集群教程(支持从K8s外部访问)
本文演示如何在K8s集群下部署Kafka集群,并且搭建后除了可以K8s内部访问Kafka服务,也支持从K8s集群外部访问Kafka服务。服务的集群部署通常有两种方式:一种是 StatefulSet,另一种是 Service&Deployment。本次我们使用 StatefulSet 方式搭建 ZooKeeper 集群,使用 Service&Deployment 搭建 Kafka 集群。
一、创建 NFS 存储
NFS 存储主要是为了给 Kafka、ZooKeeper 提供稳定的后端存储,当 Kafka、ZooKeeper 的 Pod 发生故障重启或迁移后,依然能获得原先的数据。
1,安装 NFS
yum -y install nfs-utils
yum -y install rpcbind
2,创建共享文件夹
mkdir -p /usr/local/k8s/zookeeper/pv{1..3}
mkdir -p /usr/local/k8s/kafka/pv{1..3}
(2)编辑 /etc/exports 文件:
vim /etc/exports
(3)在里面添加如下内容:
/usr/local/k8s/kafka/pv1 *(rw,sync,no_root_squash)
/usr/local/k8s/kafka/pv2 *(rw,sync,no_root_squash)
/usr/local/k8s/kafka/pv3 *(rw,sync,no_root_squash)
/usr/local/k8s/zookeeper/pv1 *(rw,sync,no_root_squash)
/usr/local/k8s/zookeeper/pv2 *(rw,sync,no_root_squash)
/usr/local/k8s/zookeeper/pv3 *(rw,sync,no_root_squash)
(4)保存退出后执行如下命令重启服务:
如果执行 systemctl restart nfs 报“Failed to restart nfs.service: Unit nfs.service not found.”错误,可以尝试改用如下命令:
- sudo service nfs-server start
systemctl restart rpcbind
systemctl restart nfs
systemctl enable nfs
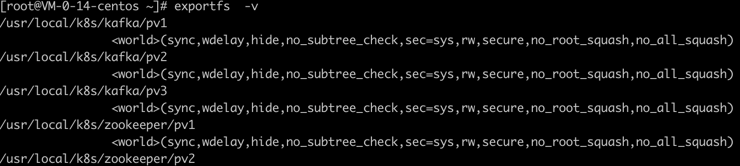
(5)执行 exportfs -v 命令可以显示出所有的共享目录:
(6)而其他的 Node 节点上需要执行如下命令安装 nfs-utils 客户端:
yum -y install nfs-util
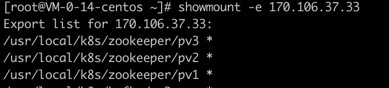
(7)然后其他的 Node 节点上可执行如下命令(ip 为 Master 节点 IP)查看 Master 节点上共享的文件夹:
showmount -e 107.106.37.33(nfs服务端的IP)
二、创建 ZooKeeper 集群
1,创建 ZooKeeper PV
(1)首先创建一个 zookeeper-pv.yaml 文件,内容如下:
apiVersion: v1
kind: PersistentVolume
metadata:
name: k8s-pv-zk01
labels:
app: zk
annotations:
volume.beta.kubernetes.io/storage-class: "anything"
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
nfs:
server: 170.106.37.33
path: "/usr/local/k8s/zookeeper/pv1"
persistentVolumeReclaimPolicy: Recycle
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: k8s-pv-zk02
labels:
app: zk
annotations:
volume.beta.kubernetes.io/storage-class: "anything"
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
nfs:
server: 170.106.37.33
path: "/usr/local/k8s/zookeeper/pv2"
persistentVolumeReclaimPolicy: Recycle
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: k8s-pv-zk03
labels:
app: zk
annotations:
volume.beta.kubernetes.io/storage-class: "anything"
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
nfs:
server: 170.106.37.33
path: "/usr/local/k8s/zookeeper/pv3"
persistentVolumeReclaimPolicy: Recycle
(2)然后执行如下命令创建 PV:
kubectl apply -f zookeeper-pv.yaml
(3)执行如下命令可以查看是否创建成功:
kubectl get pv
2,创建 ZooKeeper 集群
apiVersion: v1
kind: Service
metadata:
name: zk-hs
labels:
app: zk
spec:
selector:
app: zk
clusterIP: None
ports:
- name: server
port: 2888
- name: leader-election
port: 3888
---
apiVersion: v1
kind: Service
metadata:
name: zk-cs
labels:
app: zk
spec:
selector:
app: zk
type: NodePort
ports:
- name: client
port: 2181
nodePort: 31811
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
spec:
serviceName: "zk-hs"
replicas: 3 # by default is 1
selector:
matchLabels:
app: zk # has to match .spec.template.metadata.labels
updateStrategy:
type: RollingUpdate
podManagementPolicy: Parallel
template:
metadata:
labels:
app: zk # has to match .spec.selector.matchLabels
spec:
containers:
- name: zk
imagePullPolicy: Always
image: leolee32/kubernetes-library:kubernetes-zookeeper1.0-3.4.10
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=4G \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
volumeClaimTemplates:
- metadata:
name: datadir
annotations:
volume.beta.kubernetes.io/storage-class: "anything"
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
(2)然后执行如下命令开始创建:
kubectl apply -f zookeeper.yaml
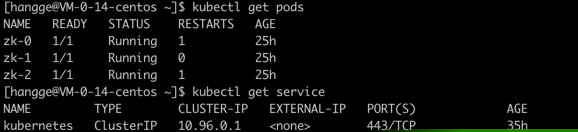
(3)执行如下命令可以查看是否创建成功:
kubectl get pods
kubectl get service
三、创建 Kafka 集群
- nfs 地址需要改成实际 NFS 服务器地址。
- status.hostIP 表示宿主机的 IP,即 Pod 实际最终部署的 Node 节点 IP(本文我是直接部署到 Master 节点上),将 KAFKA_ADVERTISED_HOST_NAME 设置为宿主机 IP 可以确保 K8s 集群外部也可以访问 Kafka
apiVersion: v1
kind: Service
metadata:
name: kafka-service-1
labels:
app: kafka-service-1
spec:
type: NodePort
ports:
- port: 9092
name: kafka-service-1
targetPort: 9092
nodePort: 30901
protocol: TCP
selector:
app: kafka-1
---
apiVersion: v1
kind: Service
metadata:
name: kafka-service-2
labels:
app: kafka-service-2
spec:
type: NodePort
ports:
- port: 9092
name: kafka-service-2
targetPort: 9092
nodePort: 30902
protocol: TCP
selector:
app: kafka-2
---
apiVersion: v1
kind: Service
metadata:
name: kafka-service-3
labels:
app: kafka-service-3
spec:
type: NodePort
ports:
- port: 9092
name: kafka-service-3
targetPort: 9092
nodePort: 30903
protocol: TCP
selector:
app: kafka-3
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-deployment-1
spec:
replicas: 1
selector:
matchLabels:
app: kafka-1
template:
metadata:
labels:
app: kafka-1
spec:
containers:
- name: kafka-1
image: wurstmeister/kafka
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9092
env:
- name: KAFKA_ZOOKEEPER_CONNECT
value: zk-0.zk-hs.default.svc.cluster.local:2181,zk-1.zk-hs.default.svc.cluster.local:2181,zk-2.zk-hs.default.svc.cluster.local:2181
- name: KAFKA_BROKER_ID
value: "1"
- name: KAFKA_CREATE_TOPICS
value: mytopic:2:1
- name: KAFKA_LISTENERS
value: PLAINTEXT://0.0.0.0:9092
- name: KAFKA_ADVERTISED_PORT
value: "30901"
- name: KAFKA_ADVERTISED_HOST_NAME
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumeMounts:
- name: datadir
mountPath: /var/lib/kafka
volumes:
- name: datadir
nfs:
server: 170.106.37.33
path: "/usr/local/k8s/kafka/pv1"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-deployment-2
spec:
replicas: 1
selector:
matchLabels:
app: kafka-2
template:
metadata:
labels:
app: kafka-2
spec:
containers:
- name: kafka-2
image: wurstmeister/kafka
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9092
env:
- name: KAFKA_ZOOKEEPER_CONNECT
value: zk-0.zk-hs.default.svc.cluster.local:2181,zk-1.zk-hs.default.svc.cluster.local:2181,zk-2.zk-hs.default.svc.cluster.local:2181
- name: KAFKA_BROKER_ID
value: "2"
- name: KAFKA_LISTENERS
value: PLAINTEXT://0.0.0.0:9092
- name: KAFKA_ADVERTISED_PORT
value: "30902"
- name: KAFKA_ADVERTISED_HOST_NAME
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumeMounts:
- name: datadir
mountPath: /var/lib/kafka
volumes:
- name: datadir
nfs:
server: 170.106.37.33
path: "/usr/local/k8s/kafka/pv2"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-deployment-3
spec:
replicas: 1
selector:
matchLabels:
app: kafka-3
template:
metadata:
labels:
app: kafka-3
spec:
containers:
- name: kafka-3
image: wurstmeister/kafka
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9092
env:
- name: KAFKA_ZOOKEEPER_CONNECT
value: zk-0.zk-hs.default.svc.cluster.local:2181,zk-1.zk-hs.default.svc.cluster.local:2181,zk-2.zk-hs.default.svc.cluster.local:2181
- name: KAFKA_BROKER_ID
value: "3"
- name: KAFKA_LISTENERS
value: PLAINTEXT://0.0.0.0:9092
- name: KAFKA_ADVERTISED_PORT
value: "30903"
- name: KAFKA_ADVERTISED_HOST_NAME
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumeMounts:
- name: datadir
mountPath: /var/lib/kafka
volumes:
- name: datadir
nfs:
server: 170.106.37.33
path: "/usr/local/k8s/kafka/pv3"
(2)然后执行如下命令开始创建:
kubectl apply -f kafka.yaml
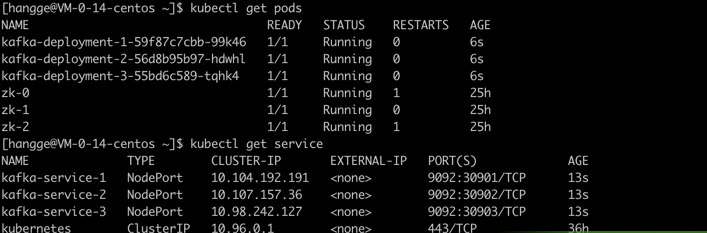
(3)执行如下命令可以查看是否创建成功:
kubectl get pods
kubectl get service
四、开始测试
1,K8s 集群内部测试
kubectl exec -it kafka-deployment-1-59f87c7cbb-99k46 /bin/bash
(2)接着执行如下命令创建一个名为 test_topic 的 topic:
kafka-topics.sh --create --topic test_topic --zookeeper zk-0.zk-hs.default.svc.cluster.local:2181,zk-1.zk-hs.default.svc.cluster.local:2181,zk-2.zk-hs.default.svc.cluster.local:2181 --partitions 1 --replication-factor 1
(3)创建后执行如下命令开启一个生产者,启动后可以直接在控制台中输入消息来发送,控制台中的每一行数据都会被视为一条消息来发送。
kafka-console-producer.sh --broker-list kafka-service-1:9092,kafka-service-2:9092,kafka-service-3:9092 --topic test_topic
(4)重新再打开一个终端连接服务器,然后进入容器后执行如下命令开启一个消费者:
kafka-console-consumer.sh --bootstrap-server kafka-service-1:9092,kafka-service-2:9092,kafka-service-3:9092 --topic test_topic
(5)再次打开之前的消息生产客户端来发送消息,并观察消费者这边对消息的输出来体验 Kafka 对消息的基础处理。

2,集群外出测试
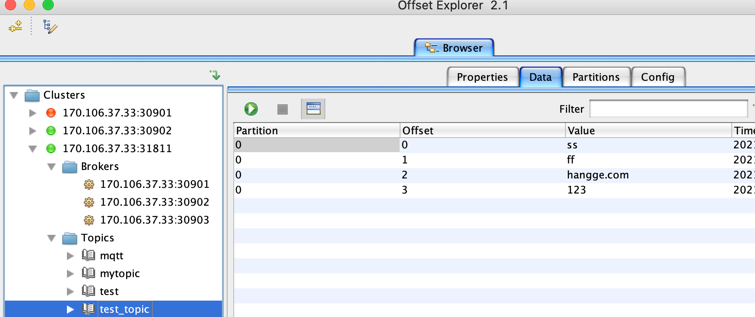
更多的测试命令参考:
二、Kafka生产者消费者实例(基于命令行)
1.创建一个itcasttopic的主题
代码如下(示例):
kafka-topics.sh --create --topic itcasttopic --partitions 3 --replication-factor 2 -zookeeper 10.0.0.27:2181,10.0.0.103:2181,10.0.0.37:2181 2.hadoop01当生产者
代码如下(示例):
kafka-console-producer.sh --broker-list kafka-service-1:9092,kafka-service-2:9092,kafka-service-3:9092 --topic itcasttopic 3.hadoop02当消费者
代码如下(示例):
kafka-console-consumer.sh --from-beginning --topic itcasttopic --bootstrap-server kafka-service-1:9092,kafka-service-2:9092,kafka-service-3:9092 3.–list查看所有主题
代码如下(示例):
kafka-topics.sh --list --zookeeper 10.0.0.27:2181,10.0.0.103:2181,10.0.0.37:2181 4.删除主题
代码如下(示例):
kafka-topics.sh --delete --zookeeper 10.0.0.27:2181,10.0.0.103:2181,10.0.0.37:2181 --topic itcasttopic 5.关闭kafka
代码如下(示例):
bin/kafka-server-stop.sh config/server.properties

K8s - 安装部署Kafka、Zookeeper集群教程(支持从K8s外部访问)的更多相关文章
- Zookeeper详解(02) - zookeeper安装部署-单机模式-集群模式
Zookeeper详解(02) - zookeeper安装部署-单机模式-集群模式 安装包下载 官网首页:https://zookeeper.apache.org/ 历史版本下载地址:http://a ...
- kafka+zookeeper集群
参考: kafka中文文档 快速搭建kafka+zookeeper高可用集群 kafka+zookeeper集群搭建 kafka+zookeeper集群部署 kafka集群部署 kafk ...
- 消息中间件kafka+zookeeper集群部署、测试与应用
业务系统中,通常会遇到这些场景:A系统向B系统主动推送一个处理请求:A系统向B系统发送一个业务处理请求,因为某些原因(断电.宕机..),B业务系统挂机了,A系统发起的请求处理失败:前端应用并发量过大, ...
- Kafka+Zookeeper集群搭建
上次介绍了ES集群搭建的方法,希望能帮助大家,这儿我再接着介绍kafka集群,接着上次搭建的效果. 首先我们来简单了解下什么是kafka和zookeeper? Apache kafka 是一个分布式的 ...
- Kafka/Zookeeper集群的实现(二)
[root@kafkazk1 ~]# wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12. ...
- 安装kafka + zookeeper集群
系统:centos 7.4 要求:jdk :1.8.x kafka_2.11-1.1.0 1.绑定/etc/hosts 10.10.10.xxx online-ops-xxx-0110.10 ...
- KAFKA && zookeeper 集群安装
服务器:#vim /etc/hosts10.16.166.90 sh-xxx-xxx-xxx-online-0110.16.168.220 sh-xx-xxx-xxx-online-0210.16.1 ...
- Linux下部署Kafka分布式集群,安装与测试
注意:部署Kafka之前先部署环境JAVA.Zookeeper 准备三台CentOS_6.5_x64服务器,分别是:IP: 192.168.0.249 dbTest249 Kafka IP: 192. ...
- docker-搭建 kafka+zookeeper集群
拉取容器 docker pull wurstmeister/zookeeper docker pull wurstmeister/kafka 这里演示使 ...
- 在三台Centos或Windows中部署三台Zookeeper集群配置
一.安装包 1.下载最新版(3.4.13):https://archive.apache.org/dist/zookeeper/ 下载https://archive.apache.org/dist/ ...
随机推荐
- JDBC的增删改-结果集的元数据-Class反射-JDBC查询封装
一.使用JDBC批量添加 知识点复习: 1.JDBC的六大步骤 (导入jar包, 加载驱动类,获取连接对象, 获取sql执行器.执行sql与并返回结果, 关闭数据库连接) 2.封装了一个DBU ...
- Spring-Bean实例化三种的方式
Bean实例化三种方式 无参构造实例化(重点) 工厂静态方法实例化 工厂实例方法实例化 工厂静态方法实例化 1.编写接口 package com.my; public interface UserDa ...
- Topic太多,RocketMQ炸了!
网上博客常说,kafka的topic数量过多会影响kafka,而RocketMQ不会受到topic数量影响. 但是,果真如此吗? 最近排查一个问题,发现RocketMQ稳定性同样受到topic数量影响 ...
- (转) [Android测试] AS+Appium+Java+Win自动化测试之三: 基础知识和Appium界面
一.把上一章的demo先看懂 AndroidContactsTest.Java public class AndroidContactsTest { //Driver private AppiumDr ...
- [python]格式化字符串的几种方式
目录 方式一:C风格%操作符 方式二:内置的format函数与str类的format方法 方式三:插值格式字符串 python中有以下几种方法可以格式化字符串 方式一:C风格%操作符 这种方法偏C语言 ...
- springboot项目图片不显示的问题
首先确认你的图片路径是对的,maven重新clean,install了,web服务也重启了 那么大概率就是浏览器缓存的原因,因为页面直接用的是缓存的旧数据,所以显示不出来. 在不修改浏览器设置的情况下 ...
- Linux cpu 亲缘性 绑核
前言 https://www.cnblogs.com/studywithallofyou/p/17435497.html https://www.cnblogs.com/studywithallofy ...
- SpringBoot项目统一处理返回值和异常
目录 简介 前期准备 统一封装报文 统一异常处理 自定义异常信息 简介 当使用SpringBoot开发Web项目的API时,为了与前端更好地通信,通常会约定好接口的响应格式.例如,以下是一个JSON格 ...
- 6、Spring之基于xml的自动装配
6.1.场景模拟 6.1.1.创建UserDao接口及实现类 package org.rain.spring.dao; /** * @author liaojy * @date 2023/8/5 - ...
- Go语言-Slice详解
Go语言中的slice表示一个具有相同类型元素的可变长序列,语言本身提供了两个操作方法: 创建:make([]T,len,cap) 追加: append(slice, T ...) 同时slice支持 ...