KL-Divergence KL散度
KL散度(KL-divergence)
直观解释:KL 散度是一种衡量两个分布(比如两条线)之间的匹配程度的方法。
需要解决的问题:已知数据太大,逍遥使用较小的信息表示已知数据。用某种已知分布来表示真实统计数据,这样我们就可以只发送该分布的参数,而无需发送真实统计数据。
KL-divergence的作用:衡量每个近似分布与真实分布之间匹配程度

其中 q(x) 是近似分布,p(x) 是我们想要用 q(x) 匹配的真实分布。直观地说,这衡量的是给定任意分布偏离真实分布的程度。如果两个分布完全匹配,那么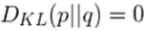 ,否则它的取值应该是在 0 到无穷大(inf)之间。KL 散度越小,真实分布与近似分布之间的匹配就越好。
,否则它的取值应该是在 0 到无穷大(inf)之间。KL 散度越小,真实分布与近似分布之间的匹配就越好。
KL-Divergence KL散度的更多相关文章
- python 3计算KL散度(KL Divergence)
KL DivergenceKL( Kullback–Leibler) Divergence中文译作KL散度,从信息论角度来讲,这个指标就是信息增益(Information Gain)或相对熵(Rela ...
- paper 23 :Kullback–Leibler divergence KL散度(2)
Kullback–Leibler divergence KL散度 In probability theory and information theory, the Kullback–Leibler ...
- 熵(Entropy),交叉熵(Cross-Entropy),KL-松散度(KL Divergence)
1.介绍: 当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练模型的时候就不停地调整参数使得我们预测出来的概率和真是的概率更加接近. 这篇文章我们关注在我们的模型假设这些类 ...
- [转]熵(Entropy),交叉熵(Cross-Entropy),KL-松散度(KL Divergence)
https://www.cnblogs.com/silent-stranger/p/7987708.html 1.介绍: 当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练 ...
- [学习笔记] Uplift Decision Tree With KL Divergence
Uplift Decision Tree With KL Divergence Intro Uplift model 我没找到一个合适的翻译,这方法主要应用是,探究用户在给予一定激励之后的表现,也就是 ...
- KL divergence
Kullback-Leibler divergence 形式: 性质: 非负 P=Q时,D[P||Q]=0 不对称性:D(P||Q)≠D(Q||P) 自信息:符合分布 P 的某一事件 x 出现,传达这 ...
- KL与JS散度学习[转载]
转自:https://www.jianshu.com/p/43318a3dc715?from=timeline&isappinstalled=0 https://blog.csdn.net/e ...
- [Bayes] KL Divergence & Evidence Lower Bound
L lower是什么? L lower, 既然大于,那么多出来的这部分是什么?如下推导: 得出了KL的概念,同时也自然地引出了latent variable q.
- 最大似然估计 (Maximum Likelihood Estimation), 交叉熵 (Cross Entropy) 与深度神经网络
最近在看深度学习的"花书" (也就是Ian Goodfellow那本了),第五章机器学习基础部分的解释很精华,对比PRML少了很多复杂的推理,比较适合闲暇的时候翻开看看.今天准备写 ...
- Laplace分布算子开发经验分享
摘要:Laplace 用于 Laplace 分布的概率统计与随机采样. 本文分享自华为云社区<Laplace分布算子开发经验分享>,作者:李长安. 1.任务解析 详细描述: Laplace ...
随机推荐
- spring cloud zuul实践
一. 描述 Spring Cloud Zuul是基于Netflix开源的Zuul项目构建而成,它作为微服务架构中的网关服务,主要用于实现动态路由.负载均衡和请求过滤等功能. 动态路由:Zuul根据预设 ...
- 河南省CCPC大学生程序设计竞赛赛后总结yy
这次的ccpc总体来说,取得的成绩并不理想,首先是题目解决的数量较少,其次是罚时太多了.开始也是找到了签到题,按理说应该不难拿下,虽然大家解决这道签到题都不是很快,但是我们小队在比赛已经过去两个小时左 ...
- idea连接数据库及使用
连接数据库 idea本身足够强大,可以直接操作数据库. 1.打开idea后,点击右侧的Database,点击加号,点击Data Source,在右侧选择需要的数据库,我这里选择mysql. 2.填写完 ...
- 今日ERROR
树莓派插卡发烫严重 首先,我们要知道: 树莓派的指示灯可以告诉用户系统的工作状态,常见的指示灯有四个,分别是红色电源灯.绿色SD卡读写灯.黄色ACT指示灯和蓝色网络连接指示灯(仅适用于某些型号的树莓派 ...
- docker安装8版本elasticsearch遇到的问题FileSystemException
docker安装8版本elasticsearch遇到的问题 Exception in thread "main" java.nio.file.FileSystemException ...
- Avalonia中用FluentAvalonia+DialogHost.Avalonia实现界面弹窗和对话框
Avalonia中用FluentAvalonia+DialogHost.Avalonia实现界面弹窗和对话框 本文是项目中关于 弹窗界面 设计的技术分享,通过 FluentAvalonia+Dialo ...
- LCD与OLED的相爱相杀
目前市面的显示技术主要分为LCD与OLED. 本文主要记录对LCD与OLED的学习. 导言:介绍一些专业名词和术语. 像素点:是指在由一个数字序列表示的图像中的一个最小单位,称为像素. 一张图片在显示 ...
- QPushButton按钮的使用
1 import sys 2 from PyQt5.QtCore import * 3 from PyQt5.QtGui import * 4 from PyQt5.QtWidgets import ...
- mysql-workbench-community报错解决办法
输入以下命令: sudo apt-get -f install 参考链接:https://www.jianshu.com/p/767c9a29b403
- mysql根据mysqlbinlog恢复找回被删除的数据库
年初和朋友一起做了个项目,到现在还没收到钱呢,今天中午时候突然听说之前的数据库被攻击了,业务数据库全部被删除.看有没有什么办法恢复,要是恢复不了,肯定也别想拿钱了吧? README FOR RECOV ...