Rethinking Point Cloud Registration as Masking and Reconstruction论文阅读
Rethinking Point Cloud Registration as Masking and Reconstruction
2023 ICCV
*Guangyan Chen, Meiling Wang, Li Yuan, Yi Yang, Yufeng Yue*; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 17717-17727
- paper: Rethinking Point Cloud Registration as Masking and Reconstruction (thecvf.com)
- code: CGuangyan-BIT/MRA (github.com)

这论文标题就很吸引人,但是研读下来作者只是想用MAE的结构,想要预测出对齐后点云,然后提高跨点云间配准点的特征描述一致性,辅助特征提取网络训练
Abstract
文章核心立题: the invisible parts of each point cloud can serve as inherent masks, whereas the aligned point cloud pair can be treated as the reconstruction objective .
- 将点云配准视为masking and Reconstruction过程,以Point-MAE为基本思想,提出MRA(the Masked Reconstrction Auxiliary Network)。
- MRA可以很容易的嵌入到其他方法中further improve registration accuracy
- 基于MRA,提出一个novel、基于standard transformer-baesed method,MRT(the Masked Reconstruction Transformer)。
encode feauters -> inference the contextual features and overall structures of point cloud pairs -> the deviation correction modul to correct the spatial deviations in the putative corresponding point pairs
Description
- input:
- source point cloud \(X = \{x_1, x_2, …,x_M\} \subseteq \mathbb{R}^3\)
- target point cloud \(Y = \{y_1, y_2, …, y_N\} \subseteq \mathbb{R}^3\)
- output: the rigid transformation \(\{\hat{R} \in SO(3), \hat{t} \in \mathbb{R}^3\}\) that align the source point cloud with the target point cloud.
(MRT是用来提特征的,应该也是dense description,MRA是用来辅助训练MRT的。)

- MRT step: input point cloud pair \(X\) , \(Y\) 利用KPConv进行dense description,得到superpoints \([\widetilde{X}:F^{\widetilde{X}}]\) , \([\widetilde{Y}:F^{\widetilde{Y}}]\) 。然后其中的特征描述 \(F\) 经过Transformer Encoder Module提取contextual information and overall structure 重构每个特征描述 \(F^{\widetilde{X}}\) , \(F^{\widetilde{Y}}\) 。
- auxiliary network step:two module is parallel used to training MRT
- MRA: the MRA separately receives the encoded features of each point cloud and predicts the other aligned point cloud, reconstructing the complete point cloud.
- Registration network: predict point corrrespondences \(\hat{y},\ \hat{x}\) and overlap scores \(\hat{o}^{\widetilde{X}},\ \hat{o}^{\widetilde{Y}}\) in the Deviation Correction module, then use Wighted Procrustes module to regress the transformaion.
MRT Step
- KPConv network:
- input downsampled point clouds: \(X \in \mathbb{M \times 3}\), \(Y \in \mathbb{N \times 3}\)
- obtain superpoints and features: \([\widetilde{X} \in \mathbb{M^{'} \times 3}:F^{\widetilde{X}}\in \mathbb{R}^{M^{'} \times D}]\) , \([\widetilde{Y} \in \mathbb{M^{'} \times 3}:F^{\widetilde{Y}}\in \mathbb{R}^{N^{'} \times D}]\)
- Transformer Encoder:
- input superpoints and features into \(L_e\) - layer transformer encoder( cross-attention and sinusoidal positional encodings )
- output the encoded features \(\mathcal{F}^{\widetilde{X}}\) , \(\mathcal{F}^{\widetilde{Y}}\) .
cross-attention有助于两个point cloud提取一致性特征。
MRA Step

一个纯MAE style的网络结构, mask token 代表对齐后相应的point cloud patch表示。输入对齐前的point cloud patch,相应的token,根据GT rigid transformation信息生成的position embedding,和mask token,输出预测的对齐后point cloud patch,再与GT 生成的对齐结果做chamfer Loss。
虽然表面上这里有很多与变换相关的操作,但是细细思考会发现这里所有的变换信息都建立在GT上,所以我倾向于这里与MRT里的cross-attention一起提高了配准点对在特征上的表示一致性,当然肯定对特征表示的语义完整性有提高。
- input -> MRT outputs: super points pair and corresponding features: \([\widetilde{X} \in \mathbb{M^{'} \times 3}:\mathcal{F}^{\widetilde{X}}\in \mathbb{R}^{M^{'} \times D}]\) , \([\widetilde{Y} \in \mathbb{M^{'} \times 3}:\mathcal{F}^{\widetilde{Y}}\in \mathbb{R}^{N^{'} \times D}]\) 。
- output: chamfer L2 loss between predicted aligned point cloud patch and ground truth aligned point cloud.
步骤:
- use FPS to extract center points \(\widetilde{X}_c\) , \(\widetilde{Y}_c\) in super points. use KNN to generate point cloud patch; get the tokens \(T^{\widetilde{X}}\) , \(T^{\widetilde{Y}}\) by composing the encoded features \(\mathcal{F}^{\widetilde{X}}\) , \(\mathcal{F}^{\widetilde{Y}}\) .use mask token \(T^{\widetilde{X}}_m ∈ \mathbb{R}^{g×D}\), \(T^{\widetilde{Y}}_m ∈ \mathbb{R}^{g×D}\) to correspond the aligned point cloud patch in the output of decoder.
- use groud truth transformation from \(Y\) to \(X\), and from \(X\) to \(Y\) to generate the position embedding for each layer in decoder.
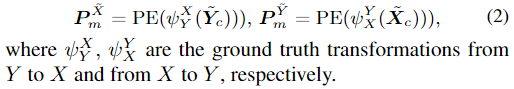
- self-attention and two-layer-FC transfromer decoder to reconstruct the mask token to represent the token of aligned point cloud patch.
- use two-layer MLP with two FC and ReLu to predict the aligned point cloud patch responding to the decoded mask tokens.
- chamfer loss: the ground truch aligned point cloud patch and the predicted one.

coarse registration step
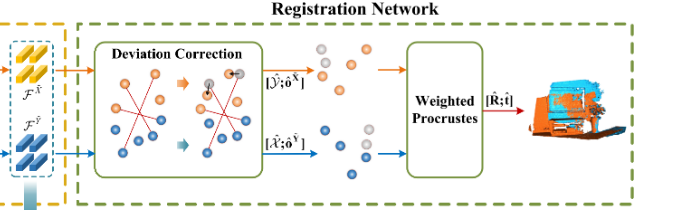
由于MRT提取的特征强聚合(cross-attention的缘故)了跨点云间的语义信息,根据余弦相似性计算soft corresponding wighted,加权求和得到correspodence point pair,在拼接特征以及对应点对的坐标用MLP拟合加权求和得到的点对坐标与真实位置的偏差。构筑更鲁棒的匹配结果。(这种预测bias的方式经常见)。之后使用weighted procustes模块预测rigid transformaion。
我更想倾向于这样描述:单纯加权求和得到的坐标结果大概率与真实坐标有所偏差,引入另一个可变分量来对加权后的预测结果做调控,能够使得预测结果更加鲁棒,更加稳定,甚至能更加精确,从而在现象上,显示为偏差值。并且这里的余弦相似性从一定程度上可以提高非配准点之前的差异性。
- input: the feature \(\mathcal{F}^{\widetilde{X}}\) , \(\mathcal{F}^{\widetilde{Y}}\) extracted by MRT
- output: predicted rigid transformation: \([\hat{R}; \hat{t}]\)
步骤:
- predicted the corresponding points \(\mathcal{Y}\) for each super point \(\widetilde{X}\) :

- use features and MLP predict the deviations which needs to add to the predicted corresponding points:

- predict the overlap scores for each point. which indicatee probabilities of ponts lying in the overlap regions:

- use the wighted procrustes to predict the rigid transformation and compute the loss with GT.
Experiment
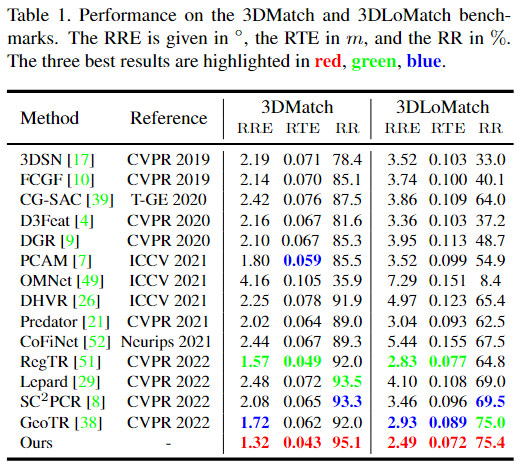
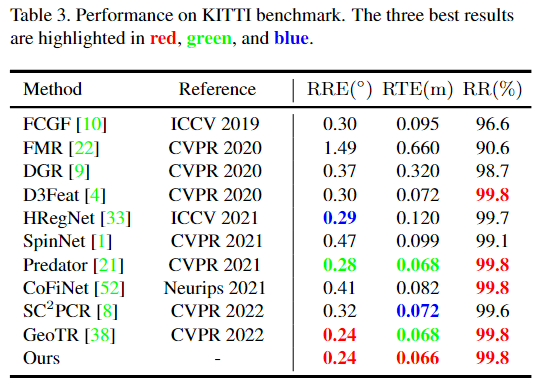
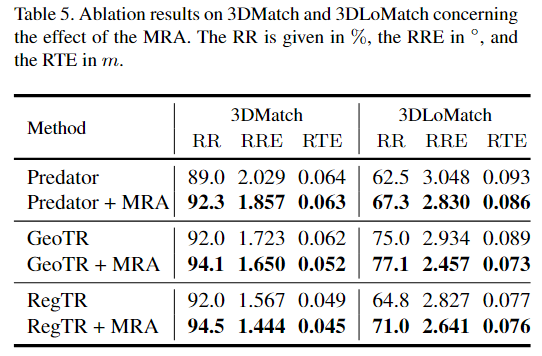
MRA的plug-and play,确实可以:
Rethinking Point Cloud Registration as Masking and Reconstruction论文阅读的更多相关文章
- cloud theory is a failure? 分类: Cloud Computing 2013-12-26 06:52 269人阅读 评论(0) 收藏
since LTE came out, with thin client cloud computing and broadband communication clouding 不攻自破了.but ...
- 论文阅读:Andromeda: Performance, Isolation, and Velocity at Scale in Cloud Network Virtualization (全文翻译用于资料整理和做PPT版本,之后会修改删除)
Abstract: This paper presents our design and experience with Andromeda, Google Cloud Platform’s net ...
- 论文阅读笔记十一:Rethinking Atrous Convolution for Semantic Image Segmentation(DeepLabv3)(CVPR2017)
论文链接:https://blog.csdn.net/qq_34889607/article/details/8053642 摘要 该文重新窥探空洞卷积的神秘,在语义分割领域,空洞卷积是调整卷积核感受 ...
- 全链路实践Spring Cloud 微服务架构
Spring Cloud 微服务架构全链路实践Spring Cloud 微服务架构全链路实践 阅读目录: 网关请求流程 Eureka 服务治理 Config 配置中心 Hystrix 监控 服务调用链 ...
- Spring Cloud配置中心内容加密
从配置获取的配置默认是明文的,有些像数据源这样的配置需要加密的话,需要对配置中心进行加密处理. 下面使用对称性加密来加密配置,需要配置一个密钥,当然也可以使用RSA非对称性加密,但对称加密比较方便也够 ...
- Spring Cloud Gateway的断路器(CircuitBreaker)功能
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》
论文信息 论文标题:Rethinking the Setting of Semi-supervised Learning on Graphs论文作者:Ziang Li, Ming Ding, Weik ...
- 论文解读(NWR)《Graph Auto-Encoder via Neighborhood Wasserstein Reconstruction》
论文信息 论文标题:Graph Auto-Encoder via Neighborhood Wasserstein Reconstruction论文作者:Shaked Brody, Uri Alon, ...
- ICCV 2017论文分析(文本分析)标题词频分析 这算不算大数据 第一步:数据清洗(删除作者和无用的页码)
IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017. IEE ...
- CVPR 2020 全部论文 分类汇总和打包下载
CVPR 2020 共收录 1470篇文章,根据当前的公布情况,人工智能学社整理了以下约100篇,分享给读者. 代码开源情况:详见每篇注释,当前共15篇开源.(持续更新中,可关注了解). 算法主要领域 ...
随机推荐
- P3133 [USACO16JAN] Radio Contact G 无线电通话
P3133 [USACO16JAN] Radio Contact G 无线电通话 目录 P3133 [USACO16JAN] Radio Contact G 无线电通话 [USACO16JAN] Ra ...
- AcWing 4495. 数组操作题解
思路 此题较为简单,简述一下思路. 从小到大排序,每次选取最小值,只要不为0即可 每次都为序列减去一个数字太慢,但每个数又减去的数字一样,所以可以用minus记录每个数要减去的数 C++代码 #inc ...
- Tauri-Admin通用后台管理系统|tauri+vue3+pinia桌面端后台EXE
基于tauri+vite4+pinia2跨端后台管理系统应用实例TauriAdmin. tauri-admin 基于最新跨端技术 Tauri Rust webview2 整合 Vite4 构建桌面端通 ...
- 2021-3-9 excel导出
public void ExportExcel(DataTable dt) { //要添加epplus的nuget包 ExcelPackage.LicenseContext = LicenseCont ...
- 浅谈php伪协议的运用
浅谈php伪协议的运用 (133条消息) PHP Filter伪协议Trick总结_php伪协议rot13的用法_swtre33的博客-CSDN博客 php死亡exit()绕过 - xiaolong' ...
- Spring Boot Starter 剖析与实践
引言 对于 Java 开发人员来说,Spring 框架几乎是必不可少的.它是一个广泛用于开发企业应用程序的开源轻量级框架.近几年,Spring Boot 在传统 Spring 框架的基础上应运而生,不 ...
- Unity的BuildPlayerProcessor:深入解析与实用案例
Unity BuildPlayerProcessor Unity BuildPlayerProcessor是Unity引擎中的一个非常有用的功能,它可以让开发者在构建项目时自动执行一些操作.这个功能可 ...
- Nginx快速入门:简介、安装、配置
Nginx概述 与 Apache 软件类似,Nginx ("engine x")是一个开源的.支持高性能.高并发的web服务和代理服务软件.它是由俄罗斯人 Igor Sysoev ...
- C++火车头优化
代码如下(加在头文件前): 1 #pragma GCC optimize(3) 2 #pragma GCC target("avx") 3 #pragma GCC optimize ...
- 【pandas小技巧】--日期相关处理
日期处理相关内容之前pandas基础系列中有一篇专门介绍过,本篇补充两个常用的技巧. 1. 多列合并为日期 当收集来的数据中,年月日等信息分散在多个列时,往往需要先合并成日期类型,然后才能做分析处理. ...