Chromium Command Buffer原理解析
Command Buffer 是支撑 Chromium 多进程硬件加速渲染的核心技术之一。它基于 OpenGLES2.0 定义了一套序列化协议,这套协议规定了所有 OpenGLES2.0 命令的序列化格式,使得应用对 OpenGL 的调用可以被缓存并传输到其他的进程中去执行(GPU进程),从而实现多个进程配合的渲染机制。
1. Command Buffer 命令的序列化
在 CommandBuffer 中共有三类命令,一类是直接对接OpenGLES的命令。例如下面的GL命令:

他们的序列化格式定义为:

可以看到序列化的方式并不复杂,每个命令都有个 CommandId 和 header。header 占用 32 位,高 21 位表示当前命令的长度,低 11 位表示命令的 Id。其他字段表示命令的参数。
第二类命令是 CommandBuffer 自己需要用到的,这类命令称为公共命令(common command,Id<256),比如下面这两个:

这两个命令一个用于创建Bucket,一个用于向Bucket中放数据(关于Bucket后面会讲到)。他们都不是 OpenGL 定义的命令,是 CommandBuffer 为了自己的某种用途而添加的命令。
最后一种命令如下:
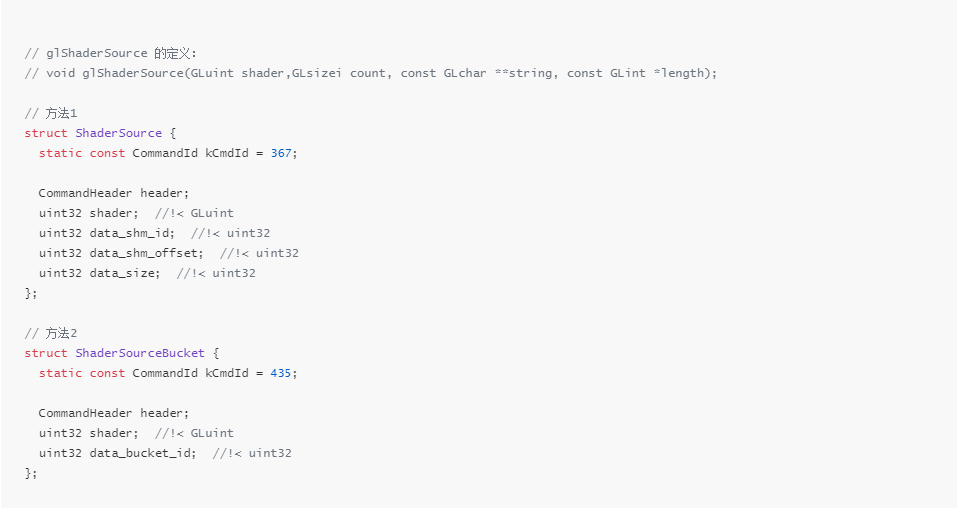
可以看到 CommandBuffer 针对 glShaderSource 命令定义了不同的序列化格式,没有一种是按照原本的参数来定义的,这主要是因为 glShaderSource 命令可能会传输比较大的数据(第3个参数),如果直接把数据通过 IPC 传输可能会比较低效,因此方法1将数据存放在了共享内存,然后在命令中保留了对共享内存的引用,方法2是将数据保存在 Bucket,然后在命令中引用了 Bucket。这种处理方式主要是针对那些需要传输大批量数据的GL命令。
2. Command Buffer 命令的自动生成
Command Buffer 提供了三种 GL Context,分别时 GLES Context,Raster Context,WebGPU Context,它们用于不同的目的。GLES Context 用于常规的绘制,Raster Context 用于 Raster,WebGPU Context 用于 WebGPU。
在 gpu/command_buffer/gles2_cmd_buffer_functions.txt 文件中定义了 GLES Context 使用到的 GL 命令,包括 150 多个 OpenGLES2.0 命令,以及由 19 个扩展提供的 230 多个扩展命令,在编译过程中 gpu/command_buffer/build_gles2_cmd_buffer.py 脚本会读取该文件并生成相应的 *_autogen.* 文件。
在 gpu/command_buffer/raster_cmd_buffer_functions.txt 文件中定义了 Raster Context 使用到的 30 多个 GL 命令,它被 gpu/command_buffer/build_raster_cmd_buffer.py 脚本使用来生成相应的 *_autogen.* 文件。
用于 WebGPU Context 的命令定义在 gpu/command_buffer/webgpu_cmd_buffer_functions.txt 中,被脚本 gpu/command_buffer/build_webgpu_cmd_buffer.py 用来生成相关代码。
Command Buffer 通过这些自动生成的代码包装了所有的 GL 调用,然后将这些调用序列化后发送到 GPU 进程去执行。
3. Command Buffer 的架构设计
前面已经提到,Command Buffer 主要是为了解决多进程的渲染问题,因此它在设计上分两个端,分别是 client 端和 service 端。下图反映了 Chromium 中各种进程和 Command Buffer 中两个端的对应关系:
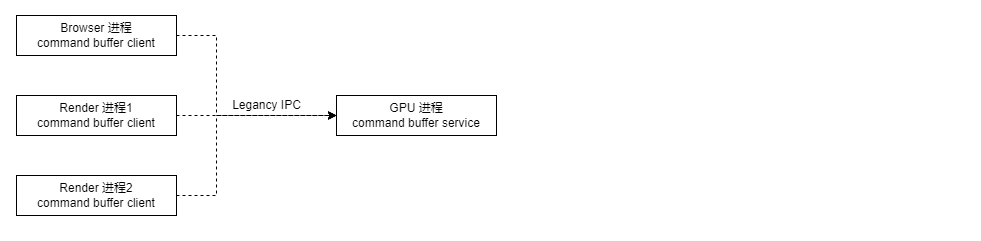
可以看到,Browser和Render进程都是 client 端, GPU 进程是 service 端。client 端负责调用 GL 命令来产生绘制操作,但是这些GL命令并不会真正执行而是被序列化为 Command Buffer 命令,然后通过 IPC 传输到 GPU 进程,GPU 进程负责反序列化 Command Buffer 命令并最终执行 GL 调用。
在 Chromium 的实现中,引入了更多的概念:
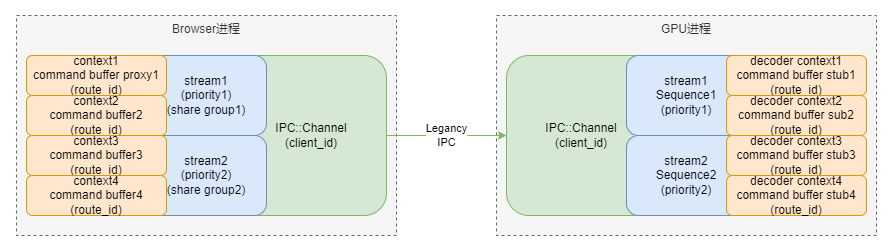
- 每个client端和server端之间都通过
IPC channel (IPC::Channel) 通道进行连接。 - 每个 IPC channel 可以有多个
调度组(scheduling groups),每个调度组称为一个stream,每个 stream 有自己的调度优先级。 - 每个 stream 可以承载多个
command buffer。 - 每个 command buffer 都对应一个 GL context,在相同stream中的GL Context都属于同一个
share group。 - 每个 command buffer 都包含一系列的 GL 命令。
下图反映了 context,commandbuffer,stream,channel 之间的关系:
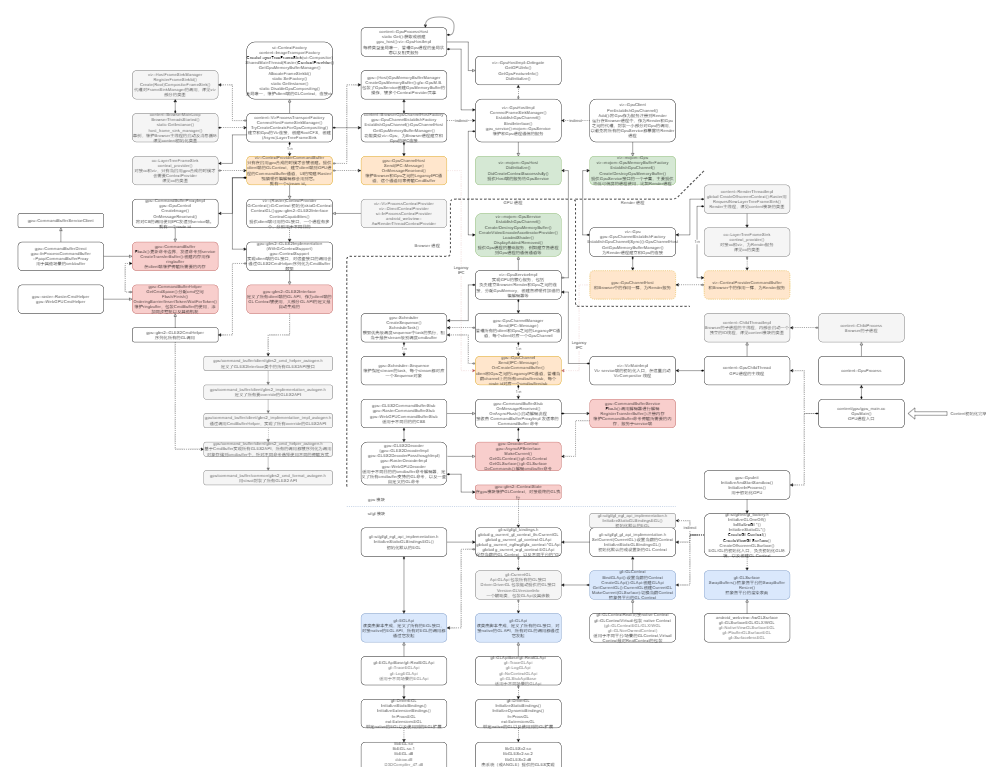
下面是 Command Buffer 的模块依赖关系:

content 模块通过调用 GL 或者 Skia 来产生 GL 命令, 然后 Command Buffer client 将这些 GL 命令序列化,然后通过 IPC 传输到了 Command Buffer service 端,service 将命令反序列化然后调用 ui/gl 模块执行真正的 GL 调用。
4. Command Buffer 命令的传输方式
Command Buffer 定义了三种命令传输方式:
- 命令和命令涉及到的数据都直接放在 Command Buffer 中传输,在多进程模式下 Command Buffer 本身位于共享内存中;
- 命令放在 Command Buffer 中,数据放在共享内存中,在命令中引用该共享内存;
- 先使用
SetBucketSize命令在 service 进程中创建一个足够大的Bucket,然后将数据的一部分放在共享内存中,然后使用SetBucketData命令将该共享内存中的数据放到 service 进程的 Bucket 中,然后再放一部分数据到共享内存,再使用SetBucketData命令将数据传输到 service 进程中,循环这个操作直到将所有的数据都放到 service 进程中,最后调用原本的 GL 命令并引用这个 Bucket 的 Id 。Bucket 机制主要用在共享内存不足以存放所有要传输的数据的时候。由于涉及到多次数据从共享内存拷贝到进程空间的操作,因此性能较低。
5. Command Buffer 的具体实现
6. 总结
Command Buffer 可以用于实现多进程的渲染架构,并且提供全平台支持。可以通过设置 is_component_build=true 来将 Command Buffer 模块编译为动态链接库,从而嵌入到自己的项目中。例如,Skia 项目就提供了对 Command Buffer 的。
7. 参考文献

Chromium Command Buffer原理解析的更多相关文章
- [原][Docker]特性与原理解析
Docker特性与原理解析 文章假设你已经熟悉了Docker的基本命令和基本知识 首先看看Docker提供了哪些特性: 交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上, ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- ThreadLocal系列(三)-TransmittableThreadLocal的使用及原理解析
ThreadLocal系列(三)-TransmittableThreadLocal的使用及原理解析 上一篇:ThreadLocal系列(二)-InheritableThreadLocal的使用及原理解 ...
- GPU Command Buffer
For Developers > Design Documents > GPU Command Buffer This are mostly just notes on the ...
- 【Node.js】 bodyparser实现原理解析
为什么我们需要body-parser 也许你第一次和bodyparser相遇是在使用Koa框架的时候.当我们尝试从一个浏览器发来的POST请求中取得请求报文实体的时候,这个时候,我们想,这个从Koa自 ...
- Python 中 -m 的典型用法、原理解析与发展演变
在命令行中使用 Python 时,它可以接收大约 20 个选项(option),语法格式如下: python [-bBdEhiIOqsSuvVWx?] [-c command | -m module- ...
- java线程池原理解析
五一假期大雄看了一本<java并发编程艺术>,了解了线程池的基本工作流程,竟然发现线程池工作原理和互联网公司运作模式十分相似. 线程池处理流程 原理解析 互联网公司与线程池的关系 这里用一 ...
- jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一)
jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一) 线程池介绍 在日常开发中经常会遇到需要使用其它线程将大量任务异步处理的场景(异步化以及提升系统的吞吐量),而在 ...
- jdk线程池ThreadPoolExecutor优雅停止原理解析(自己动手实现线程池)(二)
jdk线程池工作原理解析(二) 本篇博客是jdk线程池ThreadPoolExecutor工作原理解析系列博客的第二篇,在第一篇博客中从源码层面分析了ThreadPoolExecutor在RUNNIN ...
- jdk调度任务线程池ScheduledThreadPoolExecutor工作原理解析
jdk调度任务线程池ScheduledThreadPoolExecutor工作原理解析 在日常开发中存在着调度延时任务.定时任务的需求,而jdk中提供了两种基于内存的任务调度工具,即相对早期的java ...
随机推荐
- 【从0开始编写webserver·基础篇#03】TinyWeb源码阅读,还是得看看靠谱的项目
[前言] 之前通过看书.看视频和博客拼凑了一个webserver,然后有一段时间没有继续整这个项目 现在在去看之前的代码,真的是相当之简陋,而且代码设计得很混乱,我认为没有必要继续在屎堆上修改了,于是 ...
- 聊一聊Java中的Steam流
1 引言 在我们的日常编程任务中,对于集合的制造和处理是必不可少的.当我们需要对于集合进行分组或查找的操作时,需要用迭代器对于集合进行操作,而当我们需要处理的数据量很大的时候,为了提高性能,就需要使用 ...
- .NetCore3.1+微服务架构技术栈
目标 目标系统架构演变,单体-分布式-微服务-中台 微服务架构核心解决,横向对比1.0.2.0.3.0 践行微服务架构,全组件解读! 也谈中台 单体架构Monolithic 单体应用时代:应用程序就是 ...
- 音视频开发进阶——YUV与RGB的采样与存储格式
在上一篇文章中,我们带大家了解了视频.图像.像素和色彩之间的关系,还初步认识了两种常用的色彩空间,分别是大家比较熟悉的 RGB,以及更受视频领域青睐的 YUV.今天,我们将继续深入学习 RGB.YUV ...
- 如何使用C#中的Lambda表达式操作Redis Hash结构,简化缓存中对象属性的读写操作
Redis是一个开源的.高性能的.基于内存的键值数据库,它支持多种数据结构,如字符串.列表.集合.散列.有序集合等.其中,Redis的散列(Hash)结构是一个常用的结构,今天跟大家分享一个我的日常操 ...
- Mybatis(Map)
Map 假设,我们的实体类,或者数据库中的表,字段或参数过多,我们应当考虑使用map 创建接口 //万能的mapper,我们不需要知道数据库里面有什么,是一个键值对的表现 //我们只需查询对应的字段 ...
- python(django启动报错,之编码问题)UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb2 in position 0: invalid start byte
- 【Spring】@RequestBody的实现原理
@RequestBody注解可以用于POST请求接收请求体中的参数,使用方式如下: @Controller public class IndexController { @PostMapping(va ...
- Ubutnu 20.04 安装和使用单机版hadoop 3.2 [转载]
按照此文档操作,可以一次部署成功:Ubutnu 20.04 安装和使用单机版hadoop 3.2 部署之后,提交测试任务报资源问题.原因是yarn还需要配置,如下: $ cat yarn-site.x ...
- pandas 显示所有的行和列
import pandas as pd # 显示所有列,所有行 pd.set_option('display.max_columns', None) pd.set_option('display.ma ...