架构解读丨Volcano作业资源预留设计原理
摘要:本文重点讲解了基于v1.1.0的目标作业资源预留特性的设计和最佳实践。讲解过程中,全面介绍了特性设计过程中的考量因素和算法设计。
资源预留(Reservation)是批处理系统的一类常见需求,也是公平性调度(Fair Scheduling)的补充。从不同维度来看,资源预留可以分为抢占式预留和非抢占式预留、作业资源预留和队列资源预留、即时预留和预见性预留等。自v1.1.0开始,Volcano开始迭代支持资源预留特性。根据社区Roadmap,v1.1.0(已发布)优先支持作业资源预留,v1.2.0将支持指定队列资源预留。
场景分析
在实际应用中,常见以下两种场景:
(1)在集群资源不足的情况下,假设处于待调度状态的作业A和B,A资源申请量小于B或A优先级高于B。基于默认调度策略,A将优先于B进行调度。在最坏的情况下,若后续持续有高优先级或申请资源量较少的作业加入待调度队列,B将长时间处于饥饿状态并永远等待下去。
(2)在集群资源不足的情况下,假设存在待调度作业A和B。A优先级低于B但资源申请量小于B。在基于集群吞吐量和资源利用率为核心的调度策略下,A将优先被调度。在最坏的情况下,B将持续饥饿下去。
以上两种场景出现的根因是缺少一种公平调度机制:保证长期处于饥饿状态的作业在达到某个临界条件后被优先调度。造成作业持久饥饿的原因很多,包括资源申请量长时间无法满足、优先级持续过低、抢占发生频率过高、亲和性无法满足(v1.1.0暂不支持此场景)等,以资源申请量无法满足最为常见。
特性设计
为了保证长期处于阻塞状态的作业能够拥有公平的调度机会,需要解决两个主要问题:
- 如何识别目标作业?
- 如何为目标作业预留资源?
1、目标作业识别
- 作业条件
作业条件的选定可以基于等待时间、资源申请量等单个维度或多个维度的组合。综合考虑,v1.1.0实现版本选择优先级最高且等待时间最长的作业作为目标作业。这样不仅可以保证紧急任务优先被调度,等待时间长度的考虑默认筛选出了资源需求较多的作业。
- 作业数量
客观来说,满足条件的作业通常不止一个,可以为目标作业组或单个目标作业预留资源。考虑到资源预留必然引起调度器性能在吞吐量和延时等方面的影响,v1.1.0采用了单个目标作业的方式。
- 识别方式
识别方式有两种:自定义配置和自动识别。v1.1.0暂时仅支持自动识别方式,即调度器在每个调度周期自动识别符合条件和数量的目标作业,并为其预留资源。后续版本将考虑在全局和Queue粒度支持自定义配置。
2、资源预留算法
资源预留算法是整个特性的核心。v1.1.0采用节点组锁定的方式为目标作业预留资源,即选定一组符合某些约束条件的节点纳入节点组,节点组内的节点从纳入时刻起不再接受新作业投递,节点规格总和满足目标作业要求。需要强调的是,目标作业将可以在整个集群中进行调度,非目标作业仅可使用节点组外的节点进行调度。
- 节点选取
在特性设计阶段,社区考虑过以下节点选取算法:规格优先、空闲优先。
规格优先是指集群中所有节点按照主要规格(目标作业申请资源规格)进行降序排序,选取前N个节点纳入节点组,这N个节点的资源总量满足申请量。这种方式的优点是实现简单、锁定节点数量最小化、对目标作业的调度友好(这种方式锁定的资源总量往往比申请总量大一些,且作业中各Pod容易聚集调度在锁定节点,有利于Pod间通信等);缺点是锁定资源总量大概率不是最优解、综合调度性能损失(吞吐量、调度时长)、易产生大资源碎片。v1.1.0的实现采用的是该算法。
空闲优先是指集群中所有节点按照主要资源类型(目标作业申请资源类型)的空闲资源量进行降序排序,选取前N个节点纳入节点组,这N个节点的资源总量满足申请量。这种方式的优点是较大概率最快腾出满足要求的资源总量;缺点是集群空闲资源分布的强动态性导致节点组不是最优解,所求解稳定性差。
- 节点数量
为了尽可能减少锁定操作对调度器综合性能的影响,在满足预留资源申请量的前提下,无论采用哪种节点选取算法,都应保证所选节点数最少。
- 锁定方式
锁定方式包括两个核心考量点:并行锁定数量、锁定节点已有负载处理手段。
并行锁定数量有三个选择:单节点锁定、多节点锁定、集群锁定。单节点锁定是指每个调度周期内基于当前集群资源分布选定一个符合要求的节点纳入节点组。这种方式可以尽量减少资源分布波动对所求解的稳定性的影响,缺点是要经过较多的调度周期才能完成锁定过程。v1.1.0的实现选择的是这种方式。以此类推,多节点锁定是指每个调度周期内选定X(X>1)个满足条件的节点进行锁定。这种方式能一定程度上弥补单节点锁定引入的锁定时长过长问题,缺点是X不易找到最优值,实现复杂度高。集群锁定是指一次性锁定集群所有节点,直至目标作业完成调度。这种粗暴的方式实现最为简单,目标作业等待时间最短,非常适合超大目标作业的资源预留。
锁定节点已有负载的处理手段有两种:抢占式预留、非抢占式预留。顾名思义,抢占式预留将会强制驱逐锁定节点上的已有负载。这种方式可以保证最快腾出所需的资源申请量,但会对已有业务造成重大影响,因此仅适用于紧急任务的资源预留。非抢占式预留则在节点锁定后不做任何处理,等待运行在其上的负载自行结束。v1.1.0采用的是非抢占式预留。
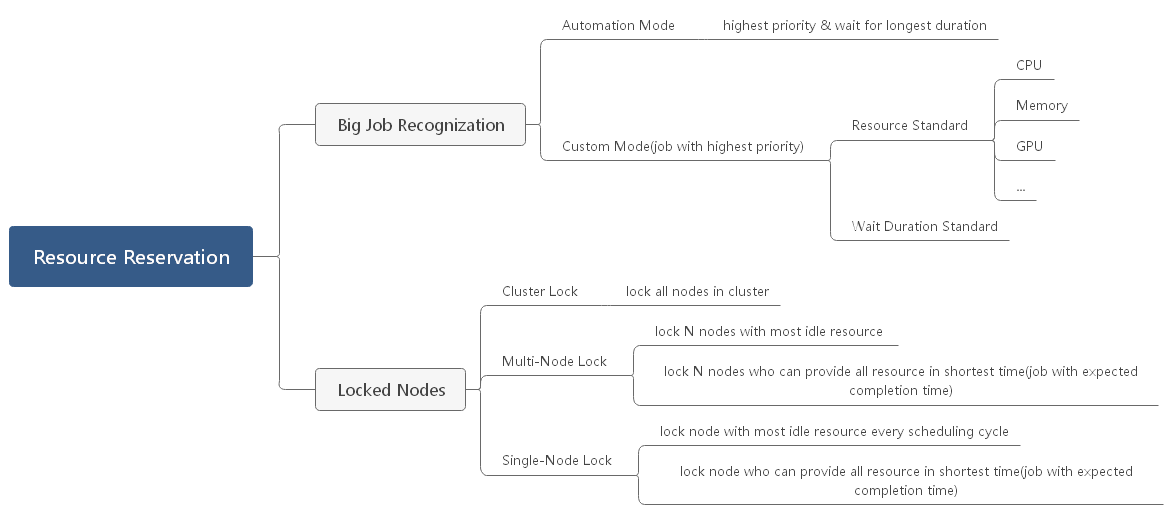
图1 作业资源预留设计
最佳实践
基于v1.1.0的实现,社区当前仅支持目标作业的自动化识别与资源预留。为此,新引入了2个action和1个plugin。elect action用于选取目标作业;reserve action用于执行资源预留动作;reservation plugin中实现了具体的目标选取和资源预留逻辑。
若要开启资源预留特性,将以上action和plugin配置到volcano的配置文件中即可。下面是推荐配置样例:
``` yaml
actions: "enqueue, elect, allocate, backfill, reserve"
tiers:
- plugins:
- name: priority
- name: gang
- name: conformance
- name: reservation
- plugins:
- name: drf
- name: predicates
- name: proportion
- name: nodeorder
- name: binpack
```
自行配置时,请注意以下事项:
- elect action必须配置在enqueue action和allocate action之间
- reserve action必须配置在allocate action之后
由于目标作业的识别、选取、资源预留都是自动化完成,整个过程在用户侧完全透明,可通过scheduler日志查看到整个过程。
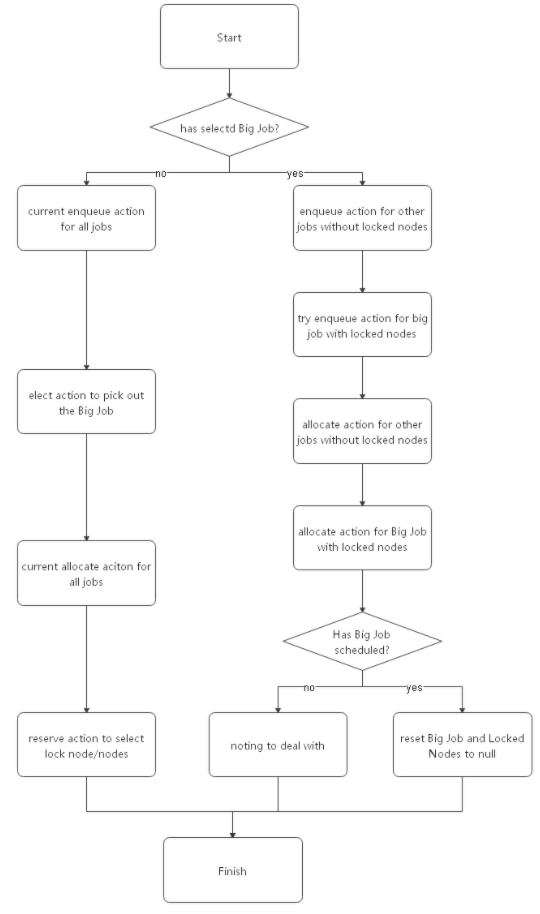
图2 作业资源预留流程图
总结展望
本文重点讲解了基于v1.1.0的目标作业资源预留特性的设计和最佳实践。讲解过程中,全面介绍了特性设计过程中的考量因素和算法设计。资源预留的细分场景很多,无法一一枚举。社区后续版本将持续聚焦共性预留需求,完善主要场景下资源预留特性,保证调度公平性。
本文分享自华为云社区《Volcano作业资源预留设计原理解读》,原文作者:技术火炬手。
架构解读丨Volcano作业资源预留设计原理的更多相关文章
- RESTful API 架构解读
RESTful API 架构解读 首先我们还是先介绍下 RESTful api 的来龙去脉. 首先, RESTful (下文都简称 RESTful api 为 RESTful ) 1.RESTful ...
- SpringMVC 原理 - 设计原理、启动过程、请求处理详细解读
SpringMVC 原理 - 设计原理.启动过程.请求处理详细解读 目录 一. 设计原理 二. 启动过程 三. 请求处理 一. 设计原理 Servlet 规范 SpringMVC 是基于 Servle ...
- kubernets资源预留
一. Kubelet Node Allocatable Kubelet Node Allocatable用来为Kube组件和System进程预留资源,从而保证当节点出现满负荷时也能保证Kube和Sy ...
- Kubelet资源预留
目录 Kubelet Node Allocatable 配置参数 配置示例 Kubelet Node Allocatable Kubelet Node Allocatable用来为Kube组件和Sys ...
- Atitit。Time base gc 垃圾 资源 收集的原理与设计
Atitit.Time base gc 垃圾 资源 收集的原理与设计 1. MRC(MannulReference Counting手动 retain/release/autorelease语句1 2 ...
- Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
一.设计原理 1.Hadoop架构: 流水线(PipeLine) 2.Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS 3.Hadoop架构: 关于Recovery (Lease ...
- ASP.NET Core搭建多层网站架构【4-工作单元和仓储设计】
2020/01/28, ASP.NET Core 3.1, VS2019, Microsoft.EntityFrameworkCore.Relational 3.1.1 摘要:基于ASP.NET Co ...
- Kubernetes实践技巧:资源预留
ubernetes 的节点可以按照节点的资源容量进行调度,默认情况下 Pod 能够使用节点全部可用容量.这样就会造成一个问题,因为节点自己通常运行了不少驱动 OS 和 Kubernetes 的系统守护 ...
- .Net Core后端架构实战【1-项目分层框架设计】
摘要:基于.NET Core 7.0WebApi后端架构实战[1-项目结构分层设计] 2023/02/05, ASP.NET Core 7.0, VS2022 引言 从实习到现在回想自己已经入行四年 ...
- 架构的生态系 资讯环境被如何设计至今.PDF
书本详情 架构的生态系 资讯环境被如何设计至今 作者: 濱野智史出版社: 大鴻藝術股份有限公司副标题: 資訊環境被如何設計至今?原作名: アーキテクチャの生態系――情報環境はいかに設計されてきたか译者 ...
随机推荐
- android的listview控件,加了行内按钮事件导致行点击失效的问题
近日,修改一个app,原来的listview中只有行点击事件 ListView.setOnItemClickListener(new AdapterView.OnItemClickListener() ...
- Maximum Diameter 题解
Maximum Diameter 题目大意 定义长度为 \(n\) 的序列 \(a\) 的权值为: 所有的 \(n\) 个点的第 \(i\) 个点的度数为 \(a_i\) 的树的直径最大值,如果不存在 ...
- React框架的基本运行原理与组件定义方式
React框架的基本运行原理 React的本质是内部维护了一套虚拟DOM树,这个虚拟DOM树就是一棵js对象树,它和真实DOM树是一致的,一一对应的. 当某一个组件的state发生修改时,就会生成一个 ...
- js数据结构--字典
<!DOCTYPE html> <html> <head> <title></title> </head> <body&g ...
- Go 包操作之如何拉取私有的Go Module
Go 包操作之如何拉取私有的Go Module 在前面,我们已经了解了GO 项目依赖包管理与Go Module常规操作,Go Module 构建模式已经成为了 Go 语言的依赖管理与构建的标准. 在平 ...
- Kubernetes:kube-apiserver 之启动流程(一)
0. 前言 前面两篇文章 Kubernetes:kube-apiserver 之 scheme(一) 和 Kubernetes:kube-apiserver 之 scheme(二) 重点介绍了 kub ...
- docker的疑难杂症
本篇博客主要是解决docker使用中遇到的常见报错,为了下次能够快速解决同样的问题,专门记录一下,文章会持续更新. 容器名称被占用. Error response from daemon: Confl ...
- rt-thread Env 预处理配置方法
简介 rt-thread 是我非常喜欢的一款RTOS,近期在使用Env更新工程的时候发现,keil MDK 中的预处理型号和器件型号不符. 这就导致我每次更新工程后都需要进入keil MDK手动修改一 ...
- Basic concepts of complex number
目录 虚数的引入 复数和虚数的关系 Example - 分辨一个数 判断两个复数是否相等的条件 共轭复数 复数的几何意义.复平面的认识 求复数的模 Reference 虚数的引入 假设有一个数,可以叫 ...
- Linux配置静态IP解决无法访问网络问题
Linux系统安装成功之后只是单机无网络状态,我们需要配置Linux静态IP来确保服务器可以正常连接互联网 1.首先安装ifconfig Centos7安装成功后,高版本会把ping命令给移除了,所以 ...