看FusionInsight Spark如何支持JDBCServer的多实例特性
摘要:采用多主实例模式的HA方案,不仅可以规避主备切换服务中断的问题,实现服务不中断或少中断,还可以通过横向扩展集群来提高并发能力。
本文分享自华为云社区《FusionInsight Spark支持JDBCServer的多实例特性介绍》,作者: 一枚核桃。
基于社区已有的JDBCServer基础上,采用多主实例模式实现了其高可用性方案。集群中支持同时共存多个JDBCServer服务,通过客户端可以随机连接其中的任意一个服务进行业务操作。即使集群中一个或多个JDBCServer服务停止工作,也不影响用户通过同一个客户端接口连接其他正常的JDBCServer服务。
多主实例模式相比主备模式的HA方案,优势主要体现在对以下两种场景的改进。
- 主备模式下,当发生主备切换时,会存在一段时间内服务不可用,该时间JDBCServer无法控制,取决于Yarn服务的资源情况。
- Spark中通过类似于HiveServer2的Thrift JDBC提供服务,用户通过Beeline以及JDBC接口访问。因此JDBCServer集群的处理能力取决于主Server的单点能力,可扩展性不够。
采用多主实例模式的HA方案,不仅可以规避主备切换服务中断的问题,实现服务不中断或少中断,还可以通过横向扩展集群来提高并发能力。
实现方案
多主实例模式的HA方案原理如下图所示。
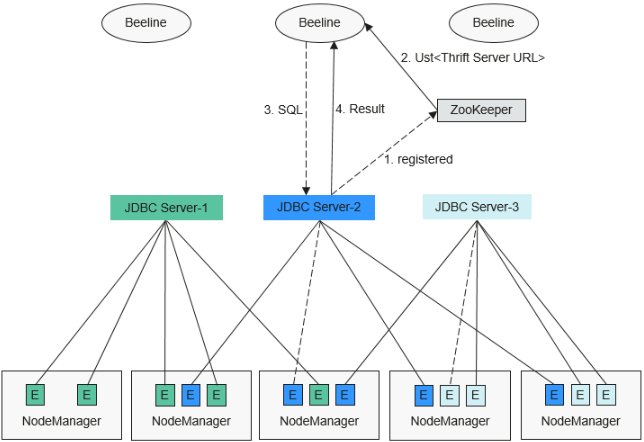
1、JDBCServer在启动时,向ZooKeeper注册自身消息,在指定目录中写入节点,节点包含了该实例对应的IP,端口,版本号和序列号等信息(多节点信息之间以逗号隔开)。
示例如下:
[serverUri=192.168.169.84:22550;version=8.1.2;sequence=0000001244,serverUri=192.168.195.232:22550 ;version=8.1.2;sequence=0000001242,serverUri=192.168.81.37:22550 ;version=8.1.2;sequence=0000001243]
2、客户端连接JDBCServer时,需要指定Namespace,即访问ZooKeeper哪个目录下的JDBCServer实例。在连接的时候,会从Namespace下随机选择一个实例连接,详细URL参见URL连接介绍。
3、客户端成功连接JDBCServer服务后,向JDBCServer服务发送SQL语句。
4、JDBCServer服务执行客户端发送的SQL语句后,将结果返回给客户端。
在HA方案中,每个JDBCServer服务(即实例)都是独立且等同的,当其中一个实例在升级或者业务中断时,其他的实例也能接受客户端的连接请求。
多主实例方案遵循以下规则:
- 当一个实例异常退出时,其他实例不会接管此实例上的会话,也不会接管此实例上运行的业务。
- 当JDBCServer进程停止时,删除在ZooKeeper上的相应节点。
- 由于客户端选择服务端的策略是随机的,可能会出现会话随机分配不均匀的情况,进而可能引起实例间的负载不均衡。
- 实例进入维护模式(即进入此模式后不再接受新的客户端连接)后,当达到退服超时时间,仍在此实例上运行的业务有可能会发生失败。
URL连接介绍
多主实例模式
多主实例模式的客户端读取ZooKeeper节点中的内容,连接对应的JDBCServer服务。连接字符串为:
- 安全模式下:
- Kinit认证方式下的JDBCURL如下所示:
jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;
说明:
- 其中“<zkNode_IP>:<zkNode_Port>”是ZooKeeper的URL,多个URL以逗号隔开。
例如:“192.168.81.37:24002,192.168.195.232:24002,192.168.169.84:24002”。
- 其中“sparkthriftserver2x”是ZooKeeper上的目录,表示客户端从该目录下随机选择JDBCServer实例进行连接。
示例:安全模式下通过Beeline客户端连接时执行以下命令:
sh CLIENT_HOME/spark/bin/beeline -u "jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;"
Keytab认证方式下的JDBCURL如下所示:
jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;user.principal=<principal_name>;user.keytab=<path_to_keytab>
其中<principal_name>表示用户使用的Kerberos用户的principal,如“test@<系统域名>”。<path_to_keytab>表示<principal_name>对应的keytab文件路径,如“/opt/auth/test/user.keytab”。
- 普通模式下:
jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;
示例:普通模式下通过Beeline客户端连接时执行以下命令:
sh CLIENT_HOME/spark/bin/beeline -u "jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;"
非多主实例模式
非多主实例模式的客户端连接的是某个指定JDBCServer节点。该模式的连接字符串相比多主实例模式的去掉关于Zookeeper的参数项“serviceDiscoveryMode”和“zooKeeperNamespace”。
示例:安全模式下通过Beeline客户端连接非多主实例模式时执行以下命令:
sh CLIENT_HOME/spark/bin/beeline -u "jdbc:hive2://<server_IP>:<server_Port>/;user.principal=spark2x/hadoop.<系统域名>@<系统域名>;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;"
说明
- 其中“<server_IP>:<server_Port>”是指定JDBCServer节点的URL。
- “CLIENT_HOME”是指客户端路径。
多主实例模式与非多主实例模式两种模式的JDBCServer接口相比,除连接方式不同外其他使用方法相同。由于Spark JDBCServer是Hive中的HiveServer2的另外一个实现,具体使用方法,请参见Hive官网:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients。
看FusionInsight Spark如何支持JDBCServer的多实例特性的更多相关文章
- Spark SQL 编程API入门系列之Spark SQL支持的API
不多说,直接上干货! Spark SQL支持的API SQL DataFrame(推荐方式,也能执行SQL) Dataset(还在发展) SQL SQL 支持basic SQL syntax/Hive ...
- nginx+tomcat+二级域名静态文件分离支持mp4视频播放配置实例
nginx+tomcat+二级域名静态文件分离支持mp4视频播放配置实例 二级域名配置 在/etc/nginx/conf.d/目录下配置二级域名同名的conf文件,路径改成对应的即可 statics. ...
- Java RMI 介绍和例子以及Spring对RMI支持的实际应用实例
RMI 相关知识 RMI全称是Remote Method Invocation-远程方法调用,Java RMI在JDK1.1中实现的,其威力就体现在它强大的开发分布式网络应用的能力上,是纯Java的网 ...
- 【Spark】Spark2.x版的新特性
一.API 1. 出现新的上下文接口:SparkSession,统一了SQLContext和HiveContext,并且为SparkSession开发了新的流式调用的configuration API ...
- Atitti 存储引擎支持的国内点与特性attilax总结
Atitti 存储引擎支持的国内点与特性attilax总结 存储引擎处理的事情: · 并发性:某些应用程序比其他应用程序具有很多的颗粒级锁定要求(如行级锁定). · 事务支持:并非所有的应用程序都需要 ...
- Spring 4支持的Java 8新特性一览
有众多新特性和函数库的Java 8发布之后,Spring 4.x已经支持其中的大部分.有些Java 8的新特性对Spring无影响,可以直接使用,但另有些新特性需要Spring的支持.本文将带您浏览S ...
- 一篇文章看懂spark 1.3+各版本特性
Spark 1.6.x的新特性Spark-1.6是Spark-2.0之前的最后一个版本.主要是三个大方面的改进:性能提升,新的 Dataset API 和数据科学功能的扩展.这是社区开发非常重要的一个 ...
- 【Spark】一张图看懂Spark的运行架构,以standAlone模式为例
- 查看当前看k8s集群支持的版本命令
# kubectl api-versions admissionregistration.k8s.io/v1 admissionregistration.k8s.io/v1beta1 apiexten ...
- Spark的RDD原理以及2.0特性的介绍
转载自:http://www.tuicool.com/articles/7VNfyif 王联辉,曾在腾讯,Intel 等公司从事大数据相关的工作.2013 年 - 2016 年先后负责腾讯 Yarn ...
随机推荐
- ansible平台
1.ansible概念: 1)ansible和saltstck是目前互联网IT运维人员使用最多的自动化运维管理工具,主要用于对批量(并行)Linux服务器:安装.部署.配置.指令操作.任务计划.参数调 ...
- YCSB对MongoDB数据库性能测试
一.安装部署 1.1前置条件 Install Java and Maven Go to http://www.oracle.com/technetwork/java/javase/downloads/ ...
- CodeDesk-一个新款跨平台桌面开发框架
CodeDesk 的灵感来自 Electron和Photino.这是一个基于 .NET 的开源项目. CodeDesk 的目标是使开发人员能够在跨平台的本机应用程序中使用 Web UI(HTML.Ja ...
- Sealos 云操作系统一键集成 runwasi,解锁 Wasm 的无限潜力
WebAssembly (通常缩写为 Wasm) 是一种为网络浏览器设计的低级编程语言.它旨在提供一种比传统的 JavaScript 更快.更高效的方式来执行代码,以弥补 JavaScript 在性能 ...
- 【开源】int,long long去一边去:高精度大合集!
加法 \(add\) string add(string s1, string s2) { //时间复杂度 O(log n) string res = ""; int c = 0, ...
- 第五周阅读笔记|人月神话————胸有成竹(Calling the Shot)
这个章节标题是胸有成竹,而要做到胸有成竹就必须在项目计划阶段我们对项目的预测和估算都需要很准确.因此整个章节的内容就是在讲估算,而估算就涉及到预测和估算模型,估算要做到准确必须通过前期多个历史项目和版 ...
- 有什么巨好用Excel数据分析技巧?
当涉及Excel数据分析时,以下是一些非常实用的技巧和功能,供您参考.这里将为您提供关于数据整理.数据清洗.统计分析.可视化和高级分析等方面的技巧. 一.数据整理与清洗: 导入数据:使用 Excel ...
- CortexM外设:NVIC 嵌套向量中断控制器
优先级分组Priority Group 使能Enabled 抢占优先级Preemption Priority 子优先级Sub Priority 外部中断线 EXTI Line 定时器中断 TIM1 u ...
- ubuntu安装cudnn
有些忙,这一段时间,博客就随便写写了--- 默认cuda安装好了,这里就不多说了,我们从cuda的环境变量开始说起: 配置cuda环境变量: 打开终端,输入"gedit ~/.bashrc& ...
- Git恢复删除的文件,一行命令就可以啦~
情况一:删除或者修改了某个文件,但是没有add # 单个 git checkout filename # 多个 git checkout . 情况二:删除或者修改了某个文件,已经add,但是没有com ...