一文详解TensorFlow模型迁移及模型训练实操步骤
摘要:本文介绍将TensorFlow网络模型迁移到昇腾AI平台,并执行训练的全流程。然后以TensorFlow 1.15训练脚本为例,详细介绍了自动迁移、手工迁移以及模型训练的操作步骤。
本文分享自华为云社区《将TensorFlow模型快速迁移到昇腾平台》,作者:昇腾CANN。
当前业界很多训练脚本是基于TensorFlow的Python API进行开发的,默认运行在CPU/GPU/TPU上,为了使这些脚本能够利用昇腾AI处理器的强大算力执行训练,需要对TensorFlow的训练脚本进行迁移。
首先,我们了解下模型迁移的全流程:

通过上图可以看出,模型迁移包括“脚本迁移 –> 模型训练 –> 精度调优 –> 性能调优 –> 模型固化”几个流程,其中:
- “脚本迁移”是将TensorFlow训练脚本经过少量修改,可以运行在昇腾AI处理器上。
- “模型训练”是根据模型参数进行多轮次的训练迭代,并在训练过程中评估模型准确度,达到一定阈值后停止训练,并保存训练好的模型。
- “精度调优”与“性能调优”是在用户对精度或性能有要求时需要执行的操作。
- “模型固化”是将训练好的、精度性能达标的模型固化为pb模型。
下面我们针对“脚本迁移”和“模型训练”两个阶段进行详细的介绍。
脚本迁移
将TensorFlow训练脚本迁移到昇腾平台有自动迁移和手工迁移两种方式。
- 自动迁移:算法工程师通过迁移工具,可自动分析出原生的TensorFlow Python API在昇腾AI处理器上的支持度情况,同时将原生的TensorFlow训练脚本自动迁移成昇腾AI处理器支持的脚本,对于少量无法自动迁移的API,可以参考工具输出的迁移报告,对训练脚本进行相应的适配修改。
- 手工迁移:算法工程师需要参考文档人工分析TensorFlow训练脚本的API支持度,并进行相应API的修改,以支持在昇腾AI处理器上执行训练,该种方式相对复杂,建议优先使用自动迁移方式。
下面以TensorFlow 1.15的训练脚本为例,讲述训练脚本的详细迁移操作,TensorFlow 2.6的迁移操作类似,详细的迁移点可参见“昇腾文档中心[1]”。
自动迁移
自动迁移的流程示意图如下所示:
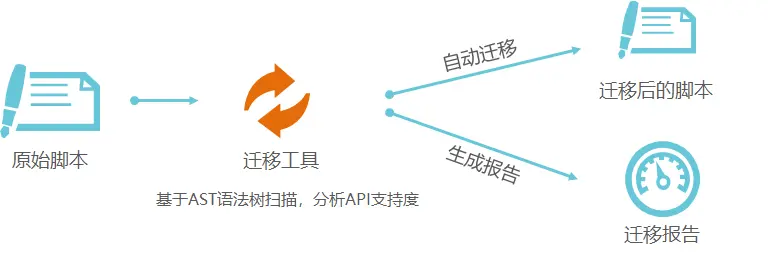
详细步骤如下;
1. 安装迁移工具依赖。
pip3 install pandas
pip3 install xlrd==1.2.0
pip3 install openpyxl
pip3 install tkintertable
pip3 install google_pasta
2. 执行自动迁移命令。
进入迁移工具所在目录,例如“tfplugin安装目录/tfplugin/latest/python/site-packages/npu_bridge/convert_tf2npu/”,执行类似如下命令可同时完成脚本扫描和自动迁移:
python3 main.py -i /root/models/official/resnet -r /root/models/official/
其中main.py是迁移工具入口脚本,-i指定待迁移原始脚本路径,-r指定迁移报告存储路径。
3. 查看迁移报告。
在/root/models/official/output_npu_*下查看迁移后的脚本,在root/models/official/report_npu_*下查看迁移报告。
迁移报告示例如下:

手工迁移
手工迁移训练脚本主要包括如下迁移点:
1. 导入NPU库文件。
from npu_bridge.npu_init import *
2. 将部分TensorFlow接口迁移成NPU接口。
例如,修改基于Horovod开发的分布式训练脚本,使能昇腾AI处理器的分布式训练。
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
修改后:
# NPU allreduce
# 将hvd.DistributedOptimizer修改为npu_distributed_optimizer_wrapper"
opt = npu_distributed_optimizer_wrapper(opt)
# Add hook to broadcast variables from rank 0 to all other processes during initialization.
hooks = [NPUBroadcastGlobalVariablesHook(0)]
3. 通过配置关闭TensorFlow与NPU冲突的功能。
关闭TensorFlow中的remapping、xla等功能,避免与NPU中相关功能冲突。例如:
config = tf.ConfigProto(allow_soft_placement=True)
# 显式关闭remapping功能
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
# 显示关闭memory_optimization功能
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
4. 配置NPU相关参数
Ascend平台提供了功能调试、性能/精度调优等功能,用户可通过配置使能相关功能,例如enable_dump_debug配置,支持以下取值:
- True:开启溢出检测功能。
- False:关闭溢出检测功能。
配置示例:
custom_op.parameter_map["enable_dump_debug"].b = True
模型训练
迁移成功后的脚本可在昇腾AI处理器上执行单Device训练,也可以在多个Device上执行分布式训练。
单Device训练
1)配置训练进程启动依赖的环境变量。
# 配置昇腾软件栈的基础环境变量,包括CANN、TF Adapter依赖的内容。
source /home/HwHiAiUser/Ascend/nnae/set_env.sh
source /home/HwHiAiUser/Ascend/tfplugin/set_env.sh
# 添加当前脚本所在路径到PYTHONPATH,例如:
export PYTHONPATH="$PYTHONPATH:/root/models"
# 训练任务ID,用户自定义,不建议使用以0开始的纯数字
export JOB_ID=10066
# 指定昇腾AI处理器逻辑ID,单P训练也可不配置,默认为0,在0卡执行训练
export ASCEND_DEVICE_ID=0
2)执行训练脚本拉起训练进程。
python3 /home/xxx.py
分布式训练
分布式训练需要先配置参与训练的昇腾AI处理器的资源信息,然后再拉起训练进程。当前有两种配置资源信息的方式:通过配置文件(即ranktable文件)或者通过环境变量的方式。下面以配置文件的方式介绍分布式训练的操作。
1)准备配置文件。
配置文件(即ranktable文件)为json格式,示例如下:
{
"server_count":"1", //AI server数目
"server_list":
[
{
"device":[ // server中的device列表
{
"device_id":"0",
"device_ip":"192.168.1.8", // 处理器真实网卡IP
"rank_id":"0" // rank的标识,rankID从0开始
},
{
"device_id":"1",
"device_ip":"192.168.1.9",
"rank_id":"1"
}
],
"server_id":"10.0.0.10" //server标识,以点分十进制表示IP字符串
}
],
"status":"completed", // ranktable可用标识,completed为可用
"version":"1.0" // ranktable模板版本信息,当前必须为"1.0"
}
2)执行分布式训练。
依次设置环境变量配置集群参数,并拉起训练进程。
拉起训练进程0:
# 配置昇腾软件栈的基础环境变量,包括CANN、TF Adapter依赖的内容。
source /home/HwHiAiUser/Ascend/nnae/set_env.sh
source /home/HwHiAiUser/Ascend/tfplugin/set_env.sh
export PYTHONPATH=/home/test:$PYTHONPATH
export JOB_ID=10086
export ASCEND_DEVICE_ID=0
# 当前Device在集群中的唯一索引,与资源配置文件中的索引一致
export RANK_ID=0
# 参与分布式训练的Device数量
export RANK_SIZE=2
export RANK_TABLE_FILE=/home/test/rank_table_2p.json
python3 /home/xxx.py
拉起训练进程1:
# 配置昇腾软件栈的基础环境变量,包括CANN、TF Adapter依赖的内容。
source /home/HwHiAiUser/Ascend/nnae/set_env.sh
source /home/HwHiAiUser/Ascend/tfplugin/set_env.sh
export PYTHONPATH=/home/test:$PYTHONPATH
export JOB_ID=10086
export ASCEND_DEVICE_ID=1
# 当前Device在集群中的唯一索引,与资源配置文件中的索引一致
export RANK_ID=1
# 参与分布式训练的Device数量
export RANK_SIZE=2
export RANK_TABLE_FILE=/home/test/rank_table_2p.json
python3 /home/xxx.py
以上就是TensorFlow模型迁移训练的相关知识点,您也可以在“昇腾社区在线课程[2]”板块学习视频课程,学习过程中的任何疑问,都可以在“昇腾论坛[3]”互动交流!
相关参考:
[1]昇腾文档中心:https://www.hiascend.com/zh/document
[2]昇腾社区在线课程:https://www.hiascend.com/zh/edu/courses
[3]昇腾论坛:https://www.hiascend.com/forum
一文详解TensorFlow模型迁移及模型训练实操步骤的更多相关文章
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- 十图详解tensorflow数据读取机制(附代码)转知乎
十图详解tensorflow数据读取机制(附代码) - 何之源的文章 - 知乎 https://zhuanlan.zhihu.com/p/27238630
- 一文详解Hexo+Github小白建站
作者:玩世不恭的Coder时间:2020-03-08说明:本文为原创文章,未经允许不可转载,转载前请联系作者 一文详解Hexo+Github小白建站 前言 GitHub是一个面向开源及私有软件项目的托 ...
- 一文详解 Linux 系统常用监控工一文详解 Linux 系统常用监控工具(top,htop,iotop,iftop)具(top,htop,iotop,iftop)
一文详解 Linux 系统常用监控工具(top,htop,iotop,iftop) 概 述 本文主要记录一下 Linux 系统上一些常用的系统监控工具,非常好用.正所谓磨刀不误砍柴工,花点时间 ...
- 一文详解RocketMQ的存储模型
摘要:RocketMQ 优异的性能表现,必然绕不开其优秀的存储模型. 本文分享自华为云社区<终于弄明白了 RocketMQ 的存储模型>,作者:勇哥java实战分享. RocketMQ 优 ...
- 一文详解扩散模型:DDPM
作者:京东零售 刘岩 扩散模型讲解 前沿 人工智能生成内容(AI Generated Content,AIGC)近年来成为了非常前沿的一个研究方向,生成模型目前有四个流派,分别是生成对抗网络(Gene ...
- TCP/IP详解与OSI七层模型
TCP/IP协议 包含了一系列构成互联网基础的网络协议,是Internet的核心协议.基于TCP/IP的参考模型将协议分成四个层次,它们分别是链路层.网络层.传输层和应用层.下图表示TCP/IP模型与 ...
- 一文详解 OpenGL ES 3.x 渲染管线
OpenGL ES 构建的三维空间,其中的三维实体由许多的三角形拼接构成.如下图左侧所示的三维实体圆锥,其由许多三角形按照一定规律拼接构成.而组成圆锥的每一个三角形,其任意一个顶点由三维空间中 x.y ...
- 一文详解 WebSocket 网络协议
WebSocket 协议运行在TCP协议之上,与Http协议同属于应用层网络数据传输协议.WebSocket相比于Http协议最大的特点是:允许服务端主动向客户端推送数据(从而解决Http 1.1协议 ...
- 1.3w字,一文详解死锁!
死锁(Dead Lock)指的是两个或两个以上的运算单元(进程.线程或协程),都在等待对方停止执行,以取得系统资源,但是没有一方提前退出,就称为死锁. 1.死锁演示 死锁的形成分为两个方面,一个是使用 ...
随机推荐
- 关于IP我们需要知道的
IP 在这个数字世界中,互联网已成为我们生活的一部分.而在互联网的背后,网络知识如同一张巨大的蜘蛛网,将我们与世界各地的信息紧密联系在一起.其中,IP这个看似平凡的名词,却是支撑这个虚拟世界的重要基石 ...
- 【Qt6】列表模型——几个便捷的列表类型
前面一些文章,老周简单介绍了在Qt 中使用列表模型的方法.很明显,使用 Item Model 在许多时候还是挺麻烦的--要先建模型,再放数据,最后才构建视图.为了简化这些骚操作,Qt 提供了几个便捷类 ...
- webview是什么?作用是什么?和浏览器有什么关系?
Webview 是一个基于webkit的引擎,可以解析DOM 元素,展示html页面的控件,它和浏览器展示页面的原理是相同的,所以可以把它当做浏览器看待.(chrome浏览器也是基于webkit引擎开 ...
- Go 接口:Go中最强大的魔法,接口应用模式或惯例介绍
Go 接口:Go中最强大的魔法,接口应用模式或惯例介绍 目录 Go 接口:Go中最强大的魔法,接口应用模式或惯例介绍 一.前置原则 二.一切皆组合 2.1 一切皆组合 2.2 垂直组合 2.2.1 第 ...
- 请问您今天要来点 ODT 吗
梗出处:请问您今天要来点兔子吗? 这篇文章主要记录一下自己学习 \(\text{ODT}\) 发生的种种. CF896C Willem, Chtholly and Seniorious \(\text ...
- re1-100
虽然关键的判断函数和"成功"的提示也在这里,但是具体对输入flag的操作却在后面 看到对数组bufParentRead[1]开始赋值"53fc275d81",b ...
- Educational Codeforces Round 105 (Rated for Div. 2) A-C题解
写在前边 链接:Educational Codeforces Round 105 (Rated for Div. 2) A. ABC String 链接:A题链接 题目大意: 给定一个有\(A.B.C ...
- 手撕Vue-Router-添加全局$router属性
前言 经过上一篇文章的介绍,完成了初始化路由相关信息的内容,接下来我们需要将路由信息挂载到Vue实例上,这样我们就可以在Vue实例中使用路由信息了. 简而言之就是给每一个Vue实例添加一个$route ...
- Linux配置静态IP解决无法访问网络问题
Linux系统安装成功之后只是单机无网络状态,我们需要配置Linux静态IP来确保服务器可以正常连接互联网 1.首先安装ifconfig Centos7安装成功后,高版本会把ping命令给移除了,所以 ...
- Spring Boot 关闭 Actuator ,满足安全工具扫描
应用被安全工具,扫描出漏洞信息 [MSS]SpringBoot Actuator敏感接口未授权访问漏洞(Actuator)事件发现通告: 发现时间:2023-11-25 19:47:17 攻击时间:2 ...