带你读AI论文:基于Transformer的直线段检测
摘要:本文提出了一种基于Transformer的端到端的线段检测模型。采用多尺度的Encoder/Decoder算法,可以得到比较准确的线端点坐标。作者直接用预测的线段端点和Ground truth的端点的距离作为目标函数,可以更好的对线段端点坐标进行回归。
本文分享自华为云社区《论文解读系列十七:基于Transformer的直线段检测》,作者:cver。

1 文章摘要
传统的形态学线段检测首先要对图像进行边缘检测,然后进行后处理得到线段的检测结果。一般的深度学习方法,首先要得到线段端点和线的热力图特征,然后进行融合处理得到线的检测结果。作者提出了一种新的基于Transformer的方法,无需进行边缘检测、也无需端点和线的热力图特征,端到端的直接得到线段的检测结果,也即线段的端点坐标。
线段检测属于目标检测的范畴,本文提出的线段检测模型LETR是在DETR(End-to-End Object Detection with Transformers)的基础上的扩展,区别就是Decoder在最后预测和回归的时候,一个是回归的box的中心点、宽、高值,一个是回归的线的端点坐标。
因此,接下来首先介绍一下DETR是如何利用Transformer进行目标检测的。之后重点介绍一下LETR独有的一些内容。
2、如何利用Transformer进行目标检测(DETR)
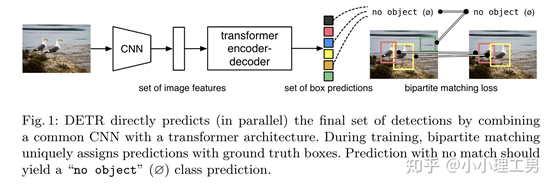
图1. DETR模型结构
上图是DETR的模型结构。DETR首先利用一个CNN 的backbone提取图像的features,编码之后输入Transformer模型得到N个预测的box,然后利用FFN进行分类和坐标回归,这一部分和传统的目标检测类似,之后把N个预测的box和M个真实的box进行二分匹配(N>M,多出的为空类,即没有物体,坐标值直接设置为0)。利用匹配结果和匹配的loss更新权重参数,得到最终的box的检测结果和类别。这里有几个关键点:
首先是图像特征的序列化和编码。
CNN-backbone输出的特征的维度为C*H*W,首先用1*1的conv进行降维,将channel从C压缩到d, 得到d*H*W的特征图。之后合并H、W两个维度,特征图的维度变为d*HW。序列化的特征图丢失了原图的位置信息,因此需要再加上position encoding特征,得到最终序列化编码的特征。
然后是Transformer的Decoder
目标检测的Transformer的Decoder是一次处理全部的Decoder输入,也即 object queries,和原始的Transformer从左到右一个一个输出略有不同。
另外一点Decoder的输入是随机初始化的,并且是可以训练更新的。
二分匹配
Transformer的Decoder输出了N个object proposal ,我们并不知道它和真实的Ground truth的对应关系,因此需要经二分图匹配,采用的是匈牙利算法,得到一个使的匹配loss最小的匹配。匹配loss如下:

得到最终匹配后,利用这个loss和分类loss更新参数。
3、LETR模型结构

图2. LETR模型结构
Transformer的结构主要包括Encoder、Decoder 和 FFN。每个Encoder包含一个self-attention和feed-forward两个子层。Decoder 除了self-attention和feed-forward还包含cross-attention。注意力机制:注意力机制和原始的Transformer类似,唯一的不同就是Decoder的cross-attention,上文已经做了介绍,就不再赘述。
Coarse-to-Fine 策略
从上图中可以看出LETR包含了两个Transformer。作者称此为a multi-scale Encoder/Decoder strategy,两个Transformer分别称之为Coarse Encoder/Decoder,Fine Encoder/Decoder。也就是先用CNN backbone深层的小尺度的feature map(ResNet的conv5,feature map的尺寸为原图尺寸的1/32,通道数为2048) 训练一个Transformer,即Coarse Encoder/Decoder,得到粗粒度的线段的特征(训练的时候固定Fine Encoder/Decoder,只更新Coarse Encoder/Decoder的参数)。然后把Coarse Decoder的输出作为Fine Decoder的输入,再训练一个Transformer,即Fine Encoder/Decoder。Fine Encoder的输入是CNN backbone浅层的feature map(ResNet的conv4,feature map的尺寸为原图尺寸的1/16,通道数为1024),比深层的feature map具有更大的维度,可以更好的利用图像的高分辨率信息。
注:CNN的backbone深层和浅层的feature map特征都需要先通过1*1的卷积把通道数都降到256维,再作为Transformer的输入
二分匹配
和DETR一样, 利用fine Decoder的N个输出进行分类和回归,得到N个线段的预测结果。但是我们并不知道N个预测结果和M个真实的线段的对应关系,并且N还要大于M。这个时候我们就要进行二分匹配。所谓的二分匹配就是找到一个对应关系,使得匹配loss最小,因此我们需要给出匹配的loss,和上面DERT的表达式一样,只不过这一项略有不同,一个是GIou一个是线段的端点距离。
4、模型测试结果
模型在Wireframe和YorkUrban数据集上达到了state-of–the-arts。

图3. 线段检测方法效果对比

图4、线段检测方法在两种数据集上的性能指标对比(Table 1);线段检测方法的PR曲线(Figure 6)
带你读AI论文:基于Transformer的直线段检测的更多相关文章
- 带你读AI论文:NDSS2020 UNICORN: Runtime Provenance-Based Detector
摘要:这篇文章将详细介绍NDSS2020的<UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats& ...
- 带你读AI论文丨ACGAN-动漫头像生成
摘要:ACGAN-动漫头像生成是一个十分优秀的开源项目. 本文分享自华为云社区<[云驻共创]AI论文精读会:ACGAN-动漫头像生成>,作者:SpiderMan. 1.论文及算法介绍 1. ...
- 带你读AI论文丨LaneNet基于实体分割的端到端车道线检测
摘要:LaneNet是一种端到端的车道线检测方法,包含 LanNet + H-Net 两个网络模型. 本文分享自华为云社区<[论文解读]LaneNet基于实体分割的端到端车道线检测>,作者 ...
- 带你读AI论文丨S&P21 Survivalism: Living-Off-The-Land 经典离地攻击
摘要:这篇文章属于系统分析类的文章,通过详细的实验分析了离地攻击(Living-Off-The-Land)的威胁性和流行度,包括APT攻击中的利用及示例代码论证. 本文分享自华为云社区<[论文阅 ...
- 带你读AI论文丨用于目标检测的高斯检测框与ProbIoU
摘要:本文解读了<Gaussian Bounding Boxes and Probabilistic Intersection-over-Union for Object Detection&g ...
- 带你读AI论文丨RAID2020 Cyber Threat Intelligence Modeling GCN
摘要:本文提出了基于异构信息网络(HIN, Heterogeneous Information Network)的网络威胁情报框架--HINTI,旨在建模异构IOCs之间的相互依赖关系,以量化其相关性 ...
- 带你读AI论文丨针对文字识别的多模态半监督方法
摘要:本文提出了一种针对文字识别的多模态半监督方法,具体来说,作者首先使用teacher-student网络进行半监督学习,然后在视觉.语义以及视觉和语义的融合特征上,都进行了一致性约束. 本文分享自 ...
- 一文带你读懂什么是vxlan网络
一个执着于技术的公众号 一.背景 随着云计算.虚拟化相关技术的发展,传统网络无法满足大规模.灵活性要求高的云数据中心的要求,于是便有了overlay网络的概念.overlay网络中被广泛应用的就是vx ...
- 少啰嗦!一分钟带你读懂Java的NIO和经典IO的区别
1.引言 很多初涉网络编程的程序员,在研究Java NIO(即异步IO)和经典IO(也就是常说的阻塞式IO)的API时,很快就会发现一个问题:我什么时候应该使用经典IO,什么时候应该使用NIO? 在本 ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
随机推荐
- tunm, 一种对标JSON的二进制数据协议
Tunm simple binary proto 一种对标JSON的二进制数据协议 支持的数据类型 基本支持的类型 "u8", "i8", "u16& ...
- 虹科干货|Redis企业版数据库为企业「数据安全」叠加最强Buff!
"这是一场可预见的噩梦!" 近期,黑客通过攻击亚洲最大两家数据中心-万国数据和新科电信媒体,获取国际巨头企业的登录凭证,引发了2000多家企业史诗级数据泄露.中国作为全球第二大托管 ...
- [Python急救站课程]绘制蜡笔小新图案
可爱的蜡笔小新想要吗?画起来 import turtle as t '''设置''' t.setup(800, 500) # 创建画布并使其位于屏幕中心 t.pensize(2) # 画笔粗细 t.c ...
- [Python急救站课程]无角正方形
无角正方形 from turtle import * penup() fd(-100) pendown() pensize(10) penup() seth(0) fd(20) pendown() f ...
- 在NestJS应用程序中使用 Unleash 实现功能切换的指南
前言 近年来,软件开发行业迅速发展,功能开关(Feature Toggle)成为了一种常见的开发实践.通过功能开关,可以在运行时动态地启用或禁用应用程序的特定功能,以提供更灵活的软件交付和配置管理.对 ...
- 2021-09 .NET 5.0.10 Update for x64 Client (KB5006192) 安装失败,错误代码:0x80070643
上周五日常检查系统更新(强迫症晚期) 出现一项更新:2021-09 .NET 5.0.10 Update for x64 Client (KB5006192) details: https://www ...
- vue-router重写push方法,解决相同路径跳转报错,解决点击菜单栏打开外部链接
修改vue-router的配置文件,默认位置router/index.js import Vue from 'vue' import Router from 'vue-router' /** * 重写 ...
- Tech Lead 要学会戴着镣铐跳舞
这不是一篇讨喜的文章,至少不会是你常常看到的例如<成为优秀 Tech Lead 的六个建议>令人欢欣鼓舞的那一类.今天我们聊聊 Tech Lead 所面临的不那么轻松的现实问题 程序员一定 ...
- c++算法练习day01【2022年蓝桥杯省赛B组题目】每天做一点、、、
这个练习目前来说就比较宽松,打算在寒假(基本也就是这一个月每天刷几道题吧) 题目一: 小明决定从下周一开始努力刷题准备蓝桥杯竞赛.他计划周一至周五每天做 a 道题目,周六和周日每天做 b 道题目.请你 ...
- Gradio-Lite: 完全在浏览器里运行的无服务器 Gradio
Gradio 是一个经常用于创建交互式机器学习应用的 Python 库.在以前按照传统方法,如果想对外分享 Gradio 应用,就需要依赖服务器设备和相关资源,而这对于自己部署的开发人员来说并不友好. ...