带你读AI论文:基于Transformer的直线段检测
摘要:本文提出了一种基于Transformer的端到端的线段检测模型。采用多尺度的Encoder/Decoder算法,可以得到比较准确的线端点坐标。作者直接用预测的线段端点和Ground truth的端点的距离作为目标函数,可以更好的对线段端点坐标进行回归。
本文分享自华为云社区《论文解读系列十七:基于Transformer的直线段检测》,作者:cver。

1 文章摘要
传统的形态学线段检测首先要对图像进行边缘检测,然后进行后处理得到线段的检测结果。一般的深度学习方法,首先要得到线段端点和线的热力图特征,然后进行融合处理得到线的检测结果。作者提出了一种新的基于Transformer的方法,无需进行边缘检测、也无需端点和线的热力图特征,端到端的直接得到线段的检测结果,也即线段的端点坐标。
线段检测属于目标检测的范畴,本文提出的线段检测模型LETR是在DETR(End-to-End Object Detection with Transformers)的基础上的扩展,区别就是Decoder在最后预测和回归的时候,一个是回归的box的中心点、宽、高值,一个是回归的线的端点坐标。
因此,接下来首先介绍一下DETR是如何利用Transformer进行目标检测的。之后重点介绍一下LETR独有的一些内容。
2、如何利用Transformer进行目标检测(DETR)
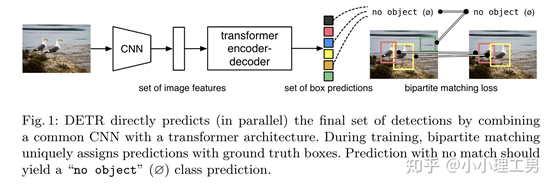
图1. DETR模型结构
上图是DETR的模型结构。DETR首先利用一个CNN 的backbone提取图像的features,编码之后输入Transformer模型得到N个预测的box,然后利用FFN进行分类和坐标回归,这一部分和传统的目标检测类似,之后把N个预测的box和M个真实的box进行二分匹配(N>M,多出的为空类,即没有物体,坐标值直接设置为0)。利用匹配结果和匹配的loss更新权重参数,得到最终的box的检测结果和类别。这里有几个关键点:
首先是图像特征的序列化和编码。
CNN-backbone输出的特征的维度为C*H*W,首先用1*1的conv进行降维,将channel从C压缩到d, 得到d*H*W的特征图。之后合并H、W两个维度,特征图的维度变为d*HW。序列化的特征图丢失了原图的位置信息,因此需要再加上position encoding特征,得到最终序列化编码的特征。
然后是Transformer的Decoder
目标检测的Transformer的Decoder是一次处理全部的Decoder输入,也即 object queries,和原始的Transformer从左到右一个一个输出略有不同。
另外一点Decoder的输入是随机初始化的,并且是可以训练更新的。
二分匹配
Transformer的Decoder输出了N个object proposal ,我们并不知道它和真实的Ground truth的对应关系,因此需要经二分图匹配,采用的是匈牙利算法,得到一个使的匹配loss最小的匹配。匹配loss如下:

得到最终匹配后,利用这个loss和分类loss更新参数。
3、LETR模型结构

图2. LETR模型结构
Transformer的结构主要包括Encoder、Decoder 和 FFN。每个Encoder包含一个self-attention和feed-forward两个子层。Decoder 除了self-attention和feed-forward还包含cross-attention。注意力机制:注意力机制和原始的Transformer类似,唯一的不同就是Decoder的cross-attention,上文已经做了介绍,就不再赘述。
Coarse-to-Fine 策略
从上图中可以看出LETR包含了两个Transformer。作者称此为a multi-scale Encoder/Decoder strategy,两个Transformer分别称之为Coarse Encoder/Decoder,Fine Encoder/Decoder。也就是先用CNN backbone深层的小尺度的feature map(ResNet的conv5,feature map的尺寸为原图尺寸的1/32,通道数为2048) 训练一个Transformer,即Coarse Encoder/Decoder,得到粗粒度的线段的特征(训练的时候固定Fine Encoder/Decoder,只更新Coarse Encoder/Decoder的参数)。然后把Coarse Decoder的输出作为Fine Decoder的输入,再训练一个Transformer,即Fine Encoder/Decoder。Fine Encoder的输入是CNN backbone浅层的feature map(ResNet的conv4,feature map的尺寸为原图尺寸的1/16,通道数为1024),比深层的feature map具有更大的维度,可以更好的利用图像的高分辨率信息。
注:CNN的backbone深层和浅层的feature map特征都需要先通过1*1的卷积把通道数都降到256维,再作为Transformer的输入
二分匹配
和DETR一样, 利用fine Decoder的N个输出进行分类和回归,得到N个线段的预测结果。但是我们并不知道N个预测结果和M个真实的线段的对应关系,并且N还要大于M。这个时候我们就要进行二分匹配。所谓的二分匹配就是找到一个对应关系,使得匹配loss最小,因此我们需要给出匹配的loss,和上面DERT的表达式一样,只不过这一项略有不同,一个是GIou一个是线段的端点距离。
4、模型测试结果
模型在Wireframe和YorkUrban数据集上达到了state-of–the-arts。

图3. 线段检测方法效果对比

图4、线段检测方法在两种数据集上的性能指标对比(Table 1);线段检测方法的PR曲线(Figure 6)
带你读AI论文:基于Transformer的直线段检测的更多相关文章
- 带你读AI论文:NDSS2020 UNICORN: Runtime Provenance-Based Detector
摘要:这篇文章将详细介绍NDSS2020的<UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats& ...
- 带你读AI论文丨ACGAN-动漫头像生成
摘要:ACGAN-动漫头像生成是一个十分优秀的开源项目. 本文分享自华为云社区<[云驻共创]AI论文精读会:ACGAN-动漫头像生成>,作者:SpiderMan. 1.论文及算法介绍 1. ...
- 带你读AI论文丨LaneNet基于实体分割的端到端车道线检测
摘要:LaneNet是一种端到端的车道线检测方法,包含 LanNet + H-Net 两个网络模型. 本文分享自华为云社区<[论文解读]LaneNet基于实体分割的端到端车道线检测>,作者 ...
- 带你读AI论文丨S&P21 Survivalism: Living-Off-The-Land 经典离地攻击
摘要:这篇文章属于系统分析类的文章,通过详细的实验分析了离地攻击(Living-Off-The-Land)的威胁性和流行度,包括APT攻击中的利用及示例代码论证. 本文分享自华为云社区<[论文阅 ...
- 带你读AI论文丨用于目标检测的高斯检测框与ProbIoU
摘要:本文解读了<Gaussian Bounding Boxes and Probabilistic Intersection-over-Union for Object Detection&g ...
- 带你读AI论文丨RAID2020 Cyber Threat Intelligence Modeling GCN
摘要:本文提出了基于异构信息网络(HIN, Heterogeneous Information Network)的网络威胁情报框架--HINTI,旨在建模异构IOCs之间的相互依赖关系,以量化其相关性 ...
- 带你读AI论文丨针对文字识别的多模态半监督方法
摘要:本文提出了一种针对文字识别的多模态半监督方法,具体来说,作者首先使用teacher-student网络进行半监督学习,然后在视觉.语义以及视觉和语义的融合特征上,都进行了一致性约束. 本文分享自 ...
- 一文带你读懂什么是vxlan网络
一个执着于技术的公众号 一.背景 随着云计算.虚拟化相关技术的发展,传统网络无法满足大规模.灵活性要求高的云数据中心的要求,于是便有了overlay网络的概念.overlay网络中被广泛应用的就是vx ...
- 少啰嗦!一分钟带你读懂Java的NIO和经典IO的区别
1.引言 很多初涉网络编程的程序员,在研究Java NIO(即异步IO)和经典IO(也就是常说的阻塞式IO)的API时,很快就会发现一个问题:我什么时候应该使用经典IO,什么时候应该使用NIO? 在本 ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
随机推荐
- ES6入门(一)
1.let声明的变量只在let命令所在的代码块内有效 2.不存在变量提升,先使用变量,后定义变量,就会报错. 3.let不允许在相同作用域内,重复声明同一个变量.
- 虹科干货 | 零售业数智升级不掉队,get数据,get未来!
电商崛起,传统零售行业危机四伏,全渠道盈利与可持续化成为难点,库存管理这块难啃的"硬骨头"也同样让零售商倍感压力...... 背腹受敌的零售商,如何才能在数字化转型道路上避免利润缩 ...
- 子组件emit 父组件方法,成功后回调执行子组件方法
场景: 父组件 update方法 子组件 确定按钮 getlist 刷新列表 子组件点击确定按钮,调用父组件新增接口,新增成功以后,子组件列表刷新 子组件: emit("confirmPa ...
- DocTemplateTool - 可根据模板生成word或pdf文件的工具
你是否经常遇到这样的场景:产品运营有着大量的报告需求,或者给客户领导展现每周的运营报告?这些文档类的任务可以交给运营同事,他们负责文档排版和样式,你作为开发人员你只需要提供数据源,和一个映射表,告诉制 ...
- LabVIEW基于机器视觉的实验室设备管理系统(5)
目录 行动计划 设备借用 判断设备ID是否正确.设备是否在库 判断是否为已注册用户.电话是否正确 借出设备 设备归还 信息查询 判断ID是否正确.选择设备状态 效果演示 今天这一期,我们就来完成实验 ...
- 一文搞懂C#中类成员的可访问性
公众号「DotNet学习交流」,分享学习DotNet的点滴. 文末有总结,想快速浏览的朋友可直接看文末. 1.成员访问修饰符 在C#中类成员访问修饰符一共有5个,分别是public.private.p ...
- 地图选择器datav怎么使用?
DataV 是一款基于阿里云的数据可视化产品,它提供了丰富的组件和功能,其中包括地图选择器.下面是一个详细的介绍: 1. 了解 DataV: - DataV 是一款强大的数据可视化工具,能够帮助用户将 ...
- 0x04.信息收集
探针 被动:借助网上的一些接口查询或者网上已经获取到的,查看历史信息. 主动:使用工具,从本地流量出发,探测目标信息,会发送大量流量到对方服务器上. 谷歌语法 懒人语法:https://pentest ...
- .NET使用分布式网络爬虫框架DotnetSpider快速开发爬虫功能
前言 前段时间有同学在微信群里提问,要使用.NET开发一个简单的爬虫功能但是没有做过无从下手.今天给大家推荐一个轻量.灵活.高性能.跨平台的分布式网络爬虫框架(可以帮助 .NET 工程师快速的完成爬虫 ...
- 【译】Visual Studio 17.8 中我最喜欢的特性
对于 Visual Studio 团队来说,这是忙碌的一周,他们准备了 Ignite 和 .NET Conf,并发布了最新版本的 Visual Studio 2022,即17.8版本.有很多很酷的新功 ...