structed streaming 触发器trigger
structed streaming的执行批次,较spark streaming有所改变。更加灵活。总结下来,可大白话地分为三类:
1尽可能快的执行,不定时间
2按固定间隔时间执行
3仅执行一次
详情如下:
| Trigger类型 | 使用 | 注意 |
|---|---|---|
| unspecified (default) | as soon as micro-batch | If no trigger setting is explicitly specified, then by default, the query will be executed in micro-batch mode, where micro-batches will be generated as soon as the previous micro-batch has completed processing.如果不设置,默认使用微批,但没有时间间隔,尽可能快的处理 |
| Interval micro-batch(固定间隔的微批) | Trigger.ProcessingTime(long interval, TimeUnit timeUnit) | 根据数据实际情况,不定时批次1. 没有明确指明触发器时,默认使用该触发器,即Trigger.ProcessingTime(0L), 表示将尽可能快地执行查询。2. 该模式下,将按用户指定的时间间隔启动微批处理。3. 如果前一个微批在该间隔内完成,则引擎将等待该间隔结束,然后再开始下一个微批处理。4. 如果前一个微批花费的时间比间隔要长,下一个微批将在前一个微批处理完成后立即开始。5. 如果没有新数据可用,则不会启动微批处理。 |
| One-time micro-batch (一次性微批) | Trigger.Once() | 仅执行一次 |
| Continuous with fixed checkpoint interval(连续处理) | Trigger.Continuous(long interval, TimeUnit timeUnit) | 以固定的Checkpoint间隔(interval)连续处理。在这种模式下,连续处理引擎将每隔一定的间隔(interval)做一次checkpoint,可获得低至1ms的延迟。但只保证 at-least-once |
为什么continuous只支持at-least-once
df.writeStream
.format("console")
.trigger(continuous='1 second')
.start()
注意这里的 1 second 指的是每隔 1 秒记录保存一次状态,而不是说每隔 1 秒才处理数据
continuous 不再是周期性启动 task,而是启动长期运行的 task,也不再是处理一批数据,而是不断地一个数据一个数据地处理,并且也不用每次都记录偏移,而是异步地,周期性的记录状态,这样就能实现低延迟.
综上,continuous模式下长期运行一个task,而不会实时去记录offset,所以不能保证eactly-once.
三种批次方式的验证
1.Interval micro-batch(固定间隔的微批)
`{
Logger.getRootLogger().setLevel(Level.ERROR);
Logger.getLogger(StructuredSparing.class).setLevel(Level.ERROR);
SparkSession session = SparkSession
.builder()
.master("local")
.config("spark.sql.streaming.checkpointLocation", "D://checkpoint")
.getOrCreate();
Dataset<Row> stream = session.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test")
.load();
StreamingQuery query = stream.writeStream()
.queryName("StructuredSparingTest")
.format("console")
.trigger(Trigger.ProcessingTime(5, TimeUnit.SECONDS))
.start();
try {
query.awaitTermination();
} catch (StreamingQueryException e) {
e.printStackTrace();
}
}`
设置为5秒一个批次。
通过UI界面可以很直观地看出,在有数据的时候5秒一个批次,在没有数据的时候,10秒甚至3分钟才执行一个批次。
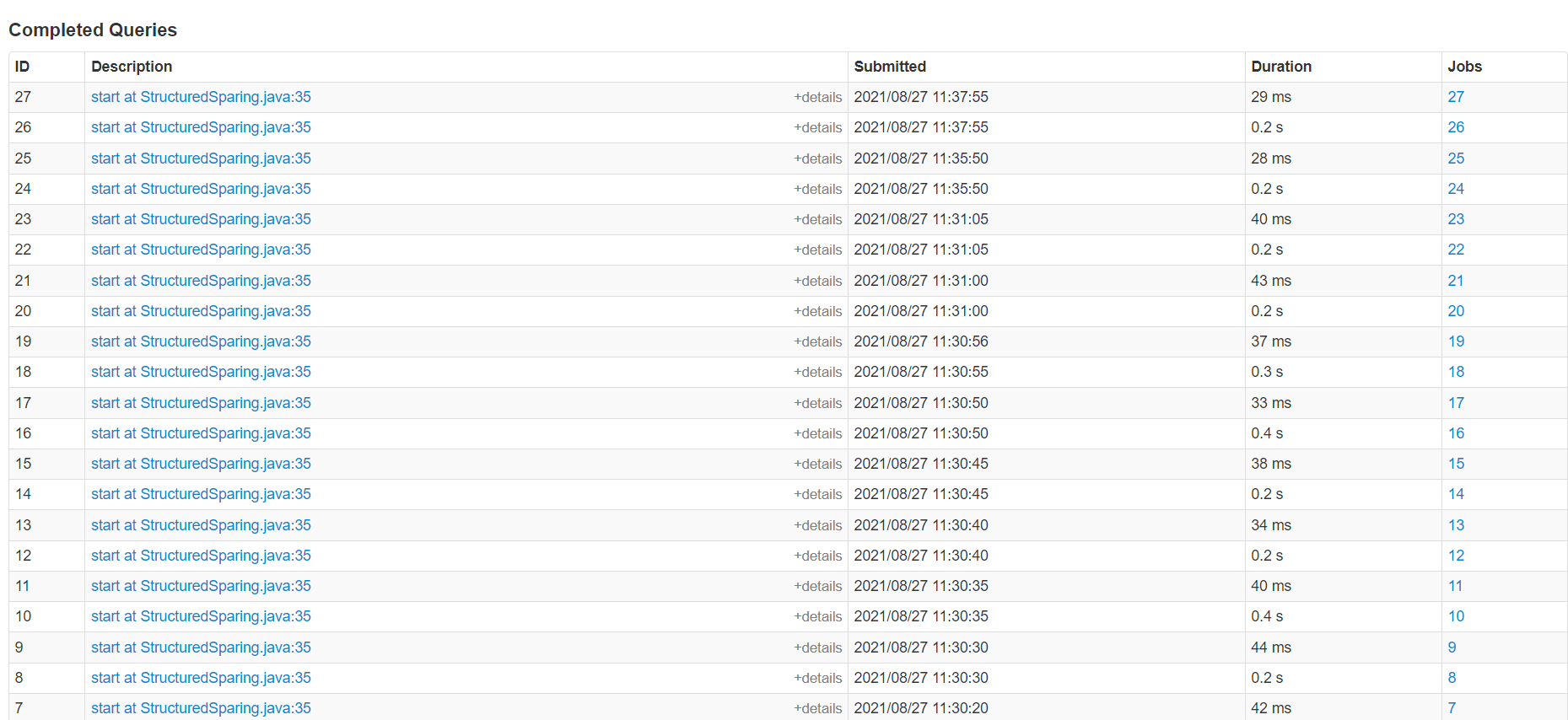
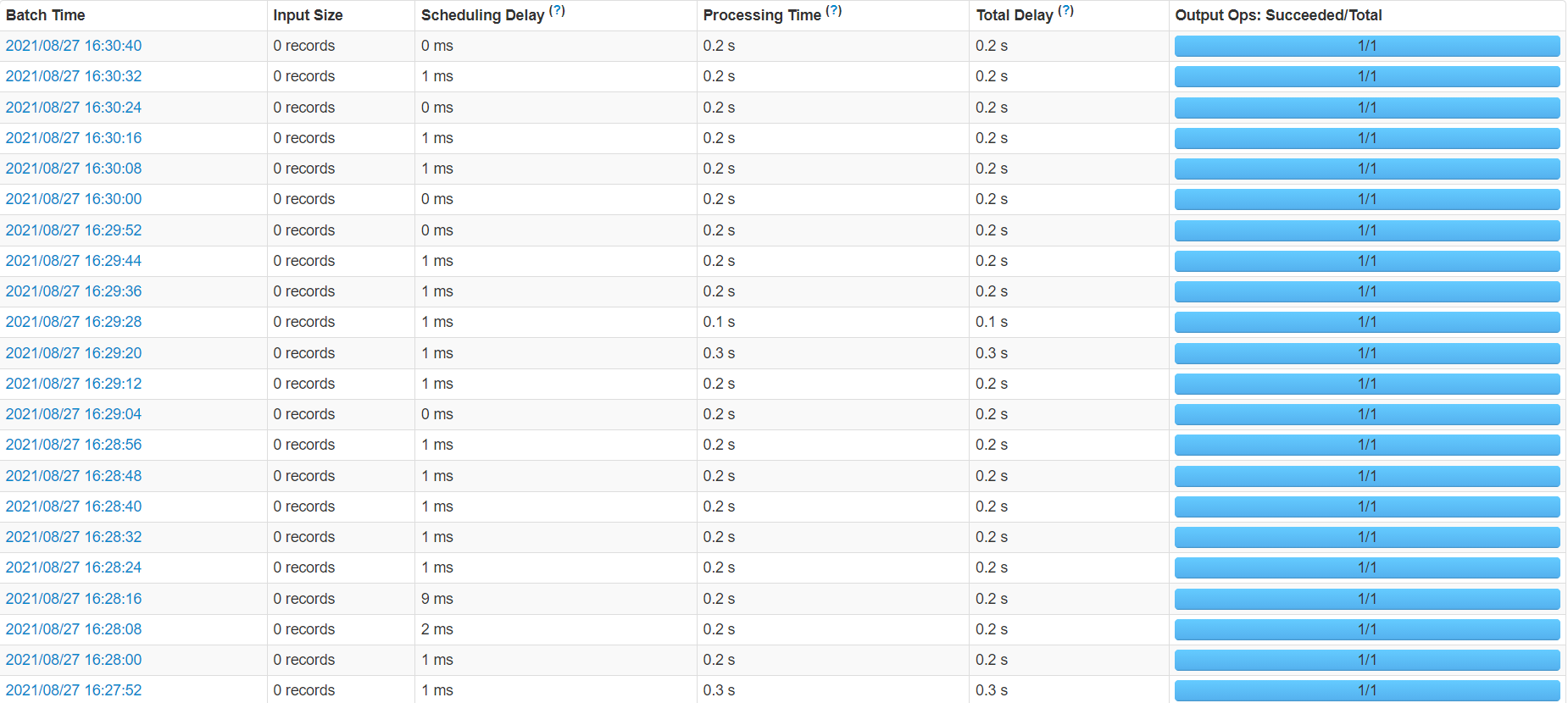
通过与spark streaming进行比较可以更加直观.在spark streaming里设置8秒一个批次,在UI界面可以看到,不管有无数据,spark streaming严格按照8秒的批次执行。
2.One-time micro-batch (一次性微批)
.trigger(Trigger.Once())
执行结果,略。
3.Continuous方式
.trigger(Trigger.Continuous(100,TimeUnit.MILLISECONDS))
设置100毫秒一个执行批次,通过UI界面可以看出,时间已经1.2分钟,但是active job一直只有一个,一直在running,证明启动了一个长期运行的task,不断地一批数据一批数据连续处理。

structed streaming 触发器trigger的更多相关文章
- mysql之触发器trigger
触发器(trigger):监视某种情况,并触发某种操作. 触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/befo ...
- mysql之触发器trigger 详解
为了梦想,努力奋斗! 追求卓越,成功就会在不经意间追上你 mysql之触发器trigger 触发器(trigger):监视某种情况,并触发某种操作. 触发器创建语法四要素:1.监视地点(table) ...
- mysql之触发器trigger(1)
触发器(trigger):监视某种情况,并触发某种操作. 触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/befo ...
- 如何使用MySQL触发器trigger
阅读目录:触发器trigger的使用 创建触发器 单一执行语句.多执行语句 new.old详解 查看触发器 删除触发器:慎用触发器,不用就删除 Q:什么是触发器? A: 触发器是与表有关的数据库对象, ...
- mysql 触发器(trigger)
触发器(trigger):监视某种情况,并触发某种操作. 触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/befo ...
- SQL入门(3):定义约束/断言assertion/触发器trigger
本文介绍数据库的完整性 完整性控制程序: 指定规则,检查规则 (规则就是约束条件) 动态约束 intergrity constraint::=(O,P,A,R) O : 数据集合, 约束的对象 ?: ...
- mysql触发器trigger 实例详解
mysql触发器trigger 实例详解 (转自 https://www.cnblogs.com/phpper/p/7587031.html) MySQL好像从5.0.2版本就开始支持触发器的功能 ...
- 04 Zabbix4.0系统配置触发器trigger
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 04 Zabbix4.0系统配置触发器trigger 请点击查看Zabbix3.0.8版本trig ...
- WPF触发器(Trigger)
WPF触发器(Trigger.DataTrigger.EventTrigger) WPF中有种叫做触发器的东西(记住不是数据库的trigger哦).它的主要作用是根据trigger的不同条件来自动更改 ...
- mysql 触发器 trigger用法 two (稍微复杂的)
触发器(trigger):监视某种情况,并触发某种操作. 触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/befo ...
随机推荐
- mysql 不包含某个字符
转载网址: https://blog.csdn.net/mp624183768/article/details/121696040?utm_medium=distribute.pc_relevant. ...
- win10、win11安装子系统kali linux、图形化界面的安装
1.开启安装Linux子系统需要的扩展 Win+Q搜索功能 勾选需要的扩展,Hyper-V.Windows 虚拟机监控平台.适用于Linux的Windows子系统.虚拟机平台 反正这些有关于虚拟机的全 ...
- 在golang中如何正确判断接口是否为nil
本文主要来分析一下在golang中,如何判断interface是否为nil,以及相关注意事项. 正常情况下,我们声明一个interface类型的变量,默认值将会返回nil,以golang自带的io.W ...
- find和filter有什么区别
JavaScript 在 ES6 上有很多数组方法,每种方法都有独特的用途和好处. 在开发应用程序时,大多使用数组方法来获取特定的值列表并获取单个或多个匹配项. 在列出这两种方法的区别之前,我们先来一 ...
- 2020寒假学习笔记13------Python基础语法学习(二)
同一运算符 同一运算符用于比较两个对象的存储单元,实际比较的是对象的地址. 运算符 描述 is is 是判断两个标识符是不是引用同一个对象 is not is not 是判断两个标识符是不是引用 ...
- 柏林噪声算法(Perlin Noise)
概述 引述维基百科的介绍: Perlin噪声(Perlin noise,又称为柏林噪声)指由Ken Perlin发明的自然噪声生成算法,具有在函数上的连续性,并可在多次调用时给出一致的数值. 在电子游 ...
- 【命令设计模式详解】C/Java/JS/Go/Python/TS不同语言实现
简介 命令模式(Command Pattern)是一种数据驱动的设计模式,也是一种行为型设计模式.这种模式的请求以命令的形式包裹在对象中,并传给调用对象.调用对象再寻找合适的对象,并把该命令传给相应的 ...
- GaussDB(DWS)网络调度与隔离管控能力
摘要:调度算法是调度器的核心,设计调度算法要充分考虑业务场景和用户需求,没有万能的调度算法,只有合适的调度算法. 本文分享自华为云社区<GaussDB(DWS)网络调度与隔离管控能力>,作 ...
- [Linux]Linux大文件已删除,但df查看已使用的空间并未减少解决【待续】
1 问题描述 X 参考文献 Linux大文件已删除,但df查看已使用的空间并未减少解决 - ChinaUnix linux磁盘空间未及时释放 - 博客园 linux磁盘目录占用空间分析工具之ncdu ...
- [ElasticSearch]常用URL路径
https://127.0.0.1:9200/ http://127.0.0.1:9200/_all?pretty https://127.0.0.1:9200/_cluster/health?pre ...