【三】tensorboard安装、使用教学以及遇到的问题
相关文章:
【一】tensorflow安装、常用python镜像源、tensorflow 深度学习强化学习教学
【二】tensorflow调试报错、tensorflow 深度学习强化学习教学
trick1---实现tensorflow和pytorch迁移环境教学
1.tensorflow 深度学习
 书本链接:https://download.csdn.net/download/sinat_39620217/16491144
书本链接:https://download.csdn.net/download/sinat_39620217/16491144
对应码源以及学习资料链接:https://gitee.com/dingding962285595/tensorflow_-rl 欢迎关注一键三连哦!
2.tensorboard安装
TensorBoard是一个可视化工具,能展示你训练过程中绘制的图像、网络结构等。设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用TensorBoader可以很直观的帮我们进行参数的选择。
在anacondaprompt环境下安装tensorboard,分为两步:
conda activate tensorflow
pip install tensorboard -i 镜像源这里镜像源可以参考我【一】tensorflow安装、常用python镜像源、tensorflow 深度学习强化学习教学 中的。
3.tensorboard使用教学
下面开始小试牛刀,测试demo
import tensorflow as tf
import numpy as np #输入数据
x_data = np.linspace(-1,1,300)[:, np.newaxis]
noise = np.random.normal(0,0.05, x_data.shape)
y_data = np.square(x_data)-0.5+noise #输入层
with tf.name_scope('input_layer'): #输入层。将这两个变量放到input_layer作用域下,tensorboard会把他们放在一个图形里面
xs = tf.placeholder(tf.float32, [None, 1], name = 'x_input') # xs起名x_input,会在图形上显示
ys = tf.placeholder(tf.float32, [None, 1], name = 'y_input') # ys起名y_input,会在图形上显示 #隐层
with tf.name_scope('hidden_layer'): #隐层。将隐层权重、偏置、净输入放在一起
with tf.name_scope('weight'): #权重
W1 = tf.Variable(tf.random_normal([1,10]))
tf.summary.histogram('hidden_layer/weight', W1)
with tf.name_scope('bias'): #偏置
b1 = tf.Variable(tf.zeros([1,10])+0.1)
tf.summary.histogram('hidden_layer/bias', b1)
with tf.name_scope('Wx_plus_b'): #净输入
Wx_plus_b1 = tf.matmul(xs,W1) + b1
tf.summary.histogram('hidden_layer/Wx_plus_b',Wx_plus_b1)
output1 = tf.nn.relu(Wx_plus_b1) #输出层
with tf.name_scope('output_layer'): #输出层。将输出层权重、偏置、净输入放在一起
with tf.name_scope('weight'): #权重
W2 = tf.Variable(tf.random_normal([10,1]))
tf.summary.histogram('output_layer/weight', W2)
with tf.name_scope('bias'): #偏置
b2 = tf.Variable(tf.zeros([1,1])+0.1)
tf.summary.histogram('output_layer/bias', b2)
with tf.name_scope('Wx_plus_b'): #净输入
Wx_plus_b2 = tf.matmul(output1,W2) + b2
tf.summary.histogram('output_layer/Wx_plus_b',Wx_plus_b2)
output2 = Wx_plus_b2 #损失
with tf.name_scope('loss'): #损失
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-output2),reduction_indices=[1]))
tf.summary.scalar('loss',loss)
with tf.name_scope('train'): #训练过程
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) #初始化
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
merged = tf.summary.merge_all() #将图形、训练过程等数据合并在一起
writer = tf.summary.FileWriter('logs',sess.graph) #将训练日志写入到logs文件夹下 #训练
for i in range(1000):
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if(i%50==0): #每50次写一次日志
result = sess.run(merged,feed_dict={xs:x_data,ys:y_data}) #计算需要写入的日志数据
writer.add_summary(result,i) #将日志数据写入文件其中:writer = tf.summary.FileWriter('logs',sess.graph) #将训练日志写入到logs文件夹下
小trick
打开对应目录的命令程序
tensorboard --logdir=logs

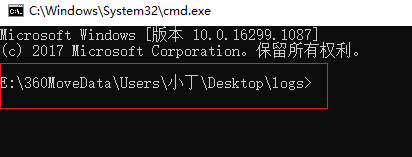

或者:.打开对应路径:比如进入D盘 d:就可以不用cd,.进入d盘路径后,再cd D:\work_place,.复制地址 http://localhost:6006/到浏览器
- 编译执行,会生成log文件
- 找到log文件(在xxx文件夹下,打开cmd)
- tensorboard --logdir=logs ->其中logs为保存log文件的文件夹
重要提示:请不要用中文命名目录,中文目录中看不到任何图形。
得到结果:



4.tensorboard常用语法--summary
tf.summary有诸多函数:
1、tf.summary.scalar
用来显示标量信息,其格式为:
tf.summary.scalar(tags, values, collections=None, name=None)例如:tf.summary.scalar('mean', mean),一般在画loss,accuary时会用到这个函数。
2、tf.summary.histogram
用来显示直方图信息,其格式为:
tf.summary.histogram(tags, values, collections=None, name=None) 例如: tf.summary.histogram('histogram', var),一般用来显示训练过程中变量的分布情况
3、tf.summary.merge_all
merge_all 可以将所有summary全部保存到磁盘,以便tensorboard显示。如果没有特殊要求,一般用这一句就可一显示训练时的各种信息了。
格式:tf.summaries.merge_all(key='summaries')
4、tf.summary.FileWriter
指定一个文件用来保存图。
格式:tf.summary.FileWritter(path,sess.graph),可以调用其add_summary()方法将训练过程数据保存在filewriter指定的文件中
Tensorflow Summary 用法示例:
tf.summary.scalar('accuracy',acc) #生成准确率标量图
merge_summary = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(dir,sess.graph)#定义一个写入summary的目标文件,dir为写入文件地址
......(交叉熵、优化器等定义)
for step in xrange(training_step): #训练循环
train_summary = sess.run(merge_summary,feed_dict = {...})#调用sess.run运行图,生成一步的训练过程数据
train_writer.add_summary(train_summary,step)#调用train_writer的add_summary方法将训练过程以及训练步数保存 此时开启tensorborad:
tensorboard --logdir=/summary_dir 便能看见accuracy曲线了。
另外,如果我不想保存所有定义的summary信息,也可以用tf.summary.merge方法有选择性地保存信息:
5、tf.summary.merge
格式:tf.summary.merge(inputs, collections=None, name=None)
一般选择要保存的信息还需要用到tf.get_collection()函数,demo:
tf.summary.scalar('accuracy',acc) #生成准确率标量图
merge_summary = tf.summary.merge([tf.get_collection(tf.GraphKeys.SUMMARIES,'accuracy'),...(其他要显示的信息)])
train_writer = tf.summary.FileWriter(dir,sess.graph)#定义一个写入summary的目标文件,dir为写入文件地址
......(交叉熵、优化器等定义)
for step in xrange(training_step): #训练循环
train_summary = sess.run(merge_summary,feed_dict = {...})#调用sess.run运行图,生成一步的训练过程数据
train_writer.add_summary(train_summary,step)#调用train_writer的add_summary方法将训练过程以及训练步数保存 使用tf.get_collection函数筛选图中summary信息中的accuracy信息,这里的tf.GraphKeys.SUMMARIES 是summary在collection中的标志。
或者:
acc_summary = tf.summary.scalar('accuracy',acc) #生成准确率标量图
merge_summary = tf.summary.merge([acc_summary ,...(其他要显示的信息)]) #这里的[]不可省如果要在tensorboard中画多个数据图,需定义多个tf.summary.FileWriter并重复上述过程。
【三】tensorboard安装、使用教学以及遇到的问题的更多相关文章
- Appium移动自动化测试(三)--安装Android模拟器
当Android SDK安装完成之后,并不意味着已经装好了安装模拟器.Android系统有多个版本,所以我们需要选择一个版本进行安装. 第三节 安装Android 模拟器 我这里以Android 4 ...
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone单 机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守 ...
- 第1章(三)安装VS2015和Xamarin For VS
原文 第1章(三)安装VS2015和Xamarin For VS 操作系统:Win7 64位(sp1或更高版本) 1.安装VS2015 VS2015简体中文企业版:vs2015.ent_chs.is ...
- Appium移动自动化测试(三)--安装Android模拟器(转)
Appium移动自动化测试(三)--安装Android模拟器 2015-06-08 10:33 by 虫师, 30828 阅读, 9 评论, 收藏, 编辑 当Android SDK安装完成之后,并不意 ...
- Appium移动自动化测试(三)--安装Android模拟器(建议直接连手机,跳过此步)
转自虫师,亲测有效,留备后用. 本文中如果直接安装时不出现错误,则可以忽略(一.二.三.四.五),我安装的是5.1.1,直接成功,就是有点慢,要有耐心. 如果到最后一步,启动不起来,报错: emula ...
- 三、安装cmake,安装resin ,tars服务,mysql 安装介绍,安装jdk,安装maven,c++ 开发环境安装
三.安装cmake,安装resin 2018年07月01日 21:32:05 youz1976 阅读数:308 开发环境说明: centos7.2 ,最低配置:1核cpu,2G内存,1M带宽 1. ...
- 【转】Appium移动自动化测试(三)--安装Android模拟器
原文出自:http://www.cnblogs.com/fnng/p/4560298.html?utm_source=tuicool 当Android SDK安装完成之后,并不意味着已经装好了安装模拟 ...
- 三个安装,手机看VIP电影。写给亲爱的学习
三个安装,看VIP电影. 市场安装firefox 安装Tempermonkey 打开firefox,点击右上角的三个点,点击附加组件 继续点击浏览全部firefox附加组件 在上面的搜索框输入 tam ...
- grub安装的 三种安装方式
1. 引言 grub是什么?最常态的理解,grub是一个bootloader或者是一个bootmanager,通过grub可以引导种类丰富的系统,如linux.freebsd.windows等.但一旦 ...
- 【转】vue.js三种安装方式
Vue.js(读音 /vjuː/, 类似于 view)是一个构建数据驱动的 web 界面的渐进式框架.Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件.它不仅易于上手 ...
随机推荐
- 发布会回放|Gradio 4.0 正式发布!
Gradio 的目标是使机器学习模型的演示更容易定制和访问,以满足不同用户的需求.在 4.0 正式版的发布活动上,Hugging Face 的 Gradio 团队介绍了自己为了提高机器学习模型的可访问 ...
- Python最佳实践书籍《Python 工匠》摘要
<Python工匠>是一本案例.技巧与工程实践的指导书,该书不是python基础语法的教程,而是python中最佳实践的教程,属于python进阶类的书籍.可以将本书当做PEP8编程规范的 ...
- 一个NASA、Google都在用的开源CMS:wagtail
说起开源CMS,你会想到哪些呢?WordPress?DoraCMS?joomla? 今天再给大家推荐一个非常好用的开源CMS:Wagtail 如果您正在选型的话,可以了解一下Wagtail的特点: 基 ...
- HDU-3032--Nim or not Nim?(博弈+SG打表)
题目分析: 这是一个经典的Multi-SG游戏的问题. 相较于普通的Nim游戏,该游戏仅仅是多了拆成两堆这样的一个状态.即多了一个SG(x+y)的过程. 而根据SG定理,SG(x+y)这个游戏的结果可 ...
- 用ArcGIS模型构建器生成、导出Python转换空间坐标系的代码
本文介绍在ArcMap软件中,通过创建模型构建器(ModelBuilder),导出地理坐标系与投影坐标系之间相互转换的Python代码的方法. 在GIS领域中,矢量.栅格图层的投影转换是一个经 ...
- 叮~OpenSCA社区拍了拍您并发来一份开源盛会邀请函
2023数字供应链安全大会(DSS 2023)将于8月10日在北京·国家会议中心举办.本次大会以"开源的力量"为主题,由悬镜安全主办,ISC互联网安全大会组委会.中国软件评测中心( ...
- 活动回顾|阿里云 Serverless 技术实战与创新广州站回放&PPT下载
7月8日"阿里云 Serverless 技术实战与创新"广州站圆满落幕.活动受众以关注Serverless 技术的开发者.企业决策人.云原生领域创业者为主,活动形式为演讲.动手实操 ...
- <vue 基础知识 8、购物车样例>
代码结构 一. 效果 1. 展示列表v-for 2. 购买数量增加减少,使用@click触发回调函数. 减少的时候如果已经为1了就不让继续减少,使用了v-bind绑定属性 3. 移除也是使用@ ...
- 【CubeMX】使用 CubeMX 生成对应的配置代码需要设置 “User Label”
如要生成 SPI 的管脚配置代码,需要设置 User Label,这样工具才能知道应该配置什么,否则不会生成
- java - 字节流读取文件
package stream; import java.io.*; public class InputStreamReaderString { public static void main(Str ...