基于知识图谱的电影知识问答系统:训练TF-IDF 向量算法和朴素贝叶斯分类器、在 Neo4j 中查询
基于知识图谱的电影知识问答系统:训练TF-IDF 向量算法和朴素贝叶斯分类器、在 Neo4j 中查询
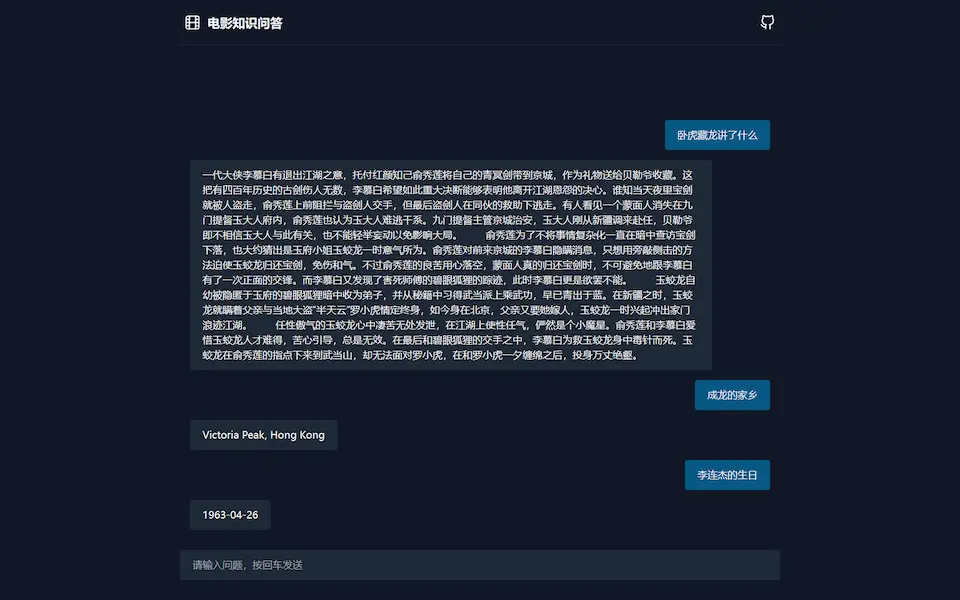
1.项目介绍
- 训练 TF-IDF 向量算法和朴素贝叶斯分类器,预测用户文本所属的问题类别
- 使用分词库解析用户文本词性,提取关键词
- 结合关键词与问题类别,在 Neo4j 中查询问题的答案
- 通过 Flask 对外提供 RESTful API
- 前端交互与答案展示
2.项目实操教学
2.1 数据集简介
{
"introduction_by_movie": [
"nm简介",
"nm剧情简介",
"nm的内容是什么",
"nm讲了什么",
"nm讲了什么故事",
"nm演了什么",
"nm的故事梗概是什么",
"nm的剧情简介是什么",
"nm的内容简介是什么",
"nm的剧情介绍是什么",
"nm的情节是什么",
"nm的主要情节是什么"
],
"rating_by_movie": [
"nm的评分是多少",
"nm得了多少分",
"nm的评分有多少",
"nm的评分",
"nm得分是多少",
"nm的分数是",
"nm电影分数是多少",
"nm电影评分",
"nm评分",
"nm的分数是多少",
"nm这部电影的评分是多少"
],
"release_date_by_movie": [
"nm上映时间",
"nm定档时间",
"nm的上映时间是什么时候",
"nm的首映时间是什么时候",
"nm什么时候上映",
"nm什么时候首映",
"最早什么时候能看到nm",
"nm什么时候在影院上线",
"什么时候可以在影院看到nm",
"nm什么时候在影院放映",
"nm什么时候首播"
],
2.2 用户词典
Forrest Gump nm
Kill Bill: Vol. 1 nm
英雄 nm
Miami Vice nm
Indiana Jones and the Temple of Doom nm
卧虎藏龙 nm
Pirates of the Caribbean: At World's End nm
Kill Bill: Vol. 2 nm
The Matrix Reloaded nm
The Matrix Revolutions nm
Harry Potter and the Chamber of Secrets nm
Harry Potter and the Prisoner of Azkaban nm
Harry Potter and the Goblet of Fire nm
Harry Potter and the Order of the Phoenix nm
The Last Emperor nm
Harry Potter and the Half-Blood Prince nm
花样年华 nm
2046 nm
Lethal Weapon 4 nm
Hannibal Rising nm
TMNT nm
무사 nm
Anna and the King nm
满城尽带黄金甲 nm
2.3 环境依赖
jieba
neo4j
python-dotenv
scikit-learn
flask
flask-cors
gunicorn
2.4 部分代码展示
import os
from neo4j import GraphDatabase
class Database:
"""
Neo4j 数据库访问层。
管理数据库连接的生命周期,并提供查询接口。
"""
def __init__(self):
uri = os.environ["DATABASE_URI"]
user = os.environ["DATABASE_USER"]
password = os.environ["DATABASE_PASSWORD"]
try:
self._driver = GraphDatabase.driver(uri, auth=(user, password))
self._session = self._driver.session()
except Exception as e:
raise Exception("数据库连接失败") from e
def close(self):
try:
self._session.close()
self._driver.close()
except Exception as e:
raise Exception("数据库断开失败") from e
def find_one(self, query: str, **parameters):
result = self._session.run(query, parameters).single()
return result.value() if result else None
def find_many(self, query: str, **parameters):
return self._session.run(query, parameters).value()
if __name__ == "__main__":
import dotenv
dotenv.load_dotenv()
database = Database()
genres = database.find_many(
"""
MATCH (m:Movie)-[BELONGS_TO]->(g:Genre)
WHERE m.name = $movie_name
RETURN g.name
""",
movie_name="卧虎藏龙",
)
database.close()
print(genres)
import json
import os
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
TRAIN_DATASET_PATH = os.path.join("data", "train.json")
jieba.setLogLevel("ERROR")
def normalize(sentence: str):
return " ".join(jieba.cut(sentence))
class BaseClassifier:
"""
底层分类器。
使用 TF-IDF 向量化文本,然后使用朴素贝叶斯预测标签。
"""
def __init__(self):
self._vectorizer = TfidfVectorizer()
self._classifier = MultinomialNB(alpha=0.01)
def _train(self, x: list, y: list):
X = self._vectorizer.fit_transform(x).toarray()
self._classifier.fit(X, y)
def _predict(self, x: list):
X = self._vectorizer.transform(x).toarray()
return self._classifier.predict(X)
class Classifier(BaseClassifier):
"""
问题分类器。
根据问题中出现的关键词,将问题归于某一已知类别下。
"""
def __init__(self):
BaseClassifier.__init__(self)
questions, labels = Classifier._read_train_dataset()
self._train(questions, labels)
def classify(self, sentence: str):
question = normalize(sentence)
return self._predict([question])[0]
@staticmethod
def _read_train_dataset():
with open(TRAIN_DATASET_PATH, "r", encoding="utf-8") as fr:
train_dataset: dict[str, list[str]] = json.load(fr)
questions = []
labels = []
for label, sentences in train_dataset.items():
questions.extend([normalize(sentence) for sentence in sentences])
labels.extend([label for _ in sentences])
return questions, labels
if __name__ == "__main__":
classifier = Classifier()
while True:
sentence = input("请输入问题:").strip()
label = classifier.classify(sentence)
print(f"问题分类:{label}")
2.5 运行项目
在 backend 目录下添加环境变量文件 .env。
# Neo4j 数据库地址
DATABASE_URI=
# Neo4j 用户名
DATABASE_USER=
# Neo4j 密码
DATABASE_PASSWORD=
启动后端服务。
cd backend
gunicorn app:app
在 frontend 目录下添加环境变量文件 .env。
# 后端服务地址
VITE_API_BASE_URL=
启动前端服务。
cd frontend
npm build
npm preview
3.技术栈
3.1数据库
3.2核心 QA 模块
3.3后端
3.4前端
TypeScript
Preact
Tailwind CSS
pnpm
Vite
ESLint
Prettier
码源链接跳转见文末
更多优质内容请关注公号&知乎:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。


基于知识图谱的电影知识问答系统:训练TF-IDF 向量算法和朴素贝叶斯分类器、在 Neo4j 中查询的更多相关文章
- 使用LSTM做电影评论负面检测——使用朴素贝叶斯才51%,但是使用LSTM可以达到99%准确度
基本思路: 每个评论取前200个单词.然后生成词汇表,利用词汇index标注评论(对 每条评论的前200个单词编号而已),然后使用LSTM做正负评论检测. 代码解读见[[[评论]]]!embeddin ...
- 贝叶斯--旧金山犯罪分类预测和电影评价好坏 demo
来源引用:https://blog.csdn.net/han_xiaoyang/article/details/50629608 1.引言 贝叶斯是经典的机器学习算法,朴素贝叶斯经常运用于机器学习的案 ...
- 知识图谱+Recorder︱中文知识图谱API与工具、科研机构与算法框架
目录 分为两个部分,笔者看到的知识图谱在商业领域的应用,外加看到的一些算法框架与研究机构. 文章目录 @ 一.知识图谱商业应用 01 唯品金融大数据 02 PlantData知识图谱数据智能平台 03 ...
- 基于知识图谱的APT组织追踪治理
高级持续性威胁(APT)正日益成为针对政府和企业重要资产的不可忽视的网络空间重大威胁.由于APT攻击往往具有明确的攻击意图,并且其攻击手段具备极高的隐蔽性和潜伏性,传统的网络检测手段通常无法有效对其进 ...
- 知识图谱里的知识存储:neo4j的介绍和使用
一般情况下,我们使用数据库查找事物间的联系的时候,只需要短程关系的查询(两层以内的关联).当需要进行更长程的,更广范围的关系查询时,就需要图数据库的功能. 而随着社交.电商.金融.零售.物联网等行 ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- darktrace 亮点是使用的无监督学习(贝叶斯网络、聚类、递归贝叶斯估计)发现未知威胁——使用无人监督 机器学习反而允许系统发现罕见的和以前看不见的威胁,这些威胁本身并不依赖 不完善的训练数据集。 学习正常数据,发现异常!
先说说他们的产品:企业免疫系统(基于异常发现来识别威胁) 可以看到是面向企业内部安全的! 优点整个网络拓扑的三维可视化企业威胁级别的实时全局概述智能地聚类异常泛频谱观测 - 高阶网络拓扑;特定群集,子 ...
- tf idf公式及sklearn中TfidfVectorizer
在文本挖掘预处理之向量化与Hash Trick中我们讲到在文本挖掘的预处理中,向量化之后一般都伴随着TF-IDF的处理,那么什么是TF-IDF,为什么一般我们要加这一步预处理呢?这里就对TF-IDF的 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
随机推荐
- 引用 AspNetCoreRateLimit => StatusCode cannot be set because the response has already started.
app.UseIpRateLimiting(); #需要放在前面,否则抓去不准,还有可能会出现下列错误 本次出现这个错误,是因为 .Net Core 跨域 里面的这行:httpContext.Res ...
- AtCoder Regular Contest 124
比赛链接:Here A - LR Constraints 赛时做这个好迷啊,英文题面解释不清楚,还是看了日语原文才搞懂 \(n\) 个卡牌上有两个 字符 + 数字 组合,L 的右边所有元素 + 1,R ...
- 应届生必读:Java真实项目的开发流程和常用工具
本文出自本人写的书,谢绝转载,更勿抄袭. 本人有多年的Java面试官经验,经常要和一些包装项目经验的求职者打交道.当然平时也兼职做些Java面试辅导工作,最近也陆续帮一些在校生朋友成功找到Java工作 ...
- C#利用折线图分析产品销售走势
图形界面 数据 查询效果 代码 private void button1_Click(object sender, EventArgs e) { G++; DrowFont(this.comboBox ...
- node pressure and pod eviction
0. overview There are too many guides about node pressure and pod eviction, most of them are specifi ...
- Java之利用openCsv导出csv文件
当时导入的时候用的openCsv,那么导出的时候自然也是用这个,查了好多资料才找到解决方案,下面记录一下实现过程. 1.Controller层: /** * 导出csv文件 */ @RequestMa ...
- 使用Spring Data JPA实现审计功能,记录创建人、创建时间、最后修改时间和最后修改人
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- WPF|如何在 WPF 中设计漂亮的社交媒体信息仪表板
1. 效果展示 先来直接欣赏效果: 2. 准备 创建一个WPF工程,比如站长使用 .NET 7 创建名为 Dashboard3 的WPF项目,添加一些图片资源,项目目录如下: 2.1 图片资源 可在网 ...
- 【C/C++】sscanf函数和正则表达式
此文所有的实验都是基于下面的程序:char str[10];for (int i = 0; i < 10; i++) str[i] = '!';执行完后str的值为str = "!!! ...
- 面试官:小伙子来说一说Java中final关键字,以及它和finally、finalize()有什么区别?
写在开头 面试官:"小伙子,用过final关键字吗?" 我:"必须用过呀" 面试官:"好,那来说一说你对这个关键字的理解吧,再说一说它与finally ...