Diffusers 一岁啦 !
十分高兴 Diffusers 迎来它的一岁生日!这是令人激动的一年,感谢社区和开源贡献者,我们对我们的工作感到十分骄傲和自豪。去年,文本到图像的模型,如 DALL-E 2, Imagen, 和 Stable Diffusion 以其从文本生成逼真的图像的能力,吸引了全世界的关注,也带动了对生成式 AI 的大量兴趣和开发工作。但是这些强大的工作不易获取。
在 Hugging Face, 我们的使命是一起通过相互合作和帮助,构建一个开放和有道德的 AI 未来,让机器学习民主化。我们的使命促使我们创造了 Diffusers 库,让 每个人 能实验,研究,或者尝试文本到图像的生成模型。这便是我们设计这个模块化的库的初衷,你可以个性化扩散模型的某个部分,或者仅仅是开箱即用。
作为 Diffusers 的第一个版本,下面是在社区的帮助下,我们加入的最值得一提的特性。我们对作社区的一员,提高功能性,推动扩散模型不局限于文本到图像的生成,感到骄傲和感激。
目录
- 提高逼真性
- 视频生成
- 文本到 3D 模型生成
- 图像编辑
- 加速扩散模型
- 种族偏见和安全性
- 对 LoRA 的支持
- 基于 Torch 2.0 的优化
- 社区贡献
- 基于 Diffusers 的产品
- 展望
提高逼真性
众所周知,生成模型能生成逼真的图像,但如果你凑近看,绝对能发现某些瑕疵,比如多余的手指。今年,DeepFloyd IF 和 Stability AI SDXL 模型给出了让生成图像更逼真的方法。
DeepFloyd IF - 一个分步生成图片的模块化扩散模型 (比如,一个图片被三倍地上采样以提高分辨率),不像 Stable Diffusion,IF 模型直接在像素层次上操作,并采用一个大语言模型来编码文本。
Stable Diffusion XL (SDXL) - Stability AI 的最前沿的 Stable Diffusion 模型,和之前的 Stable Diffusion 2 相比,参数量显著地增加了。它能生成超真实的图片,先用一个基础模型让图像很接近输入提示词,然后用一个改善模型专门提高细节和高频率的内容。
现在就去查阅 DeepFloyd IF 的 文档 和 SDXL 的 文档,然后生成你自己的图片吧!
视频生成
文本到图像很酷,但文本到视频更酷!我们现在能支持两种文本到视频的方法: VideoFusion 和 Text2Video-Zero。
如果你对文本到图像的流程熟悉,那么文本到视频也一样:
import torch
from diffusers import DiffusionPipeline
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("cerspense/zeroscope_v2_576w", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
prompt = "Darth Vader surfing a wave"
video_frames = pipe(prompt, num_frames=24).frames
video_path = export_to_video(video_frames)

我们期待文生视频能在 Diffusers 的第二年迎来革命,也十分激动能看到社区在此之上的工作,进一步推进视频生成领域的进步!
文本到 3D
除了文本到视频,我们也提供了文本到 3D 的生成模型,多亏了 OpenAI 的 Shap-E 模型。Shap-E 在大量 3D 和文本的数据对上以编码的形式训练,在编码器的输出层条件化了一个扩散模型。你用它可以为游戏,内部设计和建筑生成 3D 资产。
现在就尝试 ShapEPipeline 和 ShapEImg2ImgPipeline 吧。

图像编辑
图像编辑是在时尚,材料设计和摄影领域最实用的功能之一。而图片编辑的可能性被扩散模型进一步增加。
在 Diffusers 中,我们提供了许多 流水线 用来做图像编辑。有些图像编辑流水线能根据你的提示词从心所欲地修改图像,从图片中移除某个概念,甚至有流水线综合了很多创造高质量图片 (如全景图) 的生成方法。用 Diffusers,你现在就可以体验未来的图片编辑技术!
更快的扩散模型
众所周知,扩散模型以其迭代的过程而耗时。利用 OpenAI 的 Consistency Models,图像生成流程的速度有显著提高。生成单张 256x256 分辨率的图片,现在在一张 CPU 上只要 3/4 秒!你可以在 Diffusers 上尝试 ConsistencyModelPipeline。
在更快的扩散模型之外,我们也提供许多面向更快推理的技术,比如 PyTorch 2.0 的 scaled_dot_product_attention() (SDPA) 和 torch.compile(), sliced attention, feed-forward chunking, VAE tiling, CPU and model offloading, 以及更多。这些优化节约内存,加快生成,允许你能在客户端 GPU 上运行。当你用 Diffusers 部署一个模型,所有的优化都即刻支持!
除此外,我们也支持具体的硬件格式如 ONNX,Pytorch 中 Apple 芯片的 mps 设备,Core ML 以及其他的。
欲了解更多关于 Diffusers 的优化,请查看 文档!
道德和安全
生成模型很酷,但是它们也很容易生成有害的和 NSFW 内容,为了帮助用户负责和有道德地使用这些模型,我们添加了 safety_checker 模块来标记生成内容中不合适的。模型的创造者可以决定是加入留该模块。
另外,生成模型也能生成误导性的信息,今年早些时候,Balenciaga Pope
以画面真实如病毒般传播,虽然是虚假的。这呼吁了我们区分生成的和真实的内容的重要性。这便是我们对 SDXL 模型的生成内容添加一个不可见水印的原因,以帮助用户更好地辨别。
这些特性的开发都是由我们的 ethical charter 主持,你能在我们的文档中看到。
对 LoRA 的支持
对扩散模型的微调是昂贵,且超出客户端 GPU 能力的。我们添加了低秩适应 (Low-Rank Adaptation, LoRA,是一种参数高效的微调策略) 技术来填补此空缺,你可以更快速地以更少内存地微调扩散模型。最终的模型参数和原模型相比也十分轻量,所以你可以容易地分享你的个性化模型。欲了解更多,请参阅我们的 文档,其展示了如何用 LoRA 在 Stable Diffusion 上进行微调。
在 LoRA 之外,我们对个性化的生成也提供了其他的 训练技术,包括 DreamBooth, textual inversion, custom diffusion 以及更多!
面向 Torch 2.0 的优化
PyTorch 2.0 引入了支持 torch.compile() 和 scaled_dot_product_attention() (
一种注意力机制的更高效实现)。 Diffusers 提供了对这些特性的 支持,带来了速度的大量提升,有时甚至能快两倍多。
在视觉内容 (图片,视频,三维资产等) 外,我们也提供了音频支持!请查阅 文档 以了解更多。
社区的亮点
过去一年中,最令人愉悦的经历,便是看到社区如何把 Diffusers 融入到他们的项目中。从使用 LoRA 到更快的文本到图像的生成模型,到实现最前沿的绘画工具,这里是几个我们最喜欢的项目:
我们构建 Core ML Stable Diffusion,让它对开发者而言,在他们的 iOS, iPadOS 和 macOS 应用中,以 Apple Silicon 最高的效率,更容易添加最前沿的生成式 AI 能力。我们在 Diffusers 的基础上构建,而不是从头开始,因为不论想法新旧, Diffusers 能持续快速地跟进领域的发展,并且做到位的改进。
- Atila Orhon

Diffusers 对我深入了解 Stable Diffusion 模型而言十分友好。 Diffusers 的实现最独特之处是,它不是来自科研阶段的代码,而主要由速度驱动。科研时的代码总是写的很糟糕,难于理解 (缺少规范书写,断言,设计和记号不一致),在 Diffusers 上在数小时内实现我的想法,犹如呼吸一般简单。没有它,我估计会花更多的时间才开始 hack 代码。规范的文档和例子也十分有帮助。
- Simo

BentoML 是一个统一的框架,对构建,装载,和量化产品级 AI 应用,涉及传统的机器学习,预训练 AI 模型,生成式和大语言模型。所有的 Hugging Face 的 Diffusers 模型和管线都能无缝地整合进 BentoML 的应用中,让模型的运行能在最合适的硬件并按需实现自主规模缩放。
- BentoML

Invoke AI 是一个开源的生成式 AI 工具,用来助力专业创作,从游戏设计和摄像到建筑和产品设计。Invoke 最近开放了 invoke.ai,允许用户以最新的开源研究成果助力,在任意电脑上生成资产。
- InvokeAI

TaskMatrix 连接大语言模型和一系列视觉模型,助力聊天同时发送送和接受图片。
-Chenfei Wu
Lama Cleaner 是一个强大的图像绘画工具,用 Stable Diffusion 的技术移除不想要的物体、瑕疵、或者人物。它也可以擦除和替换图像中的任意东西。
- Qing

Grounded-SAM 结合了一个强大的零样本检测器 Grounding-DINO 和 Segment-Anything-Model (SAM) 来构建一个强大的流水线,以用文本输入检测和分割任意物体。当和 Diffusers 绘画模型结合起来时,Grounded-SAM 能做高可控的图像编辑人物,包括替换特定的物体,绘画背景等等。
- Tianhe Ren

Stable-Dreamfusion 结合 Diffusers 中方便的 2D 扩散模型来复现最近文本到 3D 和图像到 3D 的方法。
- kiui

MMagic (Multimodal Advanced, Generative, and Intelligent Creation) 是一个先进并且易于理解的生成式 AI 工具箱,提供最前沿的 AI 模型 (比如 Diffusers 的扩散模型和 GAN 模型),用来合成,编辑和改善图像和视频。在 MMagic 中,用户可以用丰富的部件来个性化他们的模型,就像玩乐高一样,并且很容易地管理训练的过程。
- mmagic

Tune-A-Video,由 Jay Zhangjie Wu 和他来自 Show Lab 的团队开发,是第一个用单个文本-视频对实现微调预训练文本到图像的扩散模型,它能够在改变视频内容的同时保持内容的运动状态。
- Jay Zhangjie Wu

同时我们也和 Google Cloud 合作 (他们慷慨地提供了计算资源) 来提供技术性的指导和监督,以帮助社区用 TPU 来训练扩散模型 (请参考 比赛 )。有很多很酷的模型,比如这个 demo 结合了 ControlNet 和 Segment Anything。
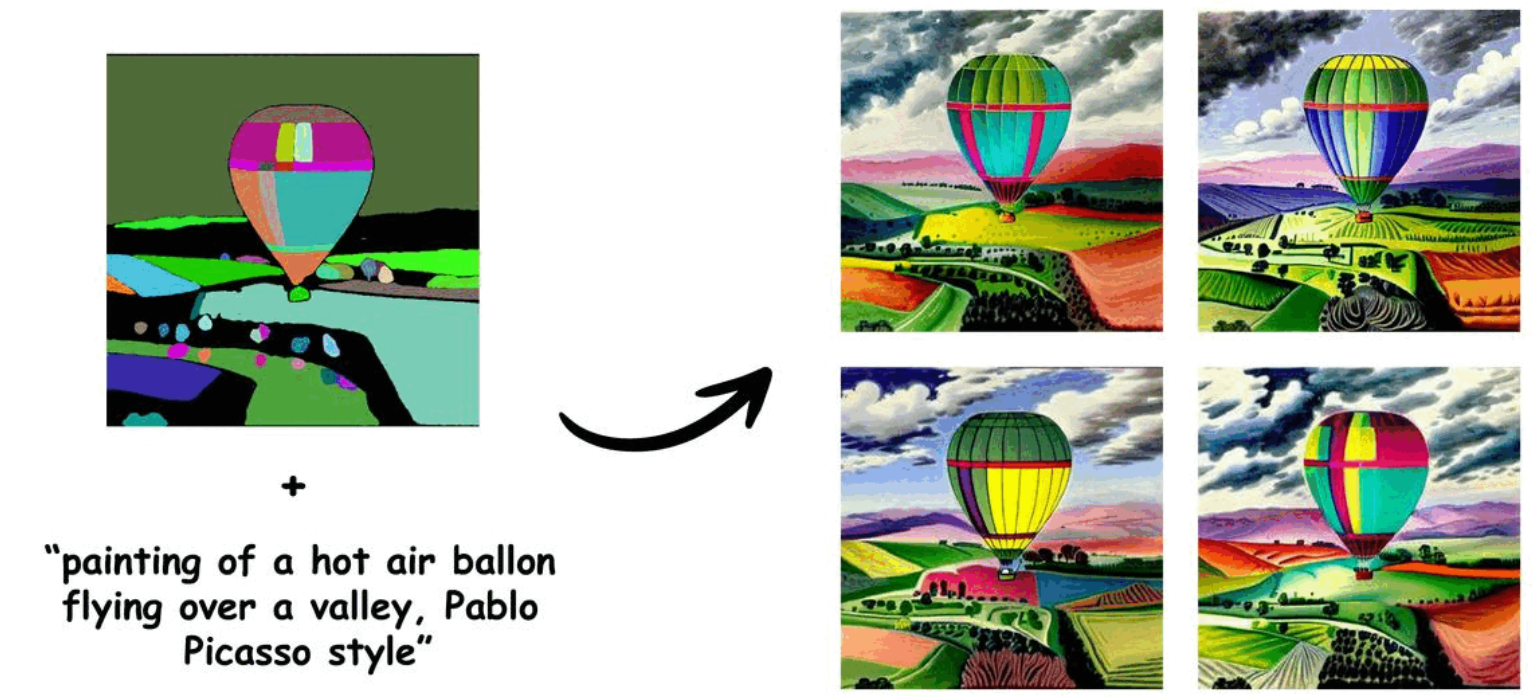
最后,我们十分高兴收到超过 300 个贡献者对我们的代码的改进,以保证我们能以最开放的形式合作。这是一些来自我们社区的贡献:
- Model editing by @bahjat-kawar, 一个修改模型隐式假设的流水线。
- LDM3D by @estelleafl, 一个生成 3D 图片的扩散模型。
- DPMSolver by @LuChengTHU, 显著地提高推理速度。
- Custom Diffusion by @nupurkmr9, 一项用同一物体的少量图片生成个性化图片的技术。
除此之外,由衷地感谢如下贡献者,为我们实现了 Diffusers 中最有用的功能。
- @takuma104
- @nipunjindal
- @isamu-isozaki
- @piEsposito
- @Birch-san
- @LuChengTHU
- @duongna21
- @clarencechen
- @dg845
- @Abhinay1997
- @camenduru
- @ayushtues
用 Diffusers 做产品
在过去一年中,我们看到了许多公司在 Diffusers 的基础上构建他们的产品。这是几个吸引到我们关注的产品:
- PlaiDay: “PlaiDay 是一个生成式 AI 产品,人们可以合作,创造和连接。我们的平台解锁了人脑的无限创造力,为表达提供了一个安全,有趣的画板。”
- Previs One: “Previs One 是一个面向电影故事板和预可视化的扩散模型 - 它能如同导演般理解电影和电视的合成规则。”
- Zust.AI: “我们利用生成式 AI 来为品牌和市场营销创造工作室级别的图像产品。”
- Dashtoon: “Dashtoon 在构建一个创造和消耗视觉内容的平台。我们有多个流水线配置多个 LoRA,多个 Control-Net,甚至多个 Diffusers 模型。Diffusers 已经让产品设计师和 ML 设计师之间的鸿沟十分小了,这让 dashtoon 能更加重视用户的价值。”
- Virtual Staging AI: “用生成模型做家具,来填满空荡荡的房间吧。”
- Hexo.AI: “Hexo AI 帮助品牌在市场上得到更高的 ROI,通过个性化的市场规模。Hexo 在构建一个专门的生成引擎,通过引入用户数据,生成全部个性化的创造。”
如果你在用 Diffusers 构建产品,我们十分乐意讨论如何让我们的库更加好!欢迎通过 patrick@hf.co 或者 patrick@hf.co 来联系我们。
展望
作为我们的一周年庆,我们对社区和开源贡献者十分感激,他们帮我们在如此短的时间如此多的事情。我们十分开心,将在今年秋天的 ICCV 2023 展示一个 Diffusers 的 demo - 如果你参加,请过来看我们的表演!我们将持续发展和提高我们的库,让它对每个人而言更加容易使用。我们也十分激动能看到社区用我们的工具和资源做的下一步创造。感谢你们作为我们目前旅途中的一员,我们期待继续一起为机器学习的民主化做贡献!
️ Diffusers 团队
致谢: 感谢 Omar Sanseviero, Patrick von Platen, Giada Pistilli 的审核,以及 Chunte Lee 设计的 thumbnail。
英文原文: https://hf.co/blog/diffusers-turns-1
作者: Steven Liu, Sayak Paul, Pedro Cuenca
译者: Vermillion-Qi
审校/排版: zhongdongy (阿东)
Diffusers 一岁啦 !的更多相关文章
- Android五岁了
今日(2013-9-24),谷歌开源系统Android迎来了它5岁的生日. 时间过得真快啊!当时的android并不被人看好,而现在的android已经成为了全球最大的智能手机操作系统.而现在的诺基亚 ...
- 祝贺 Linux 25 岁:25 个关于 Linux 的惊人真相!【转载】
作者:Javen Fang链接:https://zhuanlan.zhihu.com/p/22222383来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 25 年前的这 ...
- 【教程】16岁黑客如何把Windows 95装进智能手表?【转】
来自美国佐治亚州的16岁黑客Corbin Davenport十分喜欢摆弄电子产品,最近他刚到手了一台三星Gear Live,并开始把玩起来.他发现Android Wear作为Android系统的改版并 ...
- [No000053]我25岁了,是应该继续挣钱,还是选择自己的爱好?--正好庆祝自己25岁生日
你所问的问题正是问题所在.停止做出重大决策,专注于缩小你想到达的地位与你之间的差距. 成功的生活并非由简单而鲜明的决定组成,它们更像这幅图: 但悲伤的是,太多人的状态类似于这幅图: 我知道这听上去很显 ...
- [No00002C]人的寿命应该能达到100至175岁-北大齐教授健康讲座笔录
人的寿命应该能达到100 至175 岁,为什么都没有达到呢?最主要一个原因就是我们不重视保健,不懂得保健的知识.很多人死于无知,这很冤枉啊! 大家知道怎么保健吗?国际上有个维多利亚宣言,宣言里有三 ...
- 有感于三个50岁的美国程序员的生活状态与IT职业杂想
前言 这篇杂记其实是去年也就是 2013年9月30日写的,还上过博客园十日推荐的首页,后来在整理博客分类时七弄八弄误删掉了好多文章,就包括这一篇.今天,2014年9月29日,恰好恰好一年的时候居然在好 ...
- hdu1201-18岁生日
Gardon的18岁生日就要到了,他当然很开心,可是他突然想到一个问题,是不是每个人从出生开始,到达18岁生日时所经过的天数都是一样的呢?似乎并不全都是这样,所以他想请你帮忙计算一下他和他的几个朋友从 ...
- 12岁的少年教你用Python做小游戏
首页 资讯 文章 频道 资源 小组 相亲 登录 注册 首页 最新文章 经典回顾 开发 设计 IT技术 职场 业界 极客 创业 访谈 在国外 - 导航条 - 首页 最新文章 经典回顾 开发 ...
- (1)建立一个名叫Cat的类: 属性:姓名、毛色、年龄 行为:显示姓名、喊叫 (2)编写主类: 创建一个对象猫,姓名为“妮妮”,毛色为“灰色”,年龄为2岁,在屏幕上输 出该对象的毛色和年龄,让该对象调用显示姓名和喊叫两个方法。
package lianxi; public class Cat { String Name, Color; int Age; void getName() { System.out.println( ...
- 30岁IT男连续工作一个月 突然失聪
连续开发软件一个月,30 岁男子突然听不见声音了.近日,浙江省中山医院针灸科主任高宏主任中医师接诊了这名患者.高主任说,现在很多年轻人工作压力大,得突发性耳聋的越来越多,这种病听着不是威胁生命的大病, ...
随机推荐
- 绝对强大的三大linux指令:ar, nm, objdump
前言 如果普通编程不需要了解这些东西,如果想精确控制你的对象文件的格式或者你想查看一下文件对象里的内容以便作出某种判断,刚你可以看一下下面的工具:objdump, nm, ar.当然,本文不可能非常详 ...
- Python 使用列表一部分(切片)
使用列表的一部分(切片) 处理列表的部分元素 切片 指定第一个元素的索引和最后一个元素索引加1 列表名[索引:索引+1] 索引加1:列表中第索引个元素 (左包括右不包括) 未指定索引 列表名[:] 提 ...
- MD5简述及常见解密网址推荐
什么是md5 MD5(Message-Digest Algorithm 5)(信息-摘要算法5), 一种被广泛使用的[密码散列函数](https://baike.baidu.com/item/密码散列 ...
- TextArea设置MaxLength的代码(未测试在不同浏览器下的兼容性)
function SetTextAreaMaxLength(controlId,length) { // JScript File for TextArea // Keep user from ent ...
- Wolai 使用教程:嵌入小组件库,打造精美、强大的知识库主页
Wolai /我来云笔记在 2022.7.11 日的更新中,支持嵌入包括 NotionPet.芦笋.Replit 等在内的第三方应用.感谢 Wolai 云笔记官方对于 NotionPet 的支持. 趁 ...
- 2022-11-30:小红拿到了一个仅由r、e、d组成的字符串 她定义一个字符e为“好e“ : 当且仅当这个e字符和r、d相邻 例如“reeder“只有一个“好e“,前两个e都不是“好e“,只有第三个
2022-11-30:小红拿到了一个仅由r.e.d组成的字符串 她定义一个字符e为"好e" : 当且仅当这个e字符和r.d相邻 例如"reeder"只有一个&q ...
- [ABC268C] Chinese Restaurant
[ABC268C] Chinese Restaurant 声明:以上的所有操作都会再做一次\(%n+n)%n\),比如\(i - 1\)会变成\(((i-1)%n+n)%n\) 题意 有 \(n\) ...
- Linux(redhat)镜像
作为一个合格的程序猿,Linux那就是必须得会玩哟呵,搜集了一些镜像分享大家,望笑纳. 云盘地址https://pan.baidu.com/s/1cB-llYI5RdRm9xJDmjFoWg 提取码 ...
- 驱动开发:内核扫描SSDT挂钩状态
在笔者上一篇文章<驱动开发:内核实现SSDT挂钩与摘钩>中介绍了如何对SSDT函数进行Hook挂钩与摘钩的,本章将继续实现一个新功能,如何检测SSDT函数是否挂钩,要实现检测挂钩状态有两种 ...
- Scalpel:解构API复杂参数Fuzz的「手术刀」
Scalpel简介 Scalpel是一款自动化Web/API漏洞Fuzz引擎,该工具采用被动扫描的方式,通过流量中解析Web/API参数结构,对参数编码进行自动识别与解码,并基于树结构灵活控制注入位点 ...