Hadoop伪分布式配置
一步一步来:
安装VMWARE简单,安装CentOS也简单
但是,碰到了一个问题:安装的虚拟机没有图形化界面
最后,我选择了CentOS-7-x86_64-DVD-1503-01.iso镜像
配置用户名就是centos
成功安装了带有图像化界面的CentOS7
注意:这个是64位的操作系统,建议配置2G以上内存,处理器为4,要不然卡爆你
接下来就是安装JDK
安装完VMTOOLS发现还是无法直接从主机复制过去
(安装中途如果需要提权,不要用sudo,使用su命令,然后安装就行)
于是我利用共享文件夹的方式,不复杂
注意:共享文件夹的目录是:/mnt/hgfs
解压JDK:tar -xvzf jdk.....
然后根目录新建soft目录,用于安装各种软件
配置soft目录的权限:chown centos:centos /soft
创建符号链接:ln -s jdk..... /soft/jdk
验证安装的话:
CentOS自带JDK1.7的,我们需要cd到jdk的bin目录下,然后./java -version
配置环境变量:
vi /etc/profile
在最后两行加上:
export JAVA_HOME=/soft/jdk
export PATH=$PATH:$JAVA_HOME/bin
生效:source /etc/profile
注意:如果没有生效,可以重启试一试
下面就是Hadoop的安装了:
类似上面说的,利用共享目录把压缩包从主机转移过来
然后,tar,mv到soft,设置符号链接为hadoop
验证是否安装成功:
cd到bin目录,./hadoop version即可
然后配置环境变量,类似上面:
export HADOOP_HOME=/soft/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后使用source命令生效
注意:有时候可能无效,多次重启或者source后基本就可以用了
如果还是无法生效,可以尝试删除临时文件:rm /etc/.profile.tmp
最终验证成功:hadoop version
成功后,接下来就是配置Hadoop:
1.本地模式
配置方式:什么都不做
使用命令hdfs dfs -ls /
发现文件系统就是在本地
2.伪分布式
配置方式稍显复杂
这个目录是Hadoop的所有配置文件
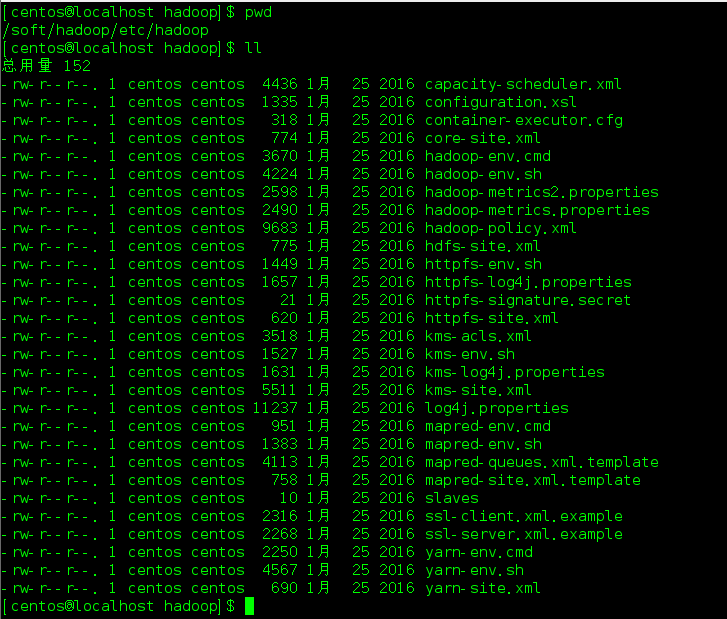
配置core-site.xml:默认配置
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost/</value> </property> </configuration>
配置hdfs-site.xml:配置为一个副本,即没有备份
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
配置mapred-site.xml:配置yarn框架
配置时候注意:只有mapred-site.xml.templete文件,我们要cp一份重命名为mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
配置yarn-site.xml:默认配置
<?xml version="1.0"?> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
配置SSH:
密码登陆在分布式中过于复杂,应该用无密登陆方式
这里使用openssh
查看系统是否已经安装:

发现系统已经默认安装了,我们不需要自己装
查看进程是否启动:启动

生产公私密钥对:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
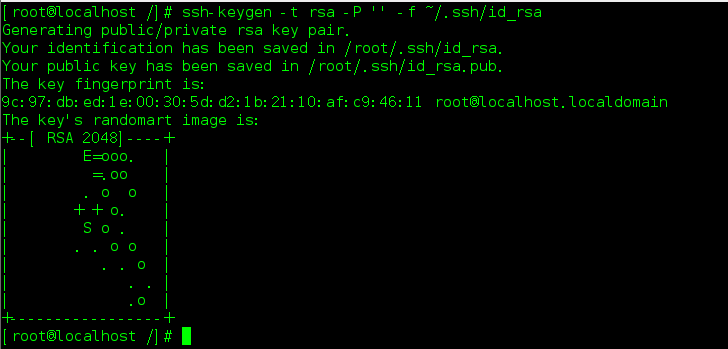
在.ssh目录中就生成了公私密钥对
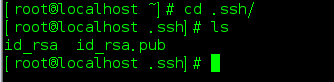
追加公钥:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys

修改authorized_keys的权限为644:
chmod 644 authorized_keys
对了,这里有个问题,我是用root权限进行的配置,实际上,应该用centos用户进行配置
验证是否成功
ssh localhost:

到这里,伪分布式就完成了
用符号链接,使三种配置形态共存:

local文件夹作为本地模式的配置文件
不过之前已经修改过配置文件了,这时候只需要修改回来即可
将修改过的四个配置都写成下面这样:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> </configuration>
然后复制一份pesudo作为伪分布式配置文件
复制一份full作为完全分布式配置文件
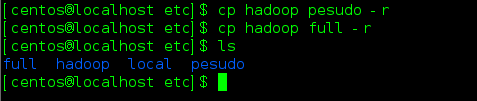
删除原来的配置文件rm -rf hadoop
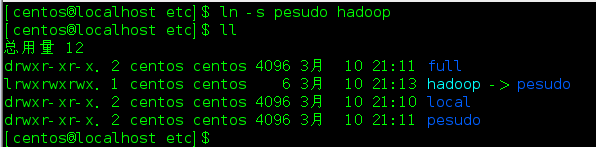
现在我想启用伪分布式:
设置符号链接:ln -s pesudo hadoop
对HDFS进行格式化:
hadoop namenode -format
启动hadoop:
由于之前已经配置过环境变量了,这里就不需要到sbin目录下
start-all.sh
但是,我们发现报错:没有找到JAVA_HOME
之前我有过配置JAVA_HOME,为什么这里报错呢?和CentOS系统有一定的关系
所以我们需要修改一个配置文件
hadoop安装目录/etc/hadoop/hadoop-env.sh
找到$JAVA_HOME这一行,然后写死:export JAVA_HOME=/soft/jdk
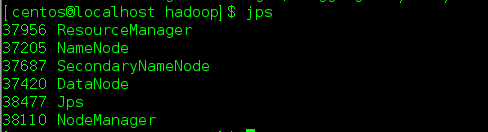
接下来就可以运行了
验证成功运行:查看运行的进程
查看hdfs文件系统:
hdfs dfs -ls /
如果返回空,说明正常,因为我们没有修改文件系统
创建目录:
hdfs dfs -mkdir -p /user/centos/hadoop
通过浏览器查看hadoop文件系统:
http://localhost:50070
停止hadoop:
stop-all.sh
Hadoop伪分布式配置的更多相关文章
- Data - Hadoop伪分布式配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Hadoop伪分布式配置:CentOS6.5(64)+JDK1.7+hadoop2.7.2
java环境配置 修改环境变量 export JAVA_HOME=/usr/java/jdk1.7.0_79 export PATH=$PATH:$JAVA_HOME/bin export CLASS ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- Hadoop安装教程_单机/伪分布式配置
环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS).如果用的是 Ubuntu 系统,请查看相应的 Ubuntu安装Hadoo ...
- 新手推荐:Hadoop安装教程_单机/伪分布式配置_Hadoop-2.7.1/Ubuntu14.04
下述教程本人在最新版的-jre openjdk-7-jdk OpenJDK 默认的安装位置为: /usr/lib/jvm/java-7-openjdk-amd64 (32位系统则是 /usr/lib/ ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04(转)
http://www.powerxing.com/install-hadoop/ http://blog.csdn.net/beginner_lee/article/details/6429146 h ...
- ubantu18.04下Hadoop安装与伪分布式配置
1 下载 下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/stable2/ 2 解压 将文件解压到 /usr/local/hadoop cd ~ ...
随机推荐
- mysql 与 oracle 的连表update
mysql: update 表A a,表B b set a.xx=b.xx where a.id=b.id; oracle update 表A set a.xx=(select b.xx from 表 ...
- Flink写入kafka时,只写入kafka的部分Partitioner,无法写所有的Partitioner问题
1. 写在前面 在利用flink实时计算的时候,往往会从kafka读取数据写入数据到kafka,但会发现当kafka多个Partitioner时,特别在P量级数据为了kafka的性能kafka的节点有 ...
- IE外挂
//引用 Windows/system32/Shell32.dll //引用COM组件 shdocvw.dll (Microsoft Internet Controls) //引用COM组件 msht ...
- 第二项目AIaisell(易销宝)
一.什么是报表 向上级报告情况的表格.简单的说:报表就是用表格.图表等格式来动态显示数据,可以用公式表示为:“报表 = 多样的格式 + 动态的数据” 表格:详细数据 图表: 直观 二.表格数据展示 2 ...
- php八种常用函数
八种常用的数学函数: ① abs(x):求绝对值 ② ceil(x),floor(x):向上/下取最接近的整数 ③ cos(x),sin(x),tan(x):三角函数 ④ min(),max( ...
- C语言的整型溢出问题 int、long、long long取值范围 最大最小值
类型名称 字节数 取值范围 signed char 1 -128-+127 short int 2 -32768-+32767 int 4 -2147483648-+2147483647 long i ...
- The First of my text
JavaScript 学习第一天 一.属性可以动态拓展 例如: var person = { name : "zs"; age : 21; } person.sex = " ...
- jQuery各类选择器
- git cannot lock ref
参考博客:https://blog.csdn.net/lindexi_gd/article/details/79213042 错误原文: cannot lock ref ‘refs/remotes/o ...
- nodejs, 阿里oss上传下载图片
const archiver = require('archiver')const send = require('koa-send')const oss = require('ali-oss').W ...