[py]pandas数据统计学习
pandas.core.base.DataError: No numeric types to aggregate错误规避
我没有去解决这个问题, 而用填充0规避了这个问题
统计 聚合
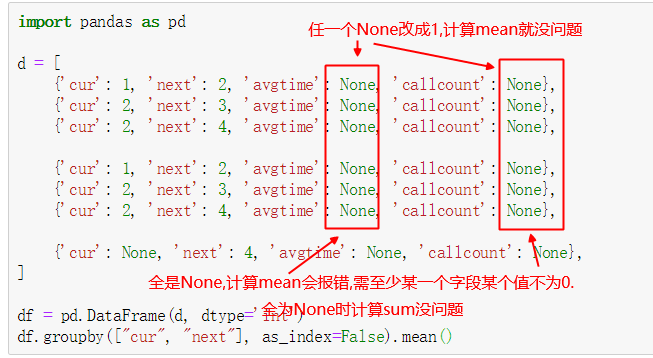
d = [
{'cur': 1, 'next': 2, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 3, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 4, 'avgtime': None, 'callcount': None},
{'cur': 1, 'next': 2, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 3, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 4, 'avgtime': None, 'callcount': None},
{'cur': None, 'next': 4, 'avgtime': None, 'callcount': None},
]
df = pd.DataFrame(d, dtype='int')
df.groupby(["cur", "next"], as_index=False).mean()重要总结:
1. None为NaN
2. count会统计空字符串, 但是cont不统计NaN. sum不统计NaN, 否则就会像sql里select(1+NULL)结果是NULL
3. 分组key为None时,记录不显示
计算mean()时DataError: No numeric types to aggregate
agg函数
使用这种聚合会卡到这个bug
pandas.core.base.DataError: No numeric types to aggregate错误规避
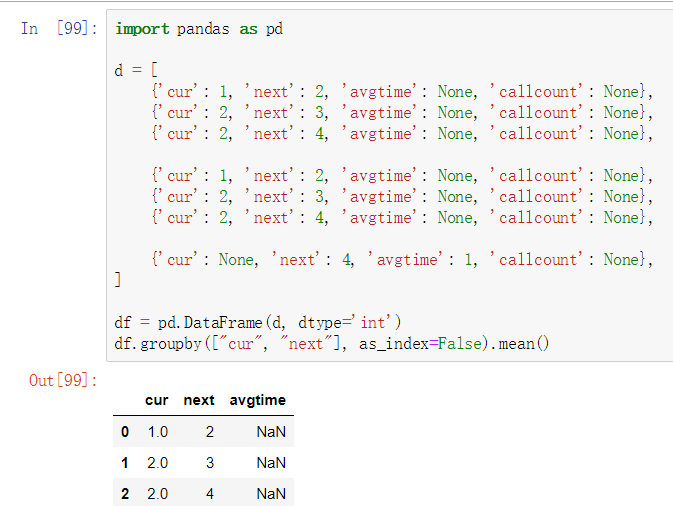
import pandas as pd
d = [
{'cur': 1, 'next': 2, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 3, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 4, 'avgtime': None, 'callcount': None},
{'cur': 1, 'next': 2, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 3, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 4, 'avgtime': None, 'callcount': None},
{'cur': None, 'next': 4, 'avgtime': None, 'callcount': None},
]
df = pd.DataFrame(d, dtype='int')
g = df.groupby(["cur", "next"], as_index=False)
res = g.agg(
{
'avgtime': 'sum',
'callcount': 'mean',
}
)
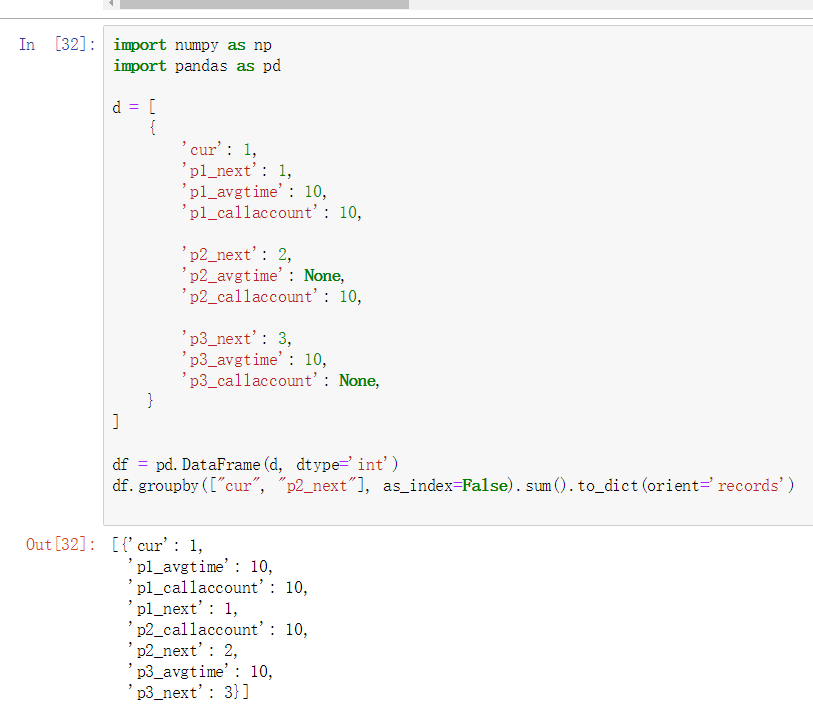
复杂的分组: cur分别与p1 p2 p3分组
import numpy as np
import pandas as pd
d = [
{
'cur': 1,
'p1_next': 1,
'p1_avgtime': 10,
'p1_callaccount': 10,
'p2_next': 2,
'p2_avgtime': None,
'p2_callaccount': 10,
'p3_next': 3,
'p3_avgtime': 10,
'p3_callaccount': None,
}
]
df = pd.DataFrame(d, dtype='int')
df.groupby(["cur", "p2_next"], as_index=False).sum().to_dict(orient='records')
[py]pandas数据统计学习的更多相关文章
- 转载,Pandas 数据统计用法
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据import numpy as npimport panda ...
- pandas数据统计
1 count() 非空观测数量 2 sum() 所有值之和 3 mean() 所有值的平均值 4 median() 所有值的中位数 5 mode() 值的模值 6 std() 值的标准偏差 7 mi ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- pandas数据框,统计某列或者某行数据元素的个数
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/sinat_38893241/articl ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- 大数据学习day33----spark13-----1.两种方式管理偏移量并将偏移量写入redis 2. MySQL事务的测试 3.利用MySQL事务实现数据统计的ExactlyOnce(sql语句中出现相同key时如何进行累加(此处时出现相同的单词))4 将数据写入kafka
1.两种方式管理偏移量并将偏移量写入redis (1)第一种:rdd的形式 一般是使用这种直连的方式,但其缺点是没法调用一些更加高级的api,如窗口操作.如果想更加精确的控制偏移量,就使用这种方式 代 ...
- [译]针对科学数据处理的统计学习教程(scikit-learn教程2)
翻译:Tacey Wong 统计学习: 随着科学实验数据的迅速增长,机器学习成了一种越来越重要的技术.问题从构建一个预测函数将不同的观察数据联系起来,到将观测数据分类,或者从未标记数据中学习到一些结构 ...
- scikit-learning教程(二)统计学习科学数据处理的教程
统计学习:scikit学习中的设置和估计对象 数据集 Scikit学习处理来自以2D数组表示的一个或多个数据集的学习信息.它们可以被理解为多维观察的列表.我们说这些阵列的第一个轴是样本轴,而第二个轴是 ...
随机推荐
- A tuple is defined as a function
In James Munkres "Topology", the concept for a tuple, which can be \(m\)-tuple, \(\omega\) ...
- Redis数据结构之ziplist
本文及后续文章,Redis版本均是v3.2.8 本篇文章我们来分析下一种特殊编码的双向链表-ziplist(压缩列表),这种数据结构的功能是将一系列数据与其编码信息存储在一块连续的内存区域,这块内存物 ...
- python输入
(程序是如何输入输出的) 先了解一个概念,什么是函数? 简单来说,函数就是封装了一些功能,到时候只需要写一个函数名字,就可以使用这些功能 input函数,它是输入函数,它可以将用户输入的内容当做“字符 ...
- Vue学习陷阱
v-for在嵌套时index没办法重复用,内循环与外循环不能共用一个index <swiper-item v-for="(items,index) in swiperList" ...
- weblogic 安装部署详解
0x01 weblogic下载安装 去Oracle官网下载Weblogic 10.3.6,选择Generic版本,各版本选择下载地址:http://www.oracle.com/technetwork ...
- [Python]Python中的浅复制与深复制
看python的文档,发现list有copy方法,描述说效果同a[:]. 感觉有点惊讶,之前一直以为a[:]执行的是深复制. test了一下,发现确实如果a中存在可变对象,如list/set/dict ...
- react-native flatlist 上拉加载onEndReached方法频繁触发的问题
问题 在写flatlist复用组件时,调用的时候如果父组件是不定高的组件,会造成组件无法显示 如果父组件样式{flex:1},则会出现下拉方法频繁触发或不正常触发的问题(我这里出现的问题是在列表第6个 ...
- __x__(9)0906第三天__常见的标签
<!doctype html> <html> <head> <meta charset="utf-8" /> <title&g ...
- __x__(19)0907第四天__ HTML5 文本标签 及 样式
strong 表语义上的强调, em 表示语气上的强调: <strong>警告:离僵尸远点!</strong> 世界末日了,因为僵尸是<em>有毒的</em& ...
- (78)Wangdao.com第十五天_JavaScript 面向对象
面向对象编程(Object Oriented Programming,缩写为 OOP) 是目前主流的编程范式. 是单个实物的抽象, 是一个容器,封装了属性(property)和方法(method),属 ...