Cs231n课堂内容记录-Lecture 6 神经网络训练
Lecture 6 Training Neural Networks
课堂笔记参见:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit
本节课内容主要包括三部分:训练前准备、训练和评分。具体包括激活函数的选择,预处理,权重初始化,正则化,梯度检查,监控学习进程,参数更新,超参数优化和最终的模型评估。

一、激活函数

激活函数就是f,在以往线性评分的基础上加上激活函数,引入了非线性项,整体作为评分。
1. Sigmoid:
在绝对值较大的区域近似为线性函数,斜率很小。
这个函数在一定程度上可以看做是神经元的饱和放电率(firing rate)。
问题:
1.饱和神经元将导致梯度消失:当x绝对值比较大时,σ对x的偏导为0。x=0时,将得到一个合理的梯度,x=10,时,梯度将为0。
2.sigmoid并不是一个以0为中心值的函数,也就是说 Sigmoid 的输出不是0均值的,这是我们不希望的,因为这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正, 对w求梯度时,L对w的偏导要么全为正,要么全为负,由dL/df决定(L是Loss,f是评分函数),而df/dw=x(w的局部梯度)都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。
当然了,如果你是按batch去训练,那么每个batch可能得到不同的符号(正或负),那么相加一下这个问题还是可以缓解。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。
如下图右侧的例子,w为二维,f描述为f(x,w,b)=f(w0x0+w1x1+b),现在假设w0,w1的最优解满足蓝色向量的条件,那么梯度更新向蓝色箭头方向是最快的,这个更新方向要求dw0为正,dw1为负,也就要求输入的x0,x1符号相反。但是,由于上个神经元sigmoid函数输出的x0,x1始终符号相同,因此梯度更新只能走如图所示的折线轨迹,收敛缓慢。

3.指数函数的计算代价比较高,但不是重点,因为卷积和点乘的计算代价更大。
2. tanh:
和sigmoid主要的不同是以0为中心了,但是依然会存在梯度消失的问题。
3. ReLU:
最大的优势是不存在正值的梯度消失问题。计算成本也比较低,不含指数。通常我们使用ReLU比较多,因为它比sigmoid和tanh收敛快得多,大约快6倍。也有证据表明它比sigmoid更具备生物学上的合理性。
问题:不再以0为中心,负半轴依然会有梯度消失问题。当数据出现在负半轴的区域时,我们将之称为dead ReLU。如果某节点设定的权值不合理,所有的输入经过线性变换都小于0,那这个节点上的权重就没法反向传播更新,即为dead ReLU,此时dead ReLU的输出也将都是0。当然如果learning rate比较大,权重更新幅度大,一开始正常的ReLU在之后也可能dead,当你使用一个训练好的网络的时候,你会发现会有10%~20%的dead ReLU,大多数使用ReLU的网络都有这个问题。
所以一些人在使用ReLU的时候习惯用较小的正偏置来初始化ReLU(比如0.01),以期增加它在初始化时被激活的可能性,但这在理论上并没有被证明。
4. Leaky ReLU:
Leaky ReLU是ReLU的一个改进,不会有任何的饱和问题,它仍然比sigmoid和tanh的收敛速度快,没有dead problem。

另一个变形是参数整流器(parametric rectifier),简称PReLU,此时的α同样参与反向传播过程,因此更加灵活。
5. Exponential Linear Units:(ELU)
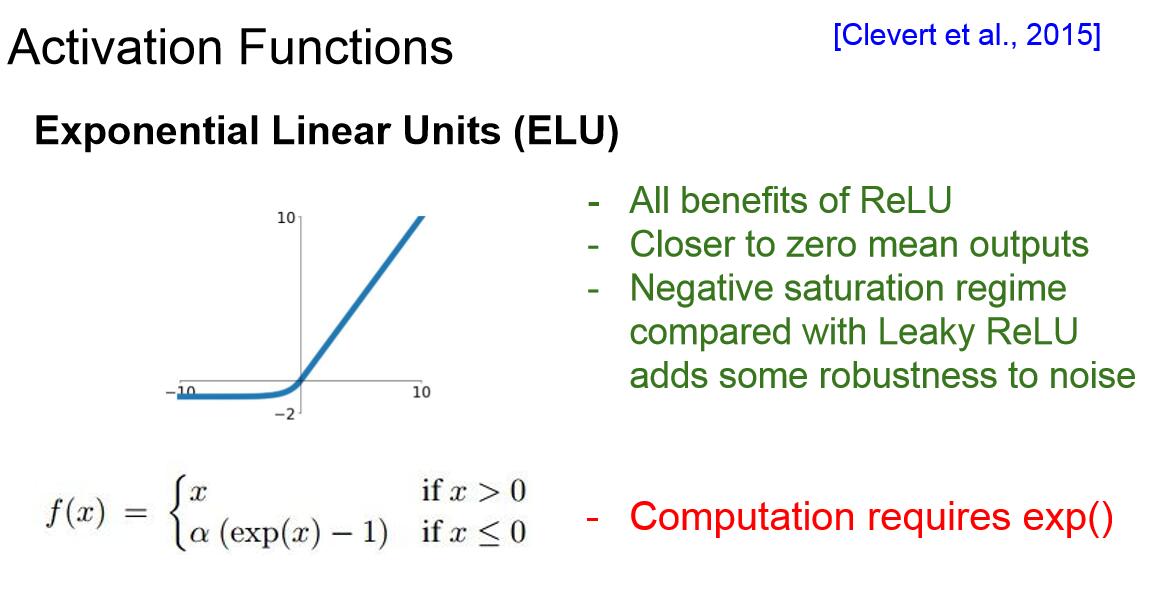
这种指数线性单元具有ReLU的一切优点,但是与Leaky ReLU相比,ELU并没有在负区间倾斜,这里实际上我们建立了一种负饱和机制,有一些观点认为这样做可以使模型对噪音有更强的鲁棒性。这个模型可以被认为介于ReLU和Leaky ReLU之间。
6. Maxout Neuron:
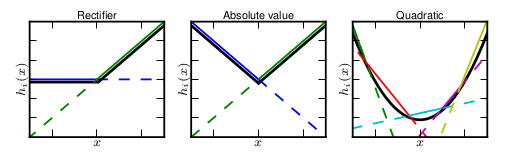
除了上面的各种ReLU变体之外,这里还有一种最大输出神经元的激活结构,它翻倍了权重和偏置的数量,输出其中较大的值,作用是泛化了ReLU和Leaky ReLU,因为与常规激活函数不同的是,它是一个可学习的分段线性函数.
任何一个凸函数,都可以由线性分段函数进行逼近近似。ReLU、Leaky ReLU都可以看成是分段的线性函数,如下示意图所示。那么,前边的两种ReLU便是Maxout中两个函数的组合,函数图像为两组直线的拼接
7. 一般经验:
一般做法是用ReLU,这是最标准的方法,你要谨慎地调整学习速率。你可以使用Leaky ReLU,Maxout,ELU,但是这些方法大多是实验性的(实用性不强),你想要结合你的模型考虑。另外,我们一般不使用sigmoid,因为这是最原始的激活函数,ReLU及变体表现得更好。
二、数据预处理
一些数据预处理的标准操作是拿到原始数据之后,零均值化(中心化),然后利用标准差进行归一化。

关于零均值化,我们之前讲过如果所有的输入数据都是正的,那么梯度也全是正的或者负的,这会导致我们的优化效果下降。在这节课中,我们经常会对图像数据零均值化,但是不总是进行归一化操作,因为一般对于图像来说,像素分布总是较为均匀的。我们更不会去做像PCA或者白化这种更为复杂的预处理。在训练数据中,我们会得到均值图像,这将会被运用到测试数据中。均值的获取方法既可以是整张图像均值(AlexNet),也可以是各颜色通道的均值(VGGNet)。
三、权重初始化
如果我们使用0作为初始值,每层神经元在第一次数据输入时就将得到相同的数值,并且得到相同的梯度,也会以相同的方式更新,这样你得到的就是相同的神经元,这当然是不合适的,所以我们需要打破初始权重的一致性。所以我们希望权重是较小的随机数,可以用高斯分布取样,比如下图:

这种权重初始化适用于小型网络,但是对于更深的网络结构,对于一个10层的网络,每层有100个神经元,你就会发现除了第一层的激活值满足高斯分布之外,后几层的激活值迅速下降为0,因为w的初始值太小了。如果我们计算梯度的话,w的梯度含有上一层的x输入项,因此权重基本不会更新。
当我们从高斯分布中采样,用1来乘以标准差而不是0.01时,权重过大将会导致网络饱和。所以权重过大或者过小都会导致结果不尽如人意。一个很好的经验是我们可以使用如图所示的Xavier初始化。(Xacier initialization. Glorot et al.,2010)。

这个公式的核心思想是让输出的方差和输入的方差尽可能地保持一致。可以看到,输出值在很多层之后依然保持着良好的分布。需要注意的是,Xavier initialization是在线性函数的基础上推导得出,这说明它对非线性函数并不具有普适性,所以这个例子仅仅说明它对tanh很有效,对于目前最常用的ReLU神经元,则不会适用,这时He initialization的表现更好。
参见:https://www.leiphone.com/news/201703/3qMp45aQtbxTdzmK.html
https://zhuanlan.zhihu.com/p/21560667?refer=intelligentunit
四、Batch Normalization
Batch Normalization是一种巧妙而粗暴的方法来削弱bad initialization的影响,其基本思想是:If you want it, just make it!
我们想要的是在非线性activation之前,输出值应该有比较好的分布(例如高斯分布),以便于back propagation时计算gradient,更新weight。Batch Normalization将输出值强行做一次Gaussian Normalization和线性变换(如下图)。
Batch Normalization中所有的操作都是平滑可导,这使得back propagation可以有效运行并学到相应的参数γ,β。需要注意的一点是Batch Normalization在training和testing时行为有所差别。Training时μβ和σβ由当前batch计算得出;在Testing时μβ和σβ应使用Training时保存的均值或类似的经过处理的值,而不是由当前batch计算。

五、Babysitting the Learning Process(学习过程监测)
当我们初始化我们的网络的时候,我们想确定前向传播的损失函数是合理的,这里我们使用一个softmax分类器,当我们的初始权重很小,满足分散分布的时候,softmax的损失应当是负对数似然NLL的结果(均匀分布),如果有十个分类项,就应该是1/10的负对数。
一旦我们看到我们的初始损失还不错时,接下来我们加入零正则化项,再次检查loss,然后启动正则化,赋值比如1e3,可以看到损失值上升了。
现在我们开始训练,从小数据集开始,小数据集可以帮助你快速调整模型,发现问题。我们先不用正则化操作,观察是否能把训练损失降为0,理想情况下我们可以观察到,在多个epoch之后,我们的最终损失降为0,训练集的准确率上升为1。
当你结束了所有的完整性检查工作,就可以开始真正的训练了。这时我们使用所有训练数据,并加上一个小的正则化项。然后调整超参数以达到网络最好的性能,比如确定一个好的learning rate(通常在1e-3到1e-5之间)。
六、Hyperparameter Optimization
如何选择最佳的超参数值呢?我们使用的策略是交叉验证(cross-validation),交叉验证的意思是在训练集上进行训练,在验证集上验证,观察这些超参数的效果。这里我们有两件事要做,首先我们选择相当分散的数值,然后用几个epoch进行学习,在训练之后你就大体可以知道哪些超参数是有效的,这时你会得到一个参数的合适范围,然后我们将在这个范围内搜索更精确的值。
Cs231n课堂内容记录-Lecture 6 神经网络训练的更多相关文章
- Cs231n课堂内容记录-Lecture 7 神经网络训练2
Lecture 7 Training Neural Networks 2 课堂笔记参见:https://zhuanlan.zhihu.com/p/21560667?refer=intelligent ...
- Cs231n课堂内容记录-Lecture 4-Part2 神经网络
Lecture 7 神经网络二 课程内容记录:https://zhuanlan.zhihu.com/p/21560667?refer=intelligentunit 1.协方差矩阵: 协方差(Cova ...
- Cs231n课堂内容记录-Lecture 4-Part1 反向传播及神经网络
反向传播 课程内容记录:https://zhuanlan.zhihu.com/p/21407711?refer=intelligentunit 雅克比矩阵(Jacobian matrix) 参见ht ...
- Cs231n课堂内容记录-Lecture 3 最优化
Lecture 4 最优化 课程内容记录: (上)https://zhuanlan.zhihu.com/p/21360434?refer=intelligentunit (下)https://zhua ...
- Cs231n课堂内容记录-Lecture 5 卷积神经网络介绍
Lecture 5 CNN 课堂笔记参见:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit 不错的总结笔记:https://blo ...
- Cs231n课堂内容记录-Lecture 8 深度学习框架
Lecture 8 Deep Learning Software 课堂笔记参见:https://blog.csdn.net/u012554092/article/details/78159316 今 ...
- Cs231n课堂内容记录-Lecture 9 深度学习模型
Lecture 9 CNN Architectures 参见:https://blog.csdn.net/qq_29176963/article/details/82882080#GoogleNet_ ...
- Cs231n课堂内容记录-Lecture2-Part2 线性分类
Lecture 3 课程内容记录:(上)https://zhuanlan.zhihu.com/p/20918580?refer=intelligentunit (中)https://zhuanlan. ...
- Cs231n课堂内容记录-Lecture2-Part1 图像分类
Lecture 2 课程内容记录:(上)https://zhuanlan.zhihu.com/p/20894041?refer=intelligentunit (下)https://zhuanlan. ...
随机推荐
- python批量启动多线程
还未了解多线程的请查看博文 python3多线程趣味详解 python3多线程趣味详解 只是介绍了 python 多线程的使用,对于批量启动线程来说有些不适用,于是出现如下方法: 建立一个线程池,并将 ...
- 关闭mac的SIP + 一定有用的删除mac自带ABC的方法
如果你被这ABC输入法弄得很是不开心.那就看看吧!!!亲测一定有效. mac 关闭系统完整性保护 SIP(System Integrity Protection) 重启系统 按住 command+R ...
- Python内置函数(56)——set
英文文档: class set([iterable]) Return a new set object, optionally with elements taken from iterable. s ...
- 『Power Hungry Cows A*启发式搜索』
Power Hungry Cows(POJ 1945) Description FJ的奶牛想要快速计算整数P的幂 (1 <= P <=20,000),它们需要你的帮助.因为计算极大数的幂, ...
- Android Studio代码行数统计插件Statistics
Android Studio 是没有提提供统计代码全部行数的功能的,但是对于开发者来说,这个功能确实必备的,Statistic统计代码行数非常方便,也很详细. 1,首先肯定是将插件下载下来,下载地址: ...
- CentOS安装Java JDK
JDK是 Java 语言的软件开发工具包,主要用于移动设备.嵌入式设备上的java应用程序.在Linux上安装Tomcat,而Tomcat服务器运行时是需要JDK支持的,所以服务器必须配置好JDK用到 ...
- Hive 导入 parquet 格式数据
Hive 导入 parquet 数据步骤如下: 查看 parquet 文件的格式 构造建表语句 倒入数据 一.查看 parquet 内容和结构 下载地址 社区工具 GitHub 地址 命令 查看结构: ...
- 解决Springboot 的ajax跨域问题-动静分离
@SpringBootApplication public class FsSysApiApp { public static void main(String[] args) { SpringApp ...
- 【ASP.NET Core快速入门】(七)WebHost的配置、 IHostEnvironment和 IApplicationLifetime介绍、dotnet watch run 和attach到进程调试
WebHost的配置 我们用vs2017新建一个空网站HelloCore 这里的CreateDefaultBuilde实际上已经在内部替我们做好了默认配置. UseKestrel 使用kestrel ...
- Mysql免安装版配置教程和常用命令图
Mysql免安装版配置教程 图文版 配置环境变量 新建一个my.ini文件,添加下面内容 [mysqld] basedir=C:\\software\Mysql\mysql-5.7.14-winx64 ...