python 视频爬虫
打开网址:http://mv.688ing.com/
输入视频播放地址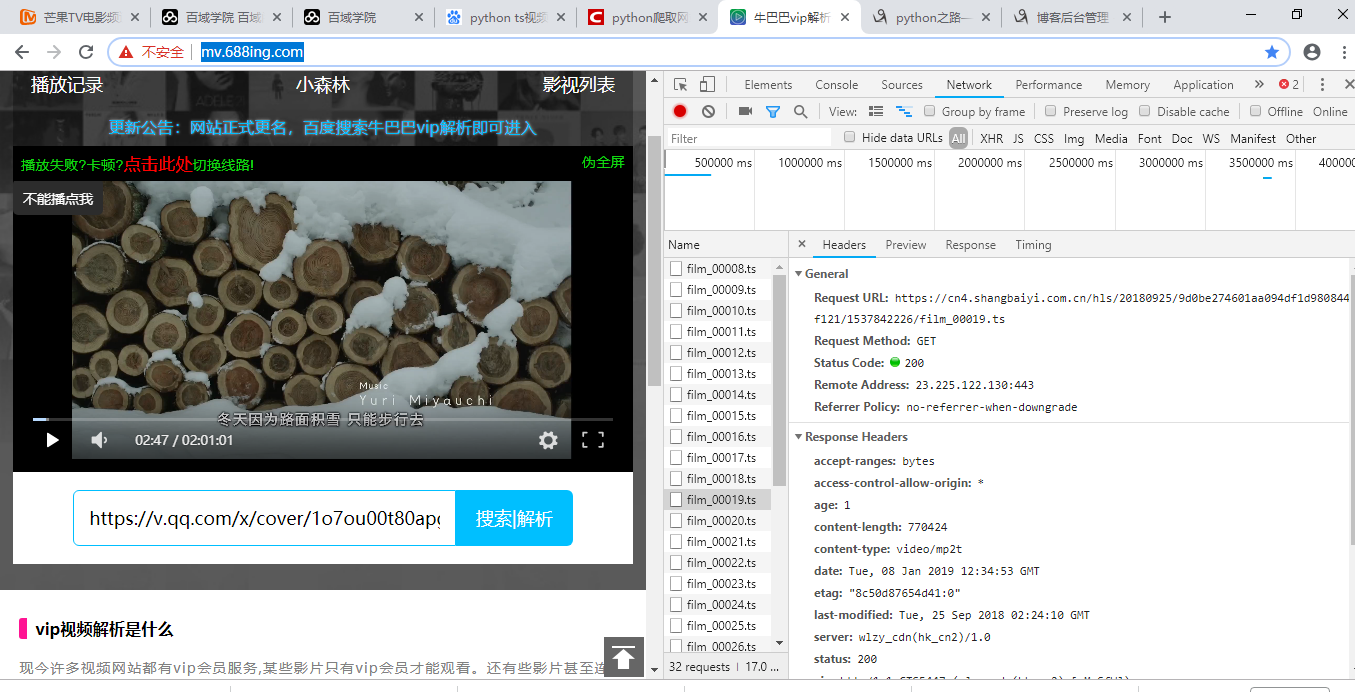
发现很多链接以.ts结尾。
#
import requests
import os
def download():
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
for i in range(1,100):
if i <10:
link='https://cn4.shangbaiyi.com.cn/hls/20180925/9d0be274601aa094df1d98084483f121/1537842226/film_0000.ts'+str(i)+'.ts'#构造下载链接
elif i <100:
link='https://cn4.shangbaiyi.com.cn/hls/20180925/9d0be274601aa094df1d98084483f121/1537842226/film_000.ts'+str(i)+'.ts'
dest_resp = requests.get(link,headers=headers)
#视频是二进制数据流,content就是为了获取二进制数据的方法
data = dest_resp.content
#保存数据的路径及文件名
download_path = os.getcwd() + "\download"
path = r'C:\Users\lenovo\Desktop\新建文件夹'
with open(os.path.join(path, str(i) + ".ts"), 'wb') as f:#写入文件夹
f.write(data)
print(i)
merge_file(r'C:\Users\lenovo\Desktop\新建文件夹')#存视频的文件夹
def merge_file(path):#合并视频
os.chdir(path)
cmd = "copy /b * new.tmp"
os.system(cmd)
os.system('del /Q *.ts')
os.system('del /Q *.mp4')
os.rename("new.tmp", "new.mp4")
if __name__ == '__main__':
download()
python 视频爬虫的更多相关文章
- Python之爬虫-酷6视频
Python之爬虫-酷6视频 #!/usr/bin/env python # -*- coding:utf-8 -*- import re import requests response = req ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- 小白必看Python视频基础教程
Python的排名从去年开始就借助人工智能持续上升,现在它已经成为了第一名.Python的火热,也带动了工程师们的就业热.可能你也想通过学习加入这个炙手可热的行业,可以看看Python视频基础教程,小 ...
- Python 正则表达式 (python网络爬虫)
昨天 2018 年 01 月 31 日,农历腊月十五日.20:00 左右,152 年一遇的月全食.血月.蓝月将今晚呈现空中,虽然没有看到蓝月亮,血月.月全食也是勉强可以了,还是可以想像一下一瓶蓝月亮洗 ...
- 【Python】Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
本文转载自:https://www.cnblogs.com/colipso/p/4284510.html 好文 mark http://www.52nlp.cn/python-%E7%BD%91%E9 ...
- Python 网络爬虫干货总结
Python 网络爬虫干货总结 爬取 对于爬取来说,我们需要学会使用不同的方法来应对不同情景下的数据抓取任务. 爬取的目标绝大多数情况下要么是网页,要么是 App,所以这里就分为这两个大类别来进行了介 ...
- 最全数据分析资料汇总(含python、爬虫、数据库、大数据、tableau、统计学等)
一.Python基础 Python简明教程(Python3) Python3.7.4官方中文文档 Python标准库中文版 廖雪峰 Python 3 中文教程 Python 3.3 官方教程中文版 P ...
随机推荐
- Model First 开发方式
概述 在项目一开始,没有数据库时,可以借助 EF 设计模型,然后根据模型同步完成数据库中表的创建,这就是 Model First 开发方式. 总结一点就是:现有模型再有表. 创建 Model Firs ...
- QVector常见使用方法
仅在此简单介绍QVector的一些常见函数,有兴趣的可以查下QT,在QT中介绍的很详细 构造函数,QVector的构造函数很多样化,常见的有 QVector() 无参的构造函数 QVector(int ...
- git提交步骤
1,为了确定在本地分支下操作,可以用命令查看一下是否在本地分支 git branch 2,可以查看状态,是否添加了哪些内容 git status 3,如果确认无误,使用命令进行提交本地代码,并加上注释 ...
- 安装pyspider遇到的坑
pyspider是国人写的一款开源爬虫框架,个人觉得这个框架用起来很方便,至于如何方便可以继续看下去. 作者博客:http://blog.binux.me/ 安装pyspider安装pyspider: ...
- linux-centos系统下安装python3.5.4步骤
查看当前python版本:python -V 查看Python可执行文件位置:which python [root@localhost bin]# which python/usr/bin/pytho ...
- laravel 记录
1.处理ajax跨域 使用 composer require barryvdh/laravel-cors
- websocket session共享
单机运行 用户a通过服务器进入房间room,用户b也通过房间进入room,用户之间是通过session来通话的,所以session直接存储在集合中就可以了. 因为session存储在一台服务器的集合中 ...
- Python输入数组(一维数组、二维数组)
一维数组: arr = input("") //输入一个一维数组,每个数之间使空格隔开 num = [int(n) for n in arr.split()] //将输入每个数以空 ...
- 活代码LINQ——09
一.代码 ' Fig. 9.7: LINQWithListCollection.vb ' LINQ to Objects using a List(Of String). Module LINQWit ...
- 北航OO第一单元总结
我本着公平公开公正的态度作出以下评价: 1.面向对象真的很修身养性 2.有一个好的身体非常重要 3.互相hack可以暴露人的阴暗面 好了,步入正题. 一.作业分析 1.第一次作业分析 1.1类图 1. ...