sklearn 中 make_blobs模块
# 生成用于聚类的各向同性高斯blob
sklearn.datasets.make_blobs(n_samples = 100,n_features = 2,center = 3,cluster_std = 1.0,center_box =( - 10.0,10.0),shuffle = True,random_state = None)
参数
n_samples: int, optional (default=100)
待生成的样本的总数。
n_features: int, optional (default=2)
每个样本的特征数。
centers: int or array of shape [n_centers, n_features], optional (default=3)
要生成的样本中心(类别)数,或者是确定的中心点。
cluster_std: float or sequence of floats, optional (default=1.0)
每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0]。
center_box: pair of floats (min, max), optional (default=(-10.0, 10.0))
中心随机生成时每个聚类中心的边界框。
shuffle:布尔值,可选(默认= True)
对样本进行随机播放。
random_state:int,RandomState实例或None,可选(default = None)
如果为int,random_state是随机数生成器使用的种子; 如果RandomState实例,random_state是随机数生成器; 如果为None,则随机数生成器是np.random使用的RandomState实例。
返回
X : array of shape [n_samples, n_features]
生成的样本数据集。
y : array of shape [n_samples]
样本数据集的标签。
例子
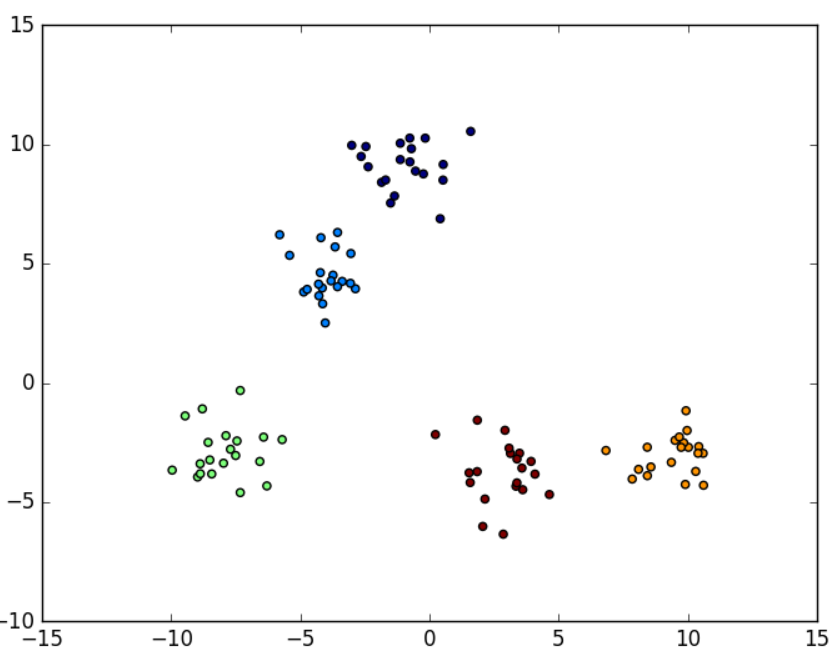
例如要生成5类数据(100个样本,每个样本有2个特征),代码如下
from sklearn.datasets import make_blobs
from matplotlib import pyplot data, label = make_blobs(n_samples=100, n_features=2, centers=5)
# 绘制样本显示
pyplot.scatter(data[:, 0], data[:, 1], c=label)
pyplot.show()
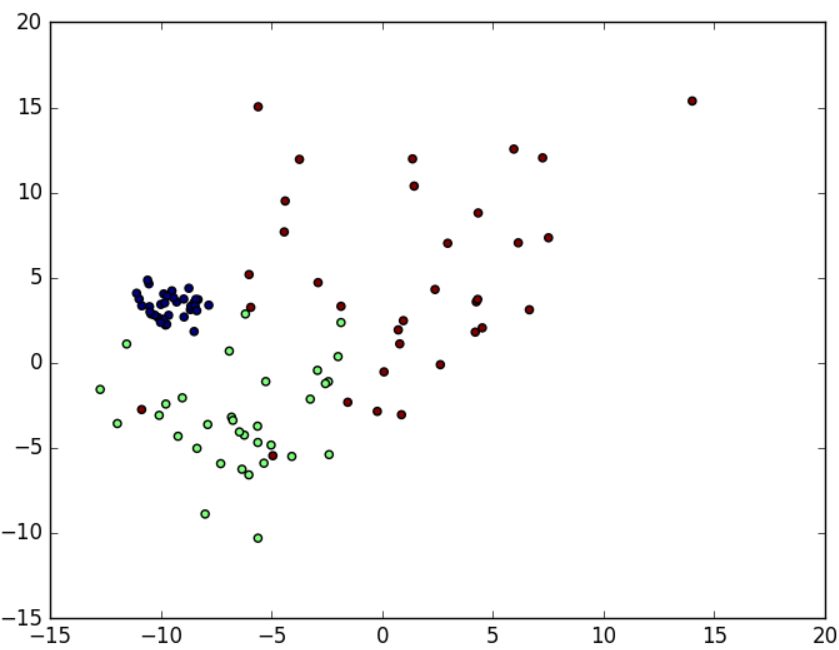
如果希望为每个类别设置不同的方差,需要在上述代码中加入cluster_std参数:
from sklearn.datasets import make_blobs
from matplotlib import pyplot data, label = make_blobs(n_samples=10, n_features=2, centers=3, cluster_std=[0.8, 2.5, 4.5])
# 绘制样本显示
pyplot.scatter(data[:, 0], data[:, 1], c=label)
pyplot.show()
sklearn 中 make_blobs模块的更多相关文章
- sklearn 中 make_blobs模块使用
sklearn.datasets.make_blobs(n_samples=100, n_features=2, centers=3, cluster_std=1.0, center_box=(-10 ...
- 【集成学习】sklearn中xgboost模块的XGBClassifier函数
# 常规参数 booster gbtree 树模型做为基分类器(默认) gbliner 线性模型做为基分类器 silent silent=0时,不输出中间过程(默认) silent=1时,输出中间过程 ...
- 【集成学习】sklearn中xgboost模块中plot_importance函数(绘图--特征重要性)
直接上代码,简单 # -*- coding: utf-8 -*- """ ################################################ ...
- sklearn中xgboost模块中plot_importance函数(特征重要性)
# -*- coding: utf-8 -*- """ ######################################################### ...
- 【集成学习】sklearn中xgboot模块中fit函数参数详解(fit model for train data)
参数解释,后续补上. # -*- coding: utf-8 -*- """ ############################################## ...
- sklearn中的metrics模块中的Classification metrics
metrics是sklearn用来做模型评估的重要模块,提供了各种评估度量,现在自己整理如下: 一.通用的用法:Common cases: predefined values 1.1 sklearn官 ...
- python中导入sklearn中模块提示ImportError: DLL load failed: 找不到指定的程序。
python版本:3.7 平台:windows 10 集成环境:Anaconda3.7 64位 在jupyter notebook中导入sklearn的相关模块提示ImportError: DLL l ...
- sklearn中的KMeans算法
1.聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇).这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布. 2.KMeans算法将一 ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
随机推荐
- UI- 五种手势识别总结
#pragma mark - 手势 总共有五种手势 分别为 Tap点击 Pan拖拽 LongPress长时间按压 Pinch捏合手势 rotation旋转 1. 定义成员变量 UIImageVie ...
- PostgreSQL java读取bytes字段
写入bytea: File img = new File("/tmp/eclipse.png"); fin = new FileInputStream(img); con = Dr ...
- access_ok | 检查用户空间内存块是否可用
access_ok() 函数是用来代替老版本的 verify_area() 函数的.它的作用也是检查用户空间指针是否可用. 函数原型:access_ok (type, addr, size); 变量说 ...
- 激活函数之ReLU/softplus介绍及C++实现
softplus函数(softplus function):ζ(x)=ln(1+exp(x)). softplus函数可以用来产生正态分布的β和σ参数,因为它的范围是(0,∞).当处理包含sigmoi ...
- Requst Servervariables
Request.ServerVariables("Url") 返回服务器地址 Request.ServerVariables("Path_Info") 客户端提 ...
- BaseCommand
import java.io.Serializable; import android.util.Log; public class BaseCommand implements Serializab ...
- WC2019 T1 数树
WC2019 T1 数树 传送门(https://loj.ac/problem/2983) Question 0 对于给定的两棵树,设记两颗树 \(A,B\) 的重边数量为 \(R(A,B)\),那么 ...
- 高级C/C++编译技术之读书笔记(三)之动态库设计
最近有幸阅读了<高级C/C++编译技术>深受启发,该书深入浅出地讲解了构建过程(编译.链接)中的各种细节,从多个角度展示了程序与库文件或代码的集成方法,提出了面向代码复用和系统集成的软件架 ...
- AtCoder Grand Contest 017 题解
A - Biscuits 题目: 给出 \(n\) 个物品,每个物品有一个权值. 问有多少种选取方式使得物品权值之和 \(\bmod\space 2\) 为 \(p\). \(n \leq 50\) ...
- Maven根据不同的环境打包不同的配置
前言: 在开发过程中,我们的软件会面对不同的运行环境,比如开发环境.测试环境.生产环境,而我们的软件在不同的环境中,有的配置可能会不一样,比如数据源配置.日志文件配置等等. 那么就需要借助maven提 ...