hadoop文件写入
转:http://blog.csdn.net/xiaoshunzi111/article/details/48198105

由上图可知;写入文件分为三个角色,分别是clientnode namenode 和datanode
cliennode本质为java虚拟机.namenode 和datanode则是Hadoop数据集群存储块
第一步:create实际是客户端创建DistributedFileSystem实例化对象
第二步 create通过实例化对象录取调用对象中create()方法,此方法访问namenode,namenode收到命令,首先判断datanode中所写的文件是否有重复,然后在检查namenode是否有可写入空余的空间.当二者同时满足是,namenode写将datanode路径信息,文件数等记录,并确认信息返回DistributedFileSystem,否则返回异常,DistributedFileSystem收到确认信息后向客户端返回一个FSDataOutputStream FSDataOutputStream对象
第三步:实例化FSDataOutputStream对象(该对象负责处理 datanode 和 namenode 之间的通信 ),调用该对象的write()方法, 即是图中write实现过程该对象负责处理 datanode 和 namenode 之间的通信
第四步:方法将数据分成多个数据包,并写入内部队列. DFDataOutStream 将写入的数据分成多个数据包,并写入内部队列中,同时开启datanode中DataStreamer处理数据队列,它负责根据datanode列来要求namenode分配合适的新块存储数据备份开启管道机制依次执行步骤4,同时即是write packet完整过程
第五步:每执行一次4就有一次步骤5返回确认信息.
4和5属于分别在DataQueue队列和ACKQueue队列,当每执行一次4就将此步确认信息放到ACKQueue队列中
如图:
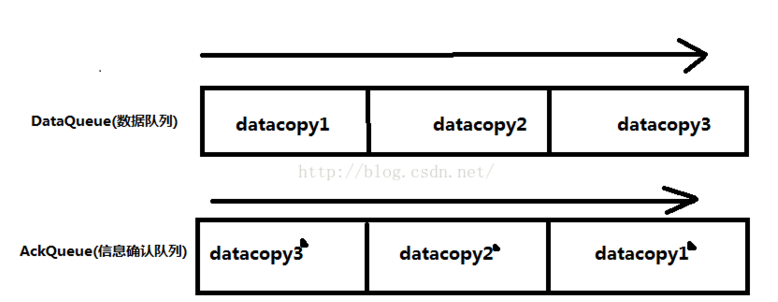
第六步:当FSDataOutputStream收到确认信息后,执行close()方法关闭输出流,
第七步:DistributeFileStream 返回给namenode确认信息.
注释:第4-5部分实现在后台完成步不一定在第七步之前,
当执行第四步就就收第5步确认信息,告诉namenode 数据写入成功,即是第七步.
hadoop文件写入的更多相关文章
- Hadoop学习笔记(3) Hadoop文件系统一
1. 分布式文件系统,即为管理网络中跨多台计算机存储的文件系统.HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上.HDFS的构建思路为:一次写入.多次读取是最高效的访问模式.数据集通常由 ...
- hdfs文件写入kafka集群
1. 场景描述 因新增Kafka集群,需要将hdfs文件写入到新增的Kafka集群中,后来发现文件不多,就直接下载文件到本地,通过Main函数写入了,假如需要部署到服务器上执行,需将文件读取这块稍做修 ...
- Java文件写入,换行
import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; import java.io.IOExce ...
- 视频文件写入转换之图像处理-OpenCV应用学习笔记五
在<笔记二>中我们做了视频播放和控制的实现,仅仅算是完成了对视频文件的读取操作:今天我们来一起练习下对视频文件的写入操作:格式转换. 实现功能: 打开一个视频文件play.avi,读取文件 ...
- Python学习笔记——文件写入和读取
1.文件写入 #coding:utf-8 #!/usr/bin/env python 'makeTextPyhton.py -- create text file' import os ls = os ...
- Sqli-LABS通关笔录-7[文件写入函数Outfile]
该关卡最主要的就是想要我们学习到Outfile函数(文件写入函数)的使用. 通过源代码我们很容易的写出了payload.倘若我们一个个去尝试的话,说实话,不容易. http://127.0.0.1/s ...
- 将gridFS中的图片文件写入硬盘
开启用户验证下的gridfs 连接使用,在执行脚本前可以在python shell中 from pymongo import Connectionfrom gridfs import *con = C ...
- PHP文件读写操作之文件写入代码
在PHP网站开发中,存储数据通常有两种方式,一种以文本文件方式存储,比如txt文件,一种是以数据库方式存储,比如Mysql,相对于数据库存储,文件存储并没有什么优势,但是文件读写操作在基本的PHP开发 ...
- Java学习-018-EXCEL 文件写入实例源代码
众所周知,EXCEL 也是软件测试开发过程中,常用的数据文件导入导出时的类型文件之一,此文主要讲述如何通过 EXCEL 文件中 Sheet 的索引(index)或者 Sheet 名称获取文件中对应 S ...
随机推荐
- Http请求get和post调用
工作中会遇到远程调用接口,需要编写Http请求的共通类 以下是自己总结的Http请求代码 package com.gomecar.index.common.utils; import org.apac ...
- logistic 回归Matlab代码
function a alpha = 0.0001; [m,n] = size(q1x); max_iters = 500; X = [ones(size(q1x,1),1), q1x]; % app ...
- kali学习
kali视频学习 第二周 kali视频(1-5) 1.kali安装 2.基本配置 vmtools安装过程. 3.安全渗透测试一般流程 4.信息搜集之GoogleHack 5.信息搜集之目标获取 第三周 ...
- python操作RabbitMQ(不错)
一.rabbitmq RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列 ...
- Python 函数 -slice()
功能: slice() 函数实现切片对象,主要用在切片操作函数里的参数传递.返回一个切片对象. 语法: class slice(stop) class slice(start, stop[, step ...
- CentOS中使用Shell脚本实现每天自动备份网站文件和数据库并上传到FTP中(转)
http://www.jb51.net/article/58843.htm 一.安装Email发送程序 复制代码 代码如下: yum install sendmail mutt 二.安装FTP客户端程 ...
- selenium - 截取页面图片和截取某个元素的图
1.截取页面图片并保存 在测试过程中,是有必要截图,特别是遇到错误的时候进行截图. # coding:utf-8 from time import sleep from PIL import Imag ...
- Timer的异常
定时任务用Timer实现有可能出现异常,因为它是基于绝对时间而不是相对时间进行调度的.当环境的系统时间被修改后,原来的定时任务可能就不跑了.另外需要注意一点,捕获并处理定时任务的异常.如果在Timer ...
- Linux yum操作时出现Error: xz compression not available
yum升级PHP版本的时候出现这个问题 由于CentOS6的系统安装了epel-release-latest-7.noarch.rpm 导致在使用yum命令时出现Error: xz compressi ...
- java代码---继承-子类使用继承父类的属性。理解测试
总结:对于继承.如果父类有的成员变量而子类没有,那么子类的成员变量赋值是来自于父类的,当在子类构造方法赋值时,它和父类的成员变量值是一样的 当成员变量在父类和子类中都存在时,父类用父类的属性,子类用子 ...