EM算法(expectation maximization)
EM算法简述
EM算法是一种迭代算法,主要用于含有隐变量的概率模型参数的极大似然估计,或极大后验概率估计。EM算法的每次迭代由两步完成:
E步,求期望
M步,求极大。
EM算法的引入
如果概率模型的变量都是观测变量,那么给定数据,可以直接用极大似然估计法或贝叶斯估计法估计模型参数,但是当模型中含有隐变量时,就不能简单地使用这些估计方法。因此提出了EM算法。
EM算法流程
假定集合  由观测数据
由观测数据  和未观测数据
和未观测数据  组成,
组成,  和 分别称为不完整数据和完整数据。假设Z的联合概率密度被参数化地定义为
和 分别称为不完整数据和完整数据。假设Z的联合概率密度被参数化地定义为  ,其中
,其中  表示要被估计的参数。 的最大似然估计是求不完整数据的对数似然函数
表示要被估计的参数。 的最大似然估计是求不完整数据的对数似然函数 的最大值而得到的:
的最大值而得到的: EM算法包括两个步骤:由E步和M步组成,它是通过迭代地最大化完整数据的对数似然函数
EM算法包括两个步骤:由E步和M步组成,它是通过迭代地最大化完整数据的对数似然函数  的期望来最大化不完整数据的对数似然函数,其中:
的期望来最大化不完整数据的对数似然函数,其中: 假设在算法第t次迭代后
假设在算法第t次迭代后  获得的估计记为
获得的估计记为  ,则在(t+1)次迭代时,E-步:计算完整数据的对数似然函数的期望,记为:
,则在(t+1)次迭代时,E-步:计算完整数据的对数似然函数的期望,记为: M-步:通过最大化
M-步:通过最大化  来获得新的
来获得新的  。通过交替使用这两个步骤,EM算法逐步改进模型的参数,使参数和训练样本的似然概率逐渐增大,最后终止于一个极大点。
。通过交替使用这两个步骤,EM算法逐步改进模型的参数,使参数和训练样本的似然概率逐渐增大,最后终止于一个极大点。
直观地理解EM算法,它也可被看作为一个逐次逼近算法:事先并不知道模型的参数,可以随机的选择一套参数或者事先粗略地给定某个初始参数,确定出对应于这组参数的最可能的状态,计算每个训练样本的可能结果的概率,在当前的状态下再由样本对参数修正,重新估计参数λ,并在新的参数下重新确定模型的状态,这样,通过多次的迭代,循环直至某个收敛条件满足为止,就可以使得模型的参数逐渐逼近真实参数。
可见上述算法流程中Q()是EM算法的核心,称为Q函数。
即完整数据的对数似然函数logP(x,y|)关于在给定观测数据x和当前参数下对未观测数据y的条件概率分布P(y|x,)的期望称为Q函数,
EM算法的导出
我们面对一个含有隐变量的概率模型,目标是极大化观测数据(不完全数据)x关于参数的对数似然函数,即极大化
L()=logP(x|)=logΣyP(X,y|)=log(ΣyP(X|y,)P(y|))
注意到这一极大化主要困难是式中有未观测数据并有包含和(或积分)的对数
示例
给定样本T = {X1, X2, …, Xm},现在想给每个Xi一个Zi,即标出: {(X1,Z1), (X2,Z2),…,(Xm,Zm)}(z是隐形变量,zi=j可以看成是Xi被划分为j类),求对T的最大似然估计:
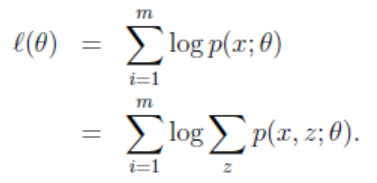
其实Zi也是个向量,因为对于每一个Xi,都有多种分类的情况。设第i个样本Xi在Z上的概率分布为Qi(Zi),即Qi(Zi=j)表示Xi被划分到类j的概率,因此有ΣQi(Zi) = 1。
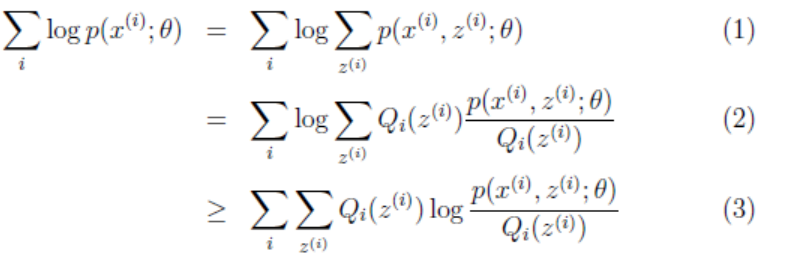
(2)到(3)是利用Jensen不等式,因为log(x)为凹函数,且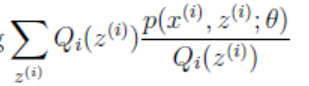 这个就是p(xi, zi; θ)/Qi(zi)的期望。
这个就是p(xi, zi; θ)/Qi(zi)的期望。
现在,根据Jensen不等式取等号的条件:
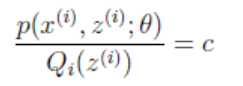
因为这个式子对于Zi等于任何值时都成立,且有ΣQi(Zi) = 1,所以可以认为:Σp(xi, zi;θ) = c。此时可以推出:
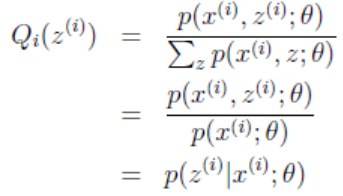
式子中,Zi是自变量,若θ已知,则可计算出Qi(zi)。
至此,终于可以描述算法过程了:
1)给θ一个初始值;
2)固定当前的θ,让不等式(3)取等号,算出Qi(zi);-------> E 步
3)将2)算出的Qi(zi)代入g(Q, θ) = 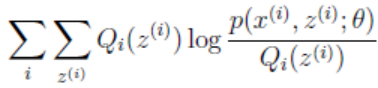 ,并极大化g(Q,θ),得到新的θ。-------------->M步
,并极大化g(Q,θ),得到新的θ。-------------->M步
4)循环迭代2)、3)至收敛。
证明EM算法收敛
当θ取到θt值时,求得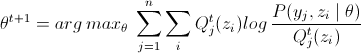
那么可得如下不等式:
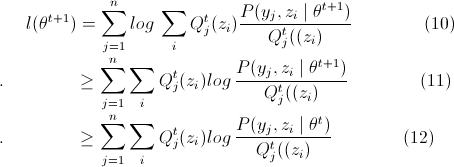
(10)=>(11)是因为Jensen不等式,因为等号成立的条件是θ为θt的时候得到的 ,而现在
,而现在 中的θ值为θt+1,所以等号不一定成立,除非θt+1=θt,
中的θ值为θt+1,所以等号不一定成立,除非θt+1=θt,
(11)=>(12)是因为θt+1已经使得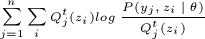 取得最大值,那必然不会小于(12)式。
取得最大值,那必然不会小于(12)式。
所以l(θ)在迭代下是单调递增的,且很容易看出l(θ)是有上界的(单调有界收敛),则EM算法收敛性得证。
EM算法E步说明
上述EM算法描述,主要是参考Andrew NG教授的讲义,如果看过李航老师的《统计方法学》,会发现里面的证明以及描述表明上有些许不同,Andrew NG教授的讲义的说明(如上述)将隐藏变量的作用更好的体现出来,更直观,证明也更简单,而《统计方法学》中则将迭代之间θ的变化罗列的更为明确,也更加准确的描述了EM算法字面上的意思:每次迭代包含两步:E步,求期望;M步,求极大化。下面列出《统计方法学》书中的EM算法,与上述略有不同:
EM算法(2):
选取初始值θ0初始化θ,t=0
Repeat {
E步:
M步:
}直到收敛
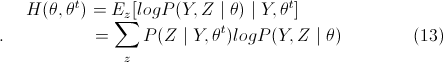
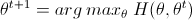
(13)式中,Y={y1,y2,...,ym},Z={z1,z2,...,zm},不难看出将(9)式中两个Σ对换,就可以得出(13)式,而(13)式即是关于分布z的一个期望值,而需要求这个期望公式,那么要求出所有的EM算法(1)中E步的值,所以两个表明看起来不同的EM算法描述其实是一样的。
总结:EM算法就是通过迭代地最大化完整数据的对数似然函数的期望,来最大化不完整数据的对数似然函数。
参考文献:
1.《统计学习方法》
2. http://blog.csdn.net/hechenghai/article/details/41896213
3.https://baike.baidu.com/item/em%E7%AE%97%E6%B3%95/1866163?fr=aladdin
EM算法(expectation maximization)的更多相关文章
- EM算法(Expectation Maximization Algorithm)
EM算法(Expectation Maximization Algorithm) 1. 前言 这是本人写的第一篇博客(2013年4月5日发在cnblogs上,现在迁移过来),是学习李航老师的< ...
- EM算法(Expectation Maximization)
1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成绩的分 ...
- EM算法(Expectation Maximization Algorithm)初探
1. 通过一个简单的例子直观上理解EM的核心思想 0x1: 问题背景 假设现在有两枚硬币Coin_a和Coin_b,随机抛掷后正面朝上/反面朝上的概率分别是 Coin_a:P1:-P1 Coin_b: ...
- 简单理解EM算法Expectation Maximization
1.EM算法概念 EM 算法,全称 Expectation Maximization Algorithm.期望最大算法是一种迭代算法,用于含有隐变量(Hidden Variable)的概率参数模型的最 ...
- EM 算法 Expectation Maximization
- EM(Expectation Maximization)算法
EM(Expectation Maximization)算法 参考资料: [1]. 从最大似然到EM算法浅解 [2]. 简单的EM算法例子 [3]. EM算法)The EM Algorithm(详尽 ...
- 最大期望算法 Expectation Maximization概念
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Lat ...
- 机器学习-EM算法
最大期望算法 EM算法的正式提出来自美国数学家Arthur Dempster.Nan Laird和Donald Rubin,其在1977年发表的研究对先前出现的作为特例的EM算法进行了总结并给出了标准 ...
- 数据挖掘十大经典算法(5) 最大期望(EM)算法
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Lat ...
- EM算法及其推广
概述 EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计. EM算法的每次迭代由两步组成:E步,求期望(expectation): ...
随机推荐
- centos下nginx启动脚本和chkconfig管理
在安装完nginx后,重新启动需要“kill -HUP nginx进程编号”来进行重新加载,显然十分不方便.如果能像apache一样,直接通过脚本进行管理就方便多了. nginx官方早就想好了,也提供 ...
- 如何高效利用github提升自己
作为开源代码库以及版本控制系统,Github拥有超过900万开发者用户,是开发者打开程序开源大门的一扇窗口,也是开发者快速提升自己的一个重要途径.本文将从两个方面介绍github的使用方式. 和逛微博 ...
- UVa 11997 K Smallest Sums 优先队列&&打有序表&&归并
UVA - 11997 id=18702" target="_blank" style="color:blue; text-decoration:none&qu ...
- 小程序图表功能wxchart实现
在开发小程序过程中,有项目用到图表功能, 其实Echart.js有小程序的库,我们要吧引入进来,然后配置初始化一下,就可以达到目的了.接下来就开始步骤吧 首先下载JS库:http://download ...
- 5 月 35 日临近,Google 无法访问,可以使用 Google IP 来解决。
每年都会有几天那啥,你懂的. 直接使用 Google 的域名访问经常会打不开,而使用 Google 的 IP 就会很顺畅. 使用 Chrome 浏览器我们经常都会在地址栏直接搜索,所以我们只要添加一个 ...
- springboot开启事务管理
spring中开启事务管理需要在xml配置文件中配置,springboot中采取java config的配置方式. 核心是@EnableTransactionManager注解,该注解即为开启事务管理 ...
- Android Studio 使用笔记:[转] Mac下修改Android Studio 所用的JDK版本
原文链接:http://www.jianshu.com/p/d8d1d72d0248# 最近项目从Eclipse+Ant构建模式转移到了Android Studio+Gradle构建模式,自然的JDK ...
- 【实用】如何在windows下快速截图?
如何在windows下快速截图? 快速截图是很多人的需求.截图的工具和方案也很多,但是,这里给出一个通用的,被大众认为最高效的一个解决方案. 我们都知道键盘上有一个"prt sc" ...
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
豆瓣有些电影页面需要登录才能查看. 目录 [隐藏] 1 创建工程 2 定义Item 3 编写爬虫(Spider) 4 存储数据 5 配置文件 6 艺搜参考 创建工程 scrapy startproj ...
- Windows下使用python
Windows下使用python,一般安装python就有IDLE了,再这个里面使用就好了,很方便 安装完之后.py的文件右键会有Edit with IDLE,可是我脑残想要默认打开就是IDLE,结果 ...