scrapy入门实践1
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
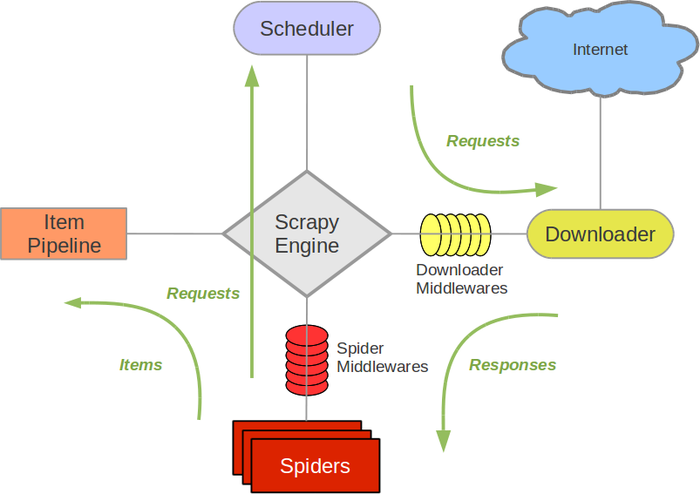
这就是整个Scrapy的架构图了;
各部件职能:
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。简单的说,就是负责从引擎接受request并入队,当引擎请求他们时返回request
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,获取页面数据并提供给引擎,并将其获取到的Responses交还给Scrapy Engine(引擎),而后由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
数据在整个Scrapy的流向:
通俗版:
程序运行的时候,
引擎:Hi!Spider, 你要处理哪一个网站?
Spiders:我要处理23wx.com
引擎:你把第一个需要的处理的URL给我吧。
Spiders:给你第一个URL是XXXXXXX.com
引擎:Hi!调度器,我这有request你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request给我,
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照下载中间件的设置帮我下载一下这个request
下载器:好的!给你,这是下载好的东西。(如果失败:不好意思,这个request下载失败,然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载。)
引擎:Hi!Spiders,这是下载好的东西,并且已经按照Spider中间件处理过了,你处理一下(注意!这儿responses默认是交给def parse这个函数处理的)
Spiders:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,这是我需要跟进的URL,将它的responses交给函数 def xxxx(self, responses)处理。还有这是我获取到的Item。
引擎:Hi !Item Pipeline 我这儿有个item你帮我处理一下!调度器!这是我需要的URL你帮我处理下。然后从第四步开始循环,直到获取到你需要的信息,
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy会重新下载。)
再总结下,流程是:
核心引擎从爬虫获取初始url,并生成一个Request任务投入Scheduler调度计划里
引擎向调度器请求一个新的Request爬取任务并转发给downloader下载器
下载器载入页面并返回一个Response响应给引擎
引擎将Response转发给Spider爬虫做 数据提取 和 搜索新的跟进地址
处理结果由引擎做分发:提取的数据 -> ItemPipeline管道,新的跟进地址Request -> 调度器
流程返回第二步循环执行,直至调度器中的任务被处理完毕
scrapy入门实践1的更多相关文章
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- 分布式学习系列【dubbo入门实践】
分布式学习系列[dubbo入门实践] dubbo架构 组成部分:provider,consumer,registry,monitor: provider,consumer注册,订阅类似于消息队列的注册 ...
- [转]Scrapy入门教程
关键字:scrapy 入门教程 爬虫 Spider 作者:http://www.cnblogs.com/txw1958/ 出处:http://www.cnblogs.com/txw1958/archi ...
- sass、less和stylus的安装使用和入门实践
刚 开始的时候,说实话,我很反感使用css预处理器这种新玩意的,因为其中涉及到了编程的东西,私以为很复杂,而且考虑到项目不是一天能够完成的,也很少是 一个人完成的,对于这种团队的项目开发,前端实践用c ...
- Scrapy入门教程
关键字:scrapy 入门教程 爬虫 Spider作者:http://www.cnblogs.com/txw1958/出处:http://www.cnblogs.com/txw1958/archive ...
- Django入门实践(三)
Django入门实践(三) Django简单应用 前面简单示例说明了views和Template的工作过程,但是Django最核心的是App,涉及到App则会和Model(数据库)打交道.下面举的例子 ...
- Django入门实践(二)
Django入门实践(二) Django模板简单实例 上篇中将html写在了views中,这种混合方式(指Template和views混在一起)不适合大型开发,而且代码不易管理和维护,下面就用Djan ...
- Django入门实践(一)
Django入门实践(一) Django编程思路+入门 认识Django有一个多月了,我觉得学习Django应该先理清它的编程思路.它是典型的MVC框架(在Django里也称MTV),我觉得Djang ...
- 全文搜索引擎Elasticsearch入门实践
全文搜索引擎Elasticsearch入门实践 感谢阮一峰的网络日志全文搜索引擎 Elasticsearch 入门教程 安装 首先需要依赖Java环境.Elasticsearch官网https://w ...
随机推荐
- idea java web 使用说明
String realPath = request.getSession().getServletContext().getRealPath(uploadPath);//上传压缩包所在目录 ...
- docker devise相关错误
rake aborted!Devise.secret_key was not set. Please add the following to your Devise initializer: con ...
- HTTP学习笔记01-URL
URI URL语法 相对URL和绝对URL 相对URL URL的常用协议 http https mailto ftp rtsprtspu file news telnet 展望美好的未来 1.URI ...
- Qt5.4.1移植到arm——Linuxfb篇
Qt5与Qt4对比有很大的改变,其最大的特性在于模块化,并且很明显的是不再见到Qt4用到的qws,Qt5新增了QPA系统,基于QPA使得Qt5移 植到一个新平台非常简单而又具有极强的底层扩展能力:同时 ...
- python__Django 分页
自定义分页的类: #!/usr/bin/env python # -*- coding: utf-8 -*- # Created by Mona on 2017/9/20 from django.ut ...
- 正则表达式 获取字符串内提取图片URL字符串
#region 获取字符串内提取图片URL字符串 /// <summary> /// 获取字符串内提取图片URL字符串 /// </summary> /// <param ...
- package.json字段简要解析
name 必填 应用名称 version 必填 应用版本 description 选填 应用描述,多用于搜索,在npm search 时可以用到 keywords 选填 应用关键字,也多用于搜索 sc ...
- linux usb简介
参考书:<linux device drivers>.<usb 2.0规范> <usb3.1规范><usb白皮书> 以linux为例来说明usb系统. ...
- 通过加载Xib文件来创建UITableViewCell造成复用数据混乱问题方案
- (UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPa ...
- java-jpa-criteriaBuilder使用入门
项目中使用jpa ,第一次见查询起来一脸蒙,这就去查下jpa查询的方式,和概念. jpa 元模型 criteria 查询 CriteriaBuilder 安全查询创建工厂 CriteriaQuery ...