MySQL 性能测试经验
一、背景
近期在进行资源调度管理平台的重构工作,其中的Resource/Property数据库设计,在没有更加优化的方案前,打算沿用当前平台的数据库结构;这就需要对当前平台的数据库结构进行剖析研究,并对其性能进行测试与分析,得出的数据结果作为后续设计和优化的参考。
二、测试方法
1、测试工具:mysqlslap,mysqlslap是MySQL5.1.4之后自带的benchmark基准测试工具,该工具可以模拟多个客户端同时并发的向服务器发出查询更新,给出了性能测试数据而且提供了多种引擎的性能比较。官方介绍:http://dev.mysql.com/doc/refman/5.6/en/mysqlslap.html,
使用方法:http://my.oschina.net/moooofly/blog/152547
2、测试流程:建立测试数据库database和待测试的表tables → 根据table的结构,利用脚本生成一定数量的有效随机数据 → 利用mysqlslap对相应query语句进行测试 → 结果数据的分析。
3、关键语句:考虑到资源平台的实际应用情况,通过资源属性查询资源的操作为主要操作,且这类操作的耗时占总操作耗时的比例为最大,故对应这类操作的查询语句为关键语句,对整个数据库性能影响很大,我们可以通过测试这个关键语句得出的结果来评估整个数据库的性能。
三、测试过程
1、建表:
通过属性查询资源需要两张表:设备表device和设备属性对应表deviceattr。device表对应资源,记录资源的基本信息,如name,type,group,creator等等;deviceattr表对应资源和属性的关系,记录每个资源的每个属性和属性值;它们的结构如下所示:


通过多个属性组合查询deviceattr表,获得相应的id ,id即是满足条件的设备id,进而能直接在device表中查询得到其基本属性。
本次测试的关键语句即是从deviceattr表中组合查询出满足条件的id,故本测试只需要用到deviceattr一张表。
2、生成随机数据并插入相应的表中:
这里编写了几个生成随机数据的sql函数rand_name(),rand_value(),rand_num(),rand_creator(),并编写了存储过程insert_devattr,用来将一定量数据批量插入deviceattr表中。
然后将整个建表和存储数据的过程写进一个sql脚本中,并在mysql中运行这个脚本,待测试的表和数据就建立好了。(sql脚本在附录)如下图所示,生成的deviceattr随机数据有4020条:
3、利用mysqlslap进行测试:
整个数据库的关键操作为通过属性查询资源,该操作的关键sql语句就是:
select id from deviceattr where [ n attr ] group by id;
例:查询拥有attr10或者attr20属性的所有资源的id为:
select id from deviceattr where name = ‘attr10’ or name = ‘attr20’ group by id;
在建立好待测数据库后,就可以利用mysqlslap进行测试,mysqlslap命令如下所示:
shell < mysqlslap --create-schema='test1' --query="select id from deviceattr where name='attr10' or name='attr20' group by id;" -c 50 -i 100
以上语句表示:使用test1数据库,使用query所指定的语句,测试50个并发查询,每一个查询100次。
该语句的测试结果如下图所示:

结果中可以看到执行语句的平均耗时,最大耗时和最小耗时,并发线程数等等。
四、结果分析
在不同数据容量,不同并发数,不同查询属性数的条件下进行多次测试并取平均值,所得到的数据分以下几种情况进行分析:
1、在deviceattr表数据容量为4000条,并发数分别为1、5、10、20、40、80,查询属性数分别为2、3、4、5、6的情况下,查询语句的耗时:
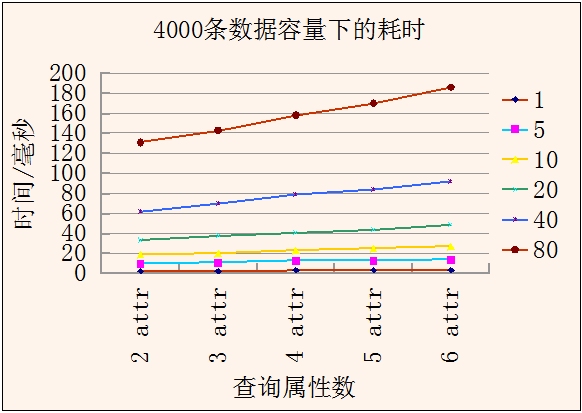
从上表可以看出,在查询属性数相同条件下,并发数增长一倍,耗时也基本增加一倍;在40并发数以下时,查询耗时不超过100毫秒;在10并发左右的实际应用情况下,耗时在40毫秒左右;性能基本满足新资源平台的要求。
2、在10并发,deviceattr表容量分别为3000、4000、8000条,查询属性数从2至6的情况下,查询语句的耗时:
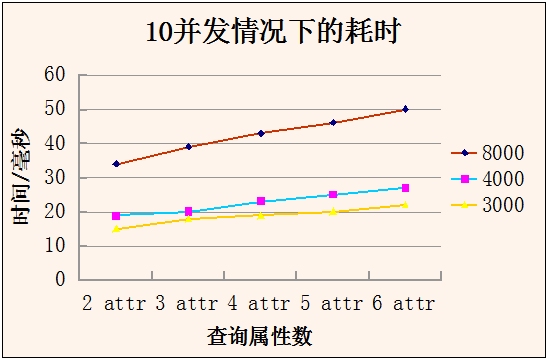
从上表可以看出,在并发数一定的情况下,随着语句中查询属性数的增多,耗时线性增加,这种线性关系数据容量无关。
3、在10并发,查询属性数为5,不同数据容量的情况下,查询语句的耗时:
从上表可以看出,在其他条件一定的情况下,随着数据容量的增长,耗时呈线性增长,在贴近实际条件的情况下(4000左右数据容量,10左右并发数,5左右查询属性),耗时为25毫秒,满足新资源管理平台的需求。
附录:
生成测试数据的sql脚本:
use test1
drop table if exists device,attr,deviceattr;
drop function if exists rand_name;
drop function if exists rand_value;
drop function if exists rand_num;
drop function if exists rand_creator;
drop procedure if exists insert_devattr;
drop procedure if exists insert_dev;
create table device
(
id int primary key,
name varchar(40),
type varchar(40),
aquired int,
groupname varchar(40),
creator varchar(40)
);
create table attr
(
id int primary key,
name varchar(40)
);
create table deviceattr
(
id int,
name varchar(40),
value varchar(40)
);
delimiter //
create function rand_creator()
returns varchar(20)
begin
declare return_str varchar(20) default 'aronhe';
declare n int default 0;
set n = floor(rand()*10);
case n
when 0 then set return_str = 'aronhe';
when 1 then set return_str = 'eeelin';
when 2 then set return_str = 'shadowyang';
when 3 then set return_str = 'luzhao';
when 4 then set return_str = 'tommyzhang';
when 5 then set return_str = 'pillarzou';
when 6 then set return_str = 'allenpan';
when 7 then set return_str = 'beyondli';
when 8 then set return_str = 'minshi';
when 9 then set return_str = 'bingchen';
else set return_str = 'joyhu';
end case;
return return_str;
end//
create function rand_num()
returns int
begin
declare n int default 0;
set n = floor(rand()*100);
return n;
end//
create function rand_value()
returns varchar(10)
begin
declare return_str varchar(10) default 'false';
declare n int default 0;
set n = floor(rand()*10);
case
when n<5 then set return_str = 'false';
when n>5 then set return_str = 'true';
else set return_str = 'true';
end case;
return return_str;
end//
create function rand_name()
returns varchar(20)
begin
declare return_str varchar(20) default '';
set return_str = concat('attr',floor(rand()*200));
return return_str;
end//
create procedure insert_devattr(in start int,in max int)
begin
declare i int default 0;
repeat
set i=i+1;
insert into deviceattr values(rand_num(),rand_name(),rand_value());
until i =max
end repeat;
end//
create procedure insert_dev(in start int,in max int)
begin
declare i int default 10;
repeat
set i=i+1;
insert into device values(i,concat('runner',floor(rand()*100)),'pc',floor(rand()*2),'PCQQ',rand_creator());
until i =max
end repeat;
end//
call insert_devattr(0,4000)//
call insert_dev(11,100)//
MySQL 性能测试经验的更多相关文章
- paip.mysql 性能测试 报告 home right
paip.mysql 性能测试 报告 home right 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog ...
- paip.mysql 性能测试by mysqlslap
paip.mysql 性能测试by mysqlslap 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog. ...
- mysql性能测试--sysbench实践
mysql性能测试--sysbench实践 Sysbench 业界较为出名的性能测试工具 可以测试磁盘,CPU,数据库 支持多种数据库:oracle,DB2,MYSQL 需要自己下载编译安装 建议 ...
- mysql性能测试-tpcc
mysql性能测试-tpcc Tpcc-mysql TPC-C是专门针对联机交易处理系统(OLTP系统)的规范 Tpcc-mysql由percona根据规范实现 TPCC流程 更能模拟线上业务 ...
- MySQL性能测试工具之mysqlslap
MySQL性能测试工具之mysqlslap [日期:2014-10-05] 来源:Linux社区 作者:tongcheng [字体:大 中 小] --转自Linux社区:http://www.l ...
- mysql性能测试-------重要!!!
我们在做性能测试的目的是什么,就是要测出一个系统的瓶颈在哪里,到底是哪里影响了我们系统的性能,找到问题,然后解决它.当然一个系统由很多东西一起组合到一起,应用程序.数据库.服务器.中中间件等等很多东西 ...
- MySQL性能测试调优
MySQL性能测试调优 操作系统 基本操作 查看磁盘分区mount选项 $ mount 永久修改分区mount选项(系统重启后生效) 修改文件 /etc/fstab 中对应分区的mount optio ...
- 一文了解MySQL性能测试及调优中的死锁处理方法,你还看不明白?
一文了解MySQL性能测试及调优中的死锁处理方法,你还看不明白? 以下从死锁检测.死锁避免.死锁解决3个方面来探讨如何对MySQL死锁问题进行性能调优. 死锁检测 通过SQL语句查询锁表相关信息: ( ...
- 关于网络上的各种mysql性能测试结论
关于网上的各种性能测试帖子,我想说以下几点: 1.为了使性能测试更加的客观.实际,应该说明针对什么场景进行测试,查询.还是修改,是否包含了主键,包含了几个索引,各自的差别是什么.因为不同的mysql分 ...
随机推荐
- spring3: 延迟初始化Bean
3.3.1 延迟初始化Bean 延迟初始化也叫做惰性初始化,指不提前初始化Bean,而是只有在真正使用时才创建及初始化Bean. 配置方式很简单只需在<bean>标签上指定 “lazy- ...
- 在UIElement外面多套一层布局面板(Grid、StackPanel)的意义
在一个UIElement或多个UIElement外面套上一层布局面板(Grid.StackPanel),可以起到统一管理作用(非重点关注):另外,更重要的是:可以起到扩大UIElement操作有效范围 ...
- 牛客比赛-状压dp
链接:https://www.nowcoder.com/acm/contest/74/F来源:牛客网 德玛西亚是一个实力雄厚.奉公守法的国家,有着功勋卓著的光荣军史. 这里非常重视正义.荣耀.职责的意 ...
- C++多态、虚函数、纯虚函数、抽象类
多态 同一函数调用形式(调用形式形同)可以实现不同的操作(执行路径不同),就叫多态. 两种多态: (1)静态多态:分为函数重载和运算符重载,编译时系统就能决定调用哪个函数. (2)动态多态(简称多态) ...
- 使用display:inline-block产生间隙
使用display:inline-block产生间隙 一.产生的原因:当初设立标准的不是亚洲而是欧洲,inline元素为了正确显示英文字母如y j g等带有尾巴的,就在底下留空.二.解决办法: 四个d ...
- jsp和servlet学习总结
一.Jsp与servlet的区别: jsp是java代码嵌入html中,用java代码控制来html. Servlet完全是JAVA程序代码构成,用来流程控制和事务处理 jsp更擅长表现于页面显示,s ...
- h5使用模块模板,循环输出模块列表
博主使用freemarker为框架,不过不影响功能的说明,首先来看看成品效果图 然后是html [#import "/common/layout.ftl" as layout] [ ...
- PostgreSQL流复制记录
参考了别人的部分,添加了自己在实践中的内容,仅做记录. 1.同步流复制中 主机操作 1.1postgresql.conf wal_level = hot_standby # 这个是设置主为wal的主机 ...
- Arcgis for Js之GeometryService实现测量距离和面积
距离和面积的测量时GIS常见的功能,在本节,讲述的是通过GeometryService实现测量面积和距离.先看看实现后的效果: 距离 ...
- 多进程(了解):守护进程,互斥锁,信号量,进程Queue与线程queue(生产者与消费者模型)
一.守护进程 主进程创建守护进程,守护进程的主要的特征为:①守护进程会在主进程代码执行结束时立即终止:②守护进程内无法继续再开子进程,否则会抛出异常. 实例: from multiprocessing ...