elasticsearch5.6.8中文分词器
安装分词器,务必确保版本一致!
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
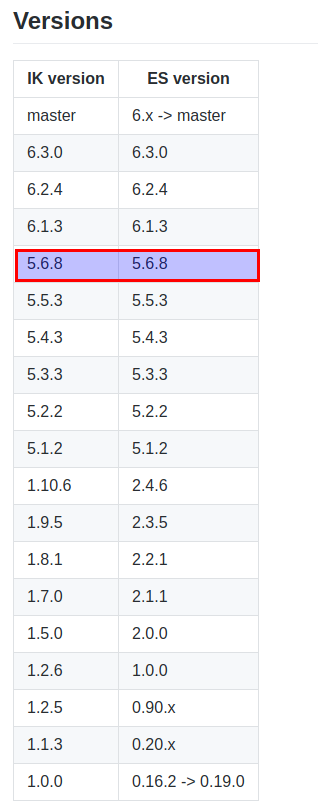
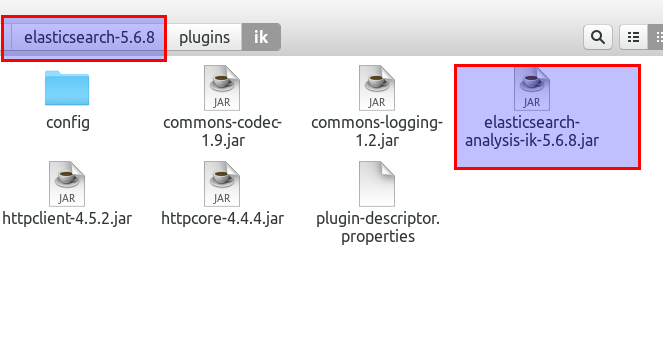
为了保证一致,我特地将elasticsearch进行降级。
ik_smart
GET _analyze?pretty
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 1
}
]
}
ik_max_word
GET _analyze?pretty
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "中华人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
},
{
"token": "人民共和国",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 7
},
{
"token": "国",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 8
},
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 9
}
]
}
elasticsearch5.6.8中文分词器的更多相关文章
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- ElasticSearch安装中文分词器IK
1.安装IK分词器,下载对应版本的插件,elasticsearch-analysis-ik中文分词器的开发者一直进行维护的,对应着elasticsearch的版本,所以选择好自己的版本即可.IKAna ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- 11大Java开源中文分词器的使用方法和分词效果对比
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Solr入门之(8)中文分词器配置
Solr中虽然提供了一个中文分词器,但是效果很差,可以使用IKAnalyzer或Mmseg4j 或其他中文分词器. 一.IKAnalyzer分词器配置: 1.下载IKAnalyzer(IKAnalyz ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- solr4.7中文分词器(ik-analyzer)配置
solr本身对中文分词的处理不是太好,所以中文应用很多时候都需要额外加一个中文分词器对中文进行分词处理,ik-analyzer就是其中一个不错的中文分词器. 一.版本信息 solr版本:4.7.0 需 ...
随机推荐
- javascript简单介绍总结(二)
JavaScript 函数函数是由事件驱动的或者当它被调用时执行的可重复使用的代码块.JavaScript 函数语法函数就是包裹在花括号中的代码块,前面使用了关键词 function:function ...
- C# 语言版本
(摘自:维基百科)https://en.wikipedia.org/wiki/C_Sharp_(programming_language) Versions Version Language spec ...
- 六 web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode("utf-8")将字节转化成字符串 ...
- 更新增加一个门店ID字段的值
MYSQL因为不能查询一张表时同时更新一张表,同时又会有子查询大于等于一条的情况出现. 分两种情况: 1 直接JOIN 得到一张表. 然后导出做筛选 CREATE TABLE TEST SELECT ...
- 【.Net】Socket小示例
引言 项目中用到了Socket,这里做个控制台小示例记录一下. Client 客户端的Receive用了异步方法,保持长连接,可以随时发送消息和响应服务端的消息,如下 static string Cl ...
- Four-operations: 使用node.js实现四则运算程序
一. 项目基本信息 项目成员: 陈旭钦, 郭鹏燕 项目仓库: https://github.com/Yanzery/Four-operations 二. PSP2.1表格 PSP2.1 Persona ...
- NSSet基本使用
int main(int argc, const char * argv[]) { @autoreleasepool { //创建一个集合对象 注:如果集合中写了两次或多次同一个对象 打印只能看到一个 ...
- react layout init
class Layout extends React.Component { constructor(props) { super(props); } render() { return ( < ...
- 假如数组接收到一个null,那么应该怎么循环输出。百度结果,都需要提前判断。否则出现空指针异常。。我还是想在数组中实现保存和输出null。
假如数组接收到一个null,那么应该怎么循环输出.因为foreach与obj.length都会报错.null不是对象,foreach中不能赋值? sp页面forEach一个存放对象的集合,怎么判断其中 ...
- 深入理解java虚拟机-第二章
第2章 Java内存区域与内存溢出异常 运行数据区域 1.程序计数器(Program Counter Register) 是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器. 2.J ...