python爬虫-直播吧
概述
这是一个我很喜欢的小网站,想了解这个网站先从爬虫开始,爬取直播吧所有的栏目及内容,再存入数据库。先写个简单点的,后期再不断的优化下。
准备阶段
- 直播吧网址https://www.zhibo8.cc/,打开我们看到如下界面
- 进入足球新闻-滚动新闻
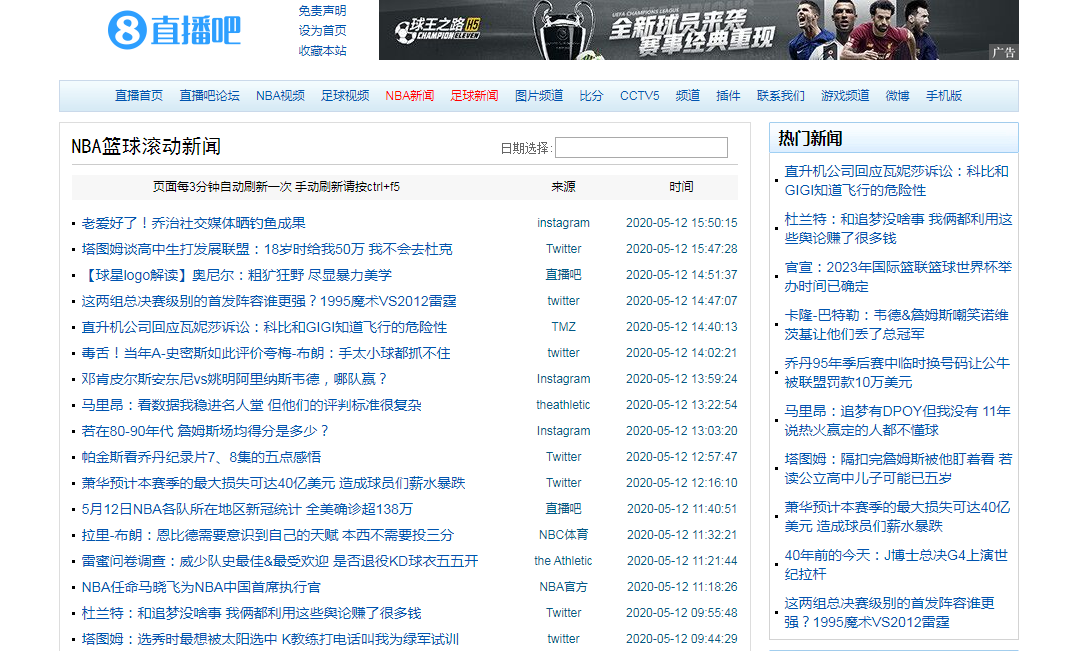
- 利用浏览器自带的编码工具按下F12查看,发现在XMR中存在页面的地址,打开之后发现
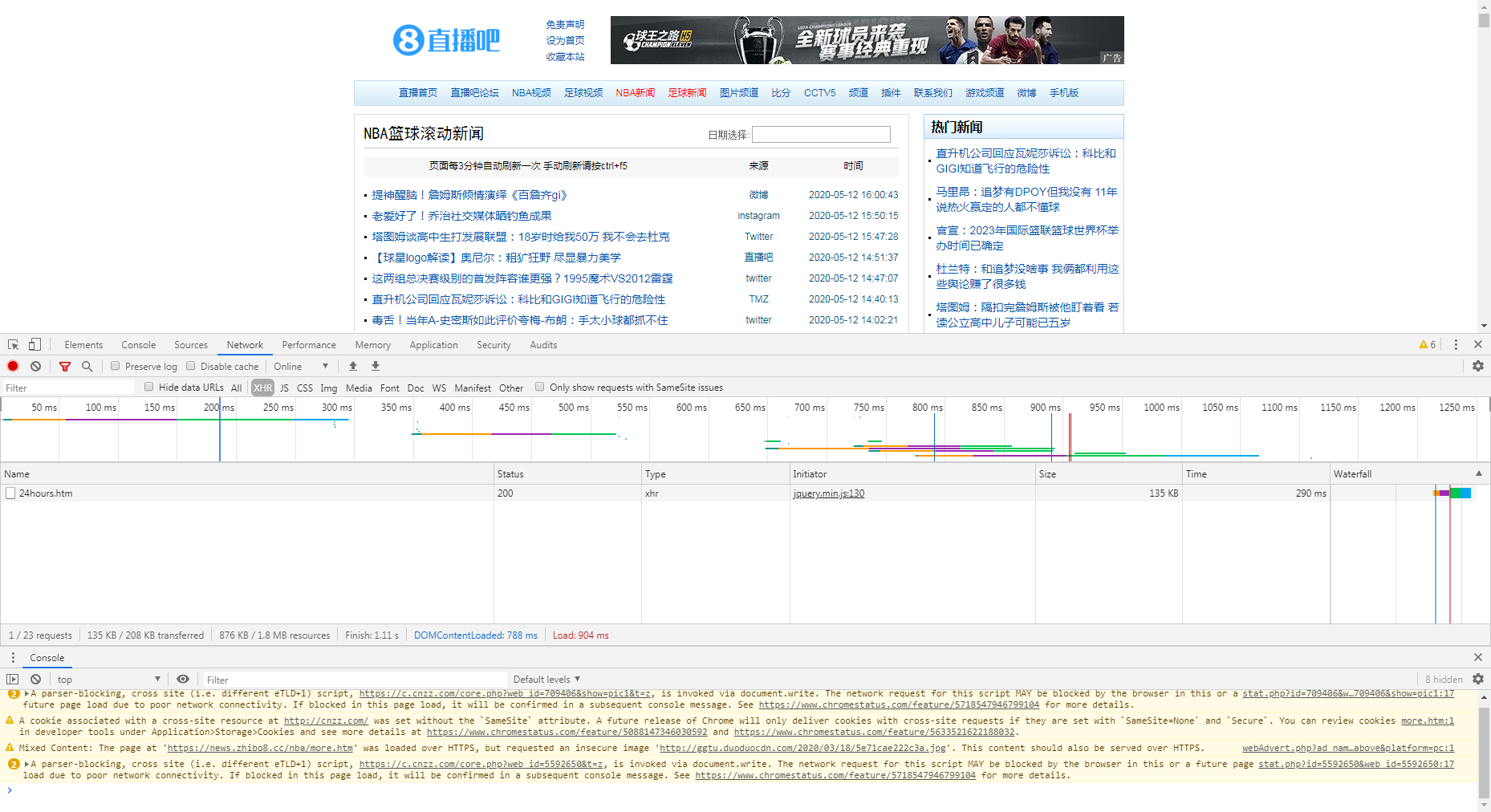
这个就是当前页面的所有内容,如果能把这里面的内容全部保存下来就完成任务了

代码
import pymysql#导入 pymysql
import requests
import json
conn = pymysql.connect(
host='192.168.88.100',
port=3306,
user='root',
password='',
database='zhibo8',
charset='utf8'
) # 建立数据库mysql连接 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)# 获取游标 默认元组类型
insert_news_sql = ' insert into news(title, url, hash, publish_time, news_type, from_name) values(%s, %s, %s, %s, %s, %s)' response = requests.get("https://m.zhibo8.cc/json/hot/24hours.htm")
news_list = json.loads(response.text).get('news')
news_data = ()
for news in news_list:
title = news.get('title')
news_type = news.get('type')
publish_time = news.get('createtime')
url = news.get('from_url')
from_name = news.get('from_name')
hash_str = hash(title)
news_data = (title, url, hash_str, publish_time, news_type, from_name)
cursor.execute(insert_news_sql, news_data) # 执行语句 conn.commit() # 提交
cursor.close() # 关闭游标
conn.close() # 关闭连接
得到了所有的数据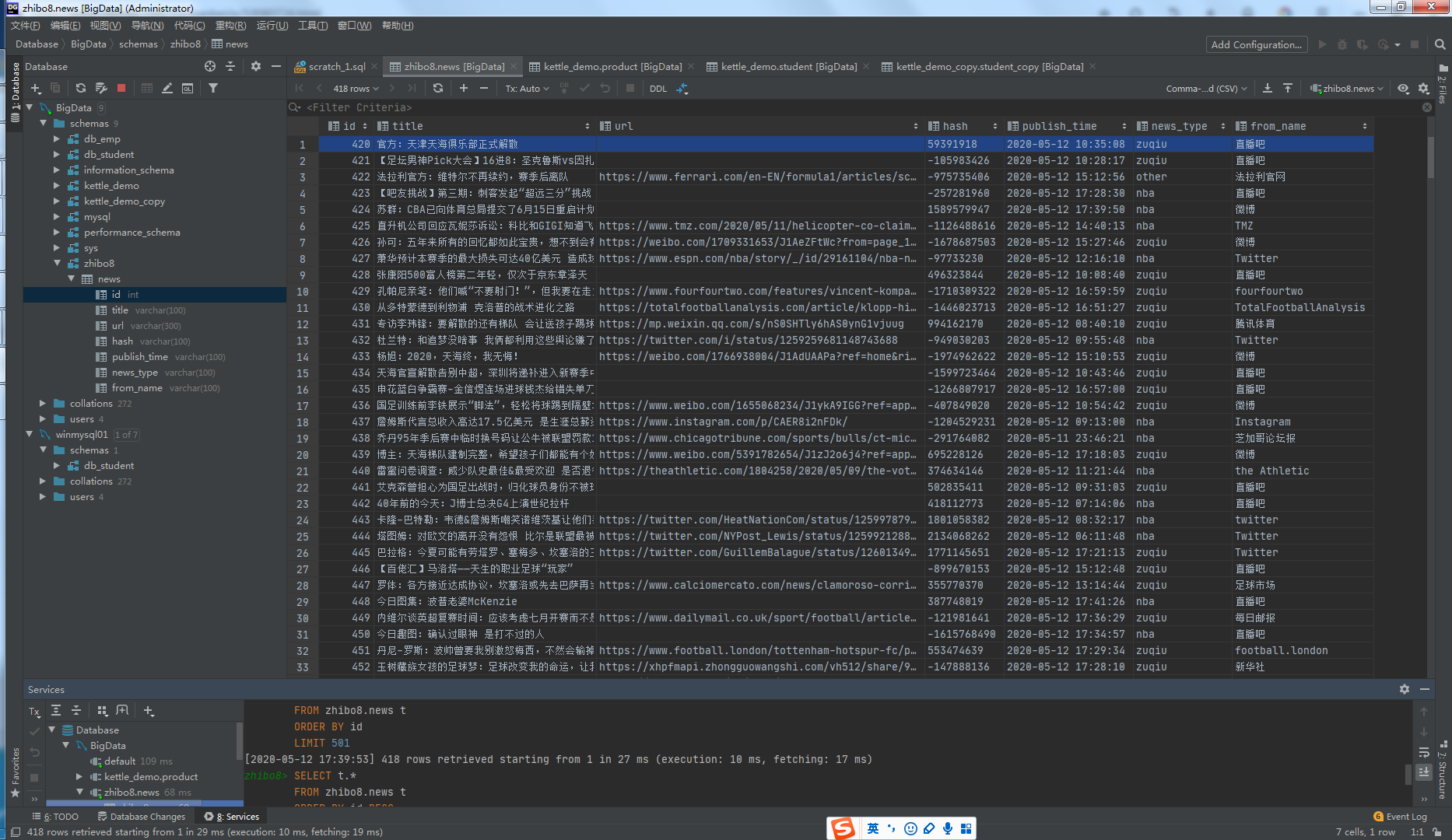
python爬虫-直播吧的更多相关文章
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- 路飞学城Python爬虫课第一章笔记
前言 原创文章,转载引用务必注明链接.水平有限,如有疏漏,欢迎指正. 之前看阮一峰的博客文章,介绍到路飞学城爬虫课程限免,看了眼内容还不错,就兴冲冲报了名,99块钱满足以下条件会返还并送书送视频. 缴 ...
- python爬虫实践
模拟登陆与文件下载 爬取http://moodle.tipdm.com上面的视频并下载 模拟登陆 由于泰迪杯网站问题,测试之后发现无法用正常的账号密码登陆,这里会使用访客账号登陆. 我们先打开泰迪杯的 ...
- python爬虫12 | 爸爸,他使坏,用动态的 Json 数据,我要怎么搞?
在前面我们玩了好多静态的 HTML 想必你应该知道怎么去爬这些数据了 但还有一些常见的动态数据 比如 商品的评论数据 实时的直播弹幕 岛国动作片的评分 等等 这些数据是会经常发生改变的 很多网站就会用 ...
- GitHub 上有哪些优秀的 Python 爬虫项目?
目录 GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目: 实用型爬虫项目: 其它有趣的Python爬虫小项目: GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目 ...
- 【收藏】收集的各种Python爬虫、暗网爬虫、豆瓣爬虫、抖音爬虫 Github1万+星
收集的各种Python爬虫.暗网爬虫.豆瓣爬虫 Github 1万+星 磁力搜索网站2020/01/07更新 https://www.cnblogs.com/cilisousuo/p/1209954 ...
- 路飞学城—Python爬虫实战密训班 第二章
路飞学城—Python爬虫实战密训班 第二章 一.Selenium基础 Selenium是一个第三方模块,可以完全模拟用户在浏览器上操作(相当于在浏览器上点点点). 1.安装 - pip instal ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
- Python爬虫之PySpider框架
概述 pyspider 是一个支持任务监控.项目管理.多种数据库,具有 WebUI 的爬虫框架,它采用 Python 语言编写,分布式架构.详细特性如下: 拥有 Web 脚本编辑界面,任务监控器,项目 ...
随机推荐
- 全网最全最细的fiddler使用教程以及工作原理
目录:导读 一.Fiddler抓包工具简介 二.Fiddler工作原理 三.Fiddler安装 四.Fiddler界面介绍 五.Fiddler菜单栏介绍 六.Fiddler工具栏介绍 七.Fiddl ...
- Springboot:整合Mybaits和Druid【监控】(十一)
MyBatis默认提供了一个数据库连接池PooledDataSource,在此我们使用阿里提供的Druid数据库连接池 项目下载:https://files.cnblogs.com/files/app ...
- java 方法的重载、重写与重构
首先我们要知道重载.重写.重构的区别 重载:指的是在同一个类中,方法名相同,但是参数数量.参数类型或者返回类型不同的方法就叫做重载. 重写: 重写分两种.第一种的是在子类继承父类的情况下,通过@Ove ...
- 移动(appium)自动化测试-爬虫的另一种手段
appium自动化测试环境搭建: 1.Python环境(推荐2.7)和jdk. 2.Adb工具的下载:自己单独下载adb.夜神模拟器自带和Android sdk 3.Apk安装介质:真机.Androi ...
- JDBC中的时间处理
MySQL中常用的时间类有: java.sql.Date, Time, Timestamp 用的比较多的是ava.sql.Date和TimeStamp: 先看表结构 CREATE TABLE `t_u ...
- token认证和理解
认知篇:https://blog.csdn.net/FYGu18/article/details/89345490 token失效篇认知:https://segmentfault.com/q/1010 ...
- linux下的.ssh文件夹路径等
1.linux下的.ssh文件夹在~下,直接cd ~/.ssh即可 2.tp经过gd类处理过的水印图片格式为png 3.前端扒下别人家的网站如果自己本地打开有出现相同的代码段则有可能是js动态添加的, ...
- Inno Setup 添加版权信息
[Setup]AppCopyright=Copyright (C) - My Company, Inc. 有以上一句,即可在右键 --> Property --> Details 里看见版 ...
- python django mysql配置
1 django默认支持sqlite,mysql, oracle,postgresql数据库. <1> sqlite django默认使用sqlite的数据库,默认自带sqlite ...
- 由JS数组去重说起
一.问题描述: var array=[1,45,3,1,4,67,45],请编写一个函数reDup来去掉其中的重复项,即 reDup(array); console.log(array);//[1,4 ...