python机器学习入门-(1)
机器学习入门项目
如果你和我一样是一个机器学习小白,这里我将会带你进行一个简单项目带你入门机器学习。开始吧!
1.项目介绍
这个项目是针对鸢尾花进行分类,数据集是含鸢尾花的三个亚属的分类信息,通过机器学习来省成一个模型,实现自动分类。这个项目属于多分类问题,监督学习。
有以下步骤:
(1)导入数据
(2)概述数据
(3)数据可视化
(4)评估算法
(5)实施预测
2.导入数据
2.1 导入类库
代码如下:
# 导入类库
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
这里我们如果导入失败,你最好检查以下是否没有安装某些库。
2.2 导入数据
我们可以在UCI机器学习仓库下载鸢尾花数据集,自己可以百度搜索下。下载后保存到我们的工作目录下,然后用Pandas导入csv数据和对数据进行统计分析,并且用Matplotlib进行数据可视化。在导入数据时候,我们对每个数据设定了名称,这个对我们后面的展示工作又帮助。代码如下:
# 导入数据
filename = 'iris.data.csv'
names = ['separ-length', 'separ-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(filename, names=names)
2.3 概述数据
我们做四个事情
(1)查看数据维度
(2)查看数据自身
(3)统计所有数据特征
(4)数据分类的分布情况
以下是相关代码:
#显示数据维度
print('数据维度: 行 %s,列 %s' % dataset.shape)
# 查看数据的前10行
print(dataset.head(10))
# 统计描述数据信息
print(dataset.describe())
# 分类分布情况
print(dataset.groupby('class').size())
2.4 数据可视化
这个是我最喜欢的环节,想想那么多无聊的数据,可以变成有规律的图片就很激动
代码如下:
# 箱线图
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
pyplot.show()
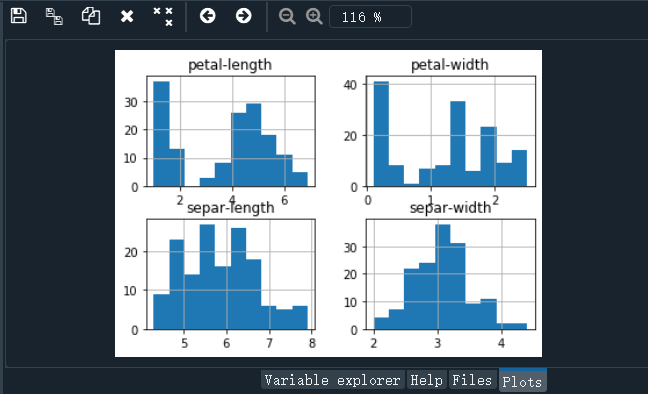
# 直方图
dataset.hist()
pyplot.show()
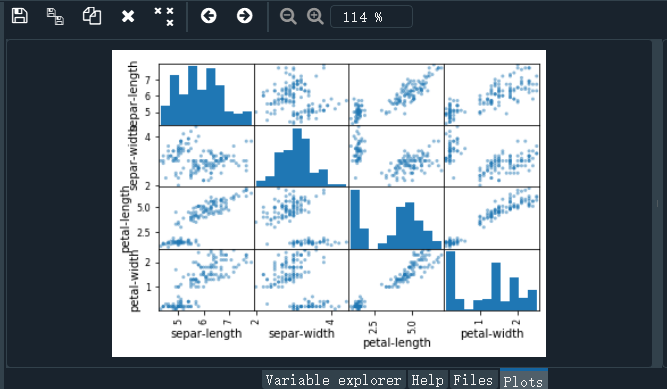
# 散点矩阵图
scatter_matrix(dataset)
pyplot.show()
结果如下:

2.5 评估算法
通过不同的算法来加你模型,并且评估它们的准确度,为了找到最合适的算法。以下几个步骤:
(1)分离出评估数据集
(2)采用10折交叉验证模型
(3)生成6个不同模型来预测新数据
(4)选择最优模型
代码如下:
# 分离数据集
array = dataset.values
X = array[:, 0:4]
Y = array[:, 4]
validation_size = 0.2
seed = 7
X_train, X_validation, Y_train, Y_validation = \
train_test_split(X, Y, test_size=validation_size, random_state=seed)
# 算法审查
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
# 评估算法
results = []
for key in models:
kfold = KFold(n_splits=10, random_state=seed)
cv_results = cross_val_score(models[key], X_train, Y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
print('%s: %f (%f)' %(key, cv_results.mean(), cv_results.std()))
# 箱线图比较算法
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()
2.6 实施预测
评估结果显示,支持向量机是准确度最高的算法。现在使用预留的评估数据集来验证这个算法模型。将对生成算法的准确的又直观的认识。
使用全部训练集的数据生成支持向量机的算法模型,并且用预留的评估数据集给出一个算法模型的报告。代码如下:
#使用评估数据集评估算法
svm = SVC()
svm.fit(X=X_train, y=Y_train)
predictions = svm.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
执行程序后,得到准确度是0.8666666666666667
还有一个结果分析报告如下:

python机器学习入门-(1)的更多相关文章
- Python & 机器学习入门指导
Getting started with Python & Machine Learning(阅者注:这是一篇关于机器学习的指导入门,作者大致描述了用Python来开始机器学习的优劣,以及如果 ...
- Python机器学习入门(1)之导学+无监督学习
Python Scikit-learn *一组简单有效的工具集 *依赖Python的NumPy,SciPy和matplotlib库 *开源 可复用 sklearn库的安装 DOS窗口中输入 pip i ...
- Python机器学习入门
# NumPy Python科学计算基础包 import numpy as np # 导入numpy库并起别名为npnumpy_array = np.array([[1,3,5],[2,4,6]])p ...
- 零起点PYTHON机器学习快速入门 PDF |网盘链接下载|
点击此处进入下载地址 提取码:2wg3 资料简介: 本书采用独创的黑箱模式,MBA案例教学机制,结合一线实战案例,介绍Sklearn人工智能模块库和常用的机器学习算法.书中配备大量图表说明,没有枯 ...
- [Python]-numpy模块-机器学习Python入门《Python机器学习手册》-01-向量、矩阵和数组
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-03-数据整理
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载文件
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [Python]-sklearn模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载数据集
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [转]MNIST机器学习入门
MNIST机器学习入门 转自:http://wiki.jikexueyuan.com/project/tensorflow-zh/tutorials/mnist_beginners.html?plg_ ...
随机推荐
- java实现小功能
// 自写逻辑,遍历所有匹配的子字符串坐标 private static void forMatchIdx(String str1, String str2) { char[] arr1 = str1 ...
- git 分支的创建与合并
首先我们需要先创建一个新的dev分支,然后切换到dev分支: $ git checkout -b dev //命令语句 Switched to a new branch 'dev' //成功执行输出语 ...
- 高数解题神器:拍照上传就出答案,这个中国学霸做的AI厉害了 | Demo
一位叫Roger的中国学霸小哥的拍照做题程序mathAI一下子火了,这个AI,堪称数学解题神器. 输入一张包含手写数学题的图片,AI就能识别出输入的数学公式,然后给出计算结果. 不仅加减乘除基本运算, ...
- coding++ :Layui-监听事件
在使用layui的form表单做验证提交的时候,如果结合vue,或者是三级联动的时候,就需要做事件监听了. 具体语法: form.on('event(过滤器值)', callback); 可以用于监听 ...
- iOS Hook
HOOK 译为"钩子"或挂钩.在 iOS 逆向中指改变程序运行流程的一种技术. iOS 中 hook 技术的几种方式 Method Swizzle 利用 OC 的 Runtime ...
- dome 模块 pyaudio 声音处理 为语音识别准备
dome 模块 pyaudio 声音处理 为语音识别准备 直接上例子 dome1 声音强度检查 import pyaudio import numpy as np class QAudio: CHUN ...
- .Net微服务实践(二):Ocelot介绍和快速开始
目录 介绍 基本原理 集成方式 快速开始 创建订单服务 创建产品服务 创建网关 运行验证 最后 上篇.Net微服务实践(一):微服务框架选型 我们对微服务框架整体做了介绍,接下来我们从网关Ocelot ...
- 使用python-crontab给linxu设置定时任务
安装pip install python-crontab #coding=utf-8 from crontab import CronTab #创建类 class Crontabi(object): ...
- E - 不爱学习的lyb HDU - 1789(贪心策略)
众所周知lyb根本不学习.但是期末到了,平时不写作业的他现在有很多作业要做. CUC的老师很严格,每个老师都会给他一个DDL(deadline). 如果lyb在DDL后交作业,老师就会扣他的分. 现在 ...
- O - Layout(差分约束 + spfa)
O - Layout(差分约束 + spfa) Like everyone else, cows like to stand close to their friends when queuing f ...