python机器学习入门-(1)
机器学习入门项目
如果你和我一样是一个机器学习小白,这里我将会带你进行一个简单项目带你入门机器学习。开始吧!
1.项目介绍
这个项目是针对鸢尾花进行分类,数据集是含鸢尾花的三个亚属的分类信息,通过机器学习来省成一个模型,实现自动分类。这个项目属于多分类问题,监督学习。
有以下步骤:
(1)导入数据
(2)概述数据
(3)数据可视化
(4)评估算法
(5)实施预测
2.导入数据
2.1 导入类库
代码如下:
# 导入类库
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
这里我们如果导入失败,你最好检查以下是否没有安装某些库。
2.2 导入数据
我们可以在UCI机器学习仓库下载鸢尾花数据集,自己可以百度搜索下。下载后保存到我们的工作目录下,然后用Pandas导入csv数据和对数据进行统计分析,并且用Matplotlib进行数据可视化。在导入数据时候,我们对每个数据设定了名称,这个对我们后面的展示工作又帮助。代码如下:
# 导入数据
filename = 'iris.data.csv'
names = ['separ-length', 'separ-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(filename, names=names)
2.3 概述数据
我们做四个事情
(1)查看数据维度
(2)查看数据自身
(3)统计所有数据特征
(4)数据分类的分布情况
以下是相关代码:
#显示数据维度
print('数据维度: 行 %s,列 %s' % dataset.shape)
# 查看数据的前10行
print(dataset.head(10))
# 统计描述数据信息
print(dataset.describe())
# 分类分布情况
print(dataset.groupby('class').size())
2.4 数据可视化
这个是我最喜欢的环节,想想那么多无聊的数据,可以变成有规律的图片就很激动
代码如下:
# 箱线图
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
pyplot.show()
# 直方图
dataset.hist()
pyplot.show()
# 散点矩阵图
scatter_matrix(dataset)
pyplot.show()
结果如下:

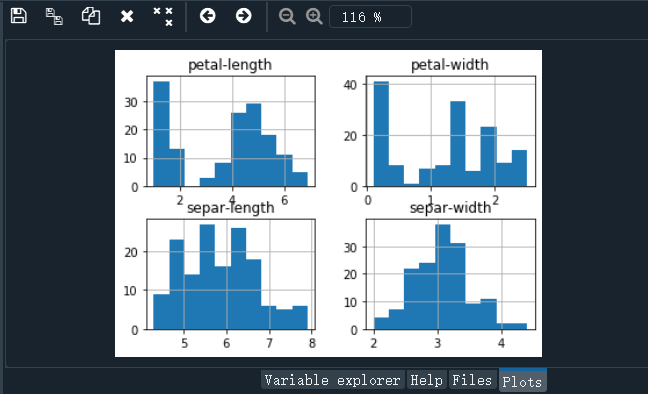
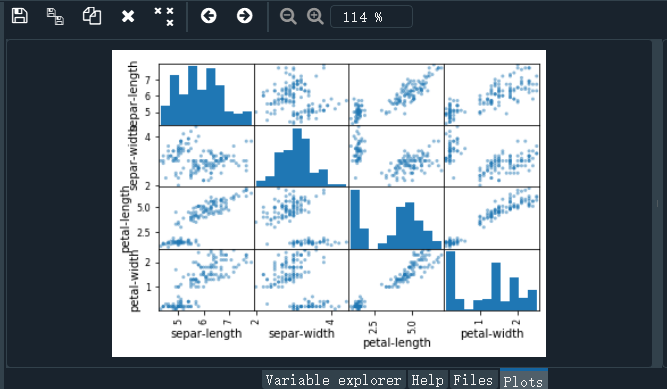
2.5 评估算法
通过不同的算法来加你模型,并且评估它们的准确度,为了找到最合适的算法。以下几个步骤:
(1)分离出评估数据集
(2)采用10折交叉验证模型
(3)生成6个不同模型来预测新数据
(4)选择最优模型
代码如下:
# 分离数据集
array = dataset.values
X = array[:, 0:4]
Y = array[:, 4]
validation_size = 0.2
seed = 7
X_train, X_validation, Y_train, Y_validation = \
train_test_split(X, Y, test_size=validation_size, random_state=seed)
# 算法审查
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
# 评估算法
results = []
for key in models:
kfold = KFold(n_splits=10, random_state=seed)
cv_results = cross_val_score(models[key], X_train, Y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
print('%s: %f (%f)' %(key, cv_results.mean(), cv_results.std()))
# 箱线图比较算法
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()
2.6 实施预测
评估结果显示,支持向量机是准确度最高的算法。现在使用预留的评估数据集来验证这个算法模型。将对生成算法的准确的又直观的认识。
使用全部训练集的数据生成支持向量机的算法模型,并且用预留的评估数据集给出一个算法模型的报告。代码如下:
#使用评估数据集评估算法
svm = SVC()
svm.fit(X=X_train, y=Y_train)
predictions = svm.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
执行程序后,得到准确度是0.8666666666666667
还有一个结果分析报告如下:

python机器学习入门-(1)的更多相关文章
- Python & 机器学习入门指导
Getting started with Python & Machine Learning(阅者注:这是一篇关于机器学习的指导入门,作者大致描述了用Python来开始机器学习的优劣,以及如果 ...
- Python机器学习入门(1)之导学+无监督学习
Python Scikit-learn *一组简单有效的工具集 *依赖Python的NumPy,SciPy和matplotlib库 *开源 可复用 sklearn库的安装 DOS窗口中输入 pip i ...
- Python机器学习入门
# NumPy Python科学计算基础包 import numpy as np # 导入numpy库并起别名为npnumpy_array = np.array([[1,3,5],[2,4,6]])p ...
- 零起点PYTHON机器学习快速入门 PDF |网盘链接下载|
点击此处进入下载地址 提取码:2wg3 资料简介: 本书采用独创的黑箱模式,MBA案例教学机制,结合一线实战案例,介绍Sklearn人工智能模块库和常用的机器学习算法.书中配备大量图表说明,没有枯 ...
- [Python]-numpy模块-机器学习Python入门《Python机器学习手册》-01-向量、矩阵和数组
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-03-数据整理
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载文件
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [Python]-sklearn模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载数据集
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [转]MNIST机器学习入门
MNIST机器学习入门 转自:http://wiki.jikexueyuan.com/project/tensorflow-zh/tutorials/mnist_beginners.html?plg_ ...
随机推荐
- MySQL优化之执行计划
前言 研究SQL性能问题,其实本质就是优化索引,而优化索引,一个非常重要的工具就是执行计划(explain),它可以模拟SQL优化器执行SQL语句,从而让开发人员知道自己编写的SQL的运行情况. 执行 ...
- java接口自动化(二) - 接口测试的用例设计
1.简介 在这篇文章里,我们来学习一下接口测试用例设计,主要是来学习一些用例设计要点.其实说白了,接口用例设计和功能用例设计差不多,照猫画虎即可.不要把它想象的多么高大上,多么的难,其实一样,以前怎么 ...
- Apache服务的主要目录和配置文件详解
Apache服务的主要目录和配置文件详解 2014-01-14 19:05:14 标签:httpd配置文件详解 apache配置文件 httpd配置文件 apache文件目录 原创作品,允许转载,转载 ...
- Jmeter接口测试之参数传递(十三)
在接口自动化测试中,经常会遇到的一种场景就是参数的场景,比如在用户列表中获取所有的用户列表,然后获取到某一个用户的ID,查看该用户的详细信息.首先在这里理清思路,它的流程是,首先获取到数据,然后在Jm ...
- 二分搜索树(Binary Search Tree)
目录 什么是二叉树? 什么是二分搜索树? 二分搜索树的基本操作 二分搜索树添加新元素 二分搜索树的遍历(包含非递归实现) 删除二分搜索树中的元素 什么是二叉树? 在实现二分搜索树之前,我们先思考一 ...
- coding++:js实现基于Base64的编码及解码
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Visio2013 专业版激活码和激活工具 亲测有效
Visio2013密钥 专业版:Visio Professional 2013 KEY C2FG9-N6J68-H8BTJ-BW3QX-RM3B3 2NYF6-QG2CY-9F8XC-GWMBW-29 ...
- Js,JQuery不同方式绑定的同一事件可以同时触发,互不干扰
比如,onclick绑定,然后jquery.on("click", function(){})绑定等
- C 部落划分
时间限制 : - MS 空间限制 : - KB SPJ 评测说明 : 1s,128m 问题描述 聪聪研究发现,荒岛野人总是过着群居的生活,但是,并不是整个荒岛上的所有野人都属于同一个部落,野人 ...
- 1025 PAT Ranking (25 分)
Programming Ability Test (PAT) is organized by the College of Computer Science and Technology of Zhe ...