Python冒泡排序算法及其优化
冒泡排序
所谓冒泡,就是将元素两两之间进行比较,谁大就往后移动,直到将最大的元素排到最后面,接着再循环一趟,从头开始进行两两比较,而上一趟已经排好的那个元素就不用进行比较了。(图中排好序的元素标记为黄色柱子)
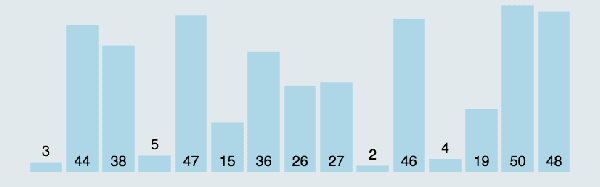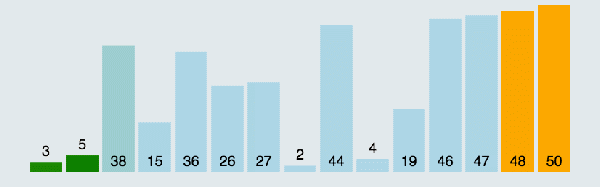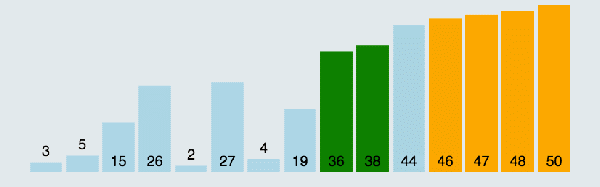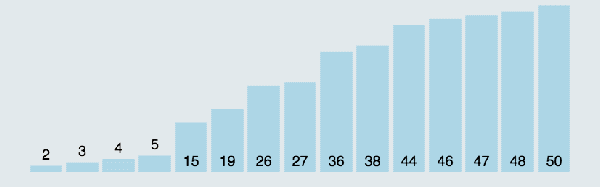
冒泡排序动图演示
上python代码:
def bubble_sort(items):
for i in range(len(items) - 1):
for j in range(len(items) - 1 - i):
if items[j] > items[j + 1]:
items[j], items[j + 1] = items[j + 1], items[j]
return items list1 = [2,1,9,11,10,8,7]
print(bubble_sort(list1))
输出结果:
[1, 2, 7, 8, 9, 10, 11]
这是冒泡排序最普通的写法,但你会发现它有一些不足之处,比如列表:[1,2,3,4,7,5,6],第一次循环将最大的数排到最后,此时列表已经都排好序了,就是不用再进行第二次、第三次...
冒泡排序优化一:
设定一个变量为False,如果元素之间交换了位置,将变量重新赋值为True,最后再判断,在一次循环结束后,变量如果还是为False,则brak退出循环,结束排序。
def bubble_sort(items):
for i in range(len(items) - 1):
flag = False
for j in range(len(items) - 1 - i):
if items[j] > items[j + 1]:
items[j], items[j + 1] = items[j + 1], items[j]
flag = True
if not flag:
break
return items
冒泡排序优化二:搅拌排序 / 鸡尾酒排序
上面这种写法还有一个问题,就是每次都是从左边到右边进行比较,这样效率不高,你要考虑当最大值和最小值分别在两端的情况。写成双向排序提高效率,即当一次从左向右的排序比较结束后,立马从右向左来一次排序比较。
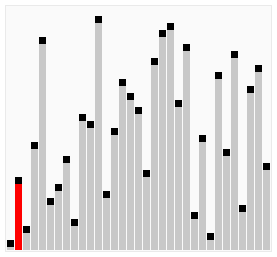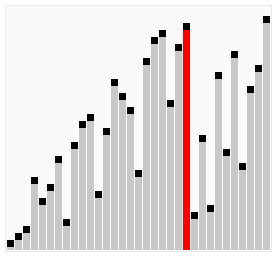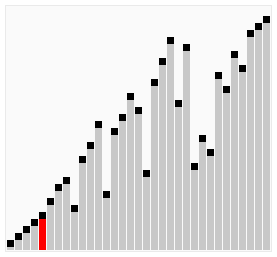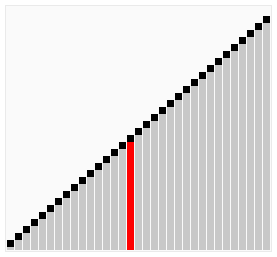
python代码:
def bubble_sort(items):
for i in range(len(items) - 1):
flag = False
for j in range(len(items) - 1 - i):
if items[j] > items[j + 1]:
items[j], items[j + 1] = items[j + 1], items[j]
flag = True
if flag:
flag = False
for j in range(len(items) - 2 - i, 0, -1):
if items[j - 1] > items[j]:
items[j], items[j - 1] = items[j - 1], items[j]
flag = True
if not flag:
break
return items
冒泡排序优化三:
最后要考虑的情况就是,如果给你的不是列表,而是对象,或者列表里面都是字符串,那么上述的代码也就没有用了,这时候你就要自定义函数了,并将其当成参数传入bubble_sort函数
python代码:
def bubble_sort(items, comp=lambda x, y: x > y):
for i in range(len(items) - 1):
flag = False
for j in range(len(items) - 1 - i):
if comp(items[j],items[j + 1]):
items[j], items[j + 1] = items[j + 1], items[j]
flag = True
if flag:
flag = False
for j in range(len(items) - 2 - i, 0, -1):
if comp(items[j - 1],items[j]):
items[j], items[j - 1] = items[j - 1], items[j]
flag = True
if not flag:
break
return items list2 = ['apple', 'watermelon', 'pitaya', 'waxberry', 'pear']
print(bubble_sort(list2,lambda s1,s2: len(s1) > len(s2))) #按照字符串长度从小到大来排序
输出结果:
['pear', 'apple', 'pitaya', 'waxberry', 'watermelon']
类似的,当有人叫你给一个类对象排序时,也可以传入lambda 自定义函数。
class Student():
"""学生""" def __init__(self, name, age):
self.name = name
self.age = age def __repr__(self):
return f'{self.name}: {self.age}' items1 = [
Student('Wang Dachui', 25),
Student('Di ren jie', 38),
Student('Zhang Sanfeng', 120),
Student('Bai yuanfang', 18)
] print(bubble_sort(items1, lambda s1, s2: s1.age > s2.age))
输出结果:按照年龄从小到大排序
[Bai yuanfang: 18, Wang Dachui: 25, Di ren jie: 38, Zhang Sanfeng: 120]
以上就是关于冒泡排序的原理,以及一些优化写法,希望会对你有所帮助。
Python冒泡排序算法及其优化的更多相关文章
- python --- 冒泡排序算法
别想太多了,这个冒泡排序就是我们脑海中想到的那个冒泡,就好像是气泡一样,较小的元素比较轻,从而要往上浮出来, 冒泡排序算法. 要对‘气泡’序列处理若干遍.所谓一遍处理,就是自底向上检查一遍这个序列,并 ...
- Python—冒泡排序算法
冒泡排序 一,介绍 冒泡排序(Bubble Sort)也是一种简单直观的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到没有再 ...
- python排序算法之一:冒泡排序(及其优化)
相信冒泡排序已经被大家所熟知,今天看了一篇文章,大致是说在面试时end在了冒泡排序上,主要原因是不能给出冒泡排序的优化. 所以,今天就写一下python的冒泡排序算法,以及给出一个相应的优化.OK,前 ...
- python算法与数据结构-冒泡排序算法(32)
一.冒泡排序介绍 冒泡排序(英语:Bubble Sort)是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.遍历数列的工作是重复地进行直到没有再需要 ...
- 冒泡排序算法的 python 实现与 C 的比较
昨天用c写了简单的冒泡排序算法之后,正好最近在学 python,也想试试用python实现一下. 总体感觉,对于这种简答的小程序,python 确实充分体现了他简洁,易懂的特点.写起来特别流畅,舒服. ...
- python开发学习-day05(正则深入、冒泡排序算法、自定义模块、常用标准模块)
s12-20160130-day05 *:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: ...
- 冒泡排序算法(C#、Java、Python、JavaScript、C、C++实现)
一.介绍 它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小.首字母从Z到A)错误就把他们交换过来. 走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排 ...
- C++/Python冒泡排序与选择排序算法详解
冒泡排序 冒泡排序算法又称交换排序算法,是从观察水中气泡变化构思而成,原理是从第一个元素开始比较相邻元素的大小,若大小顺序有误,则对调后再进行下一个元素的比较,就仿佛气泡逐渐从水底逐渐冒升到水面一样. ...
- Python 基础算法
递归 时间&空间复杂度 常见列表查找 算法排序 数据结构 递归 在调用一个函数的过程中,直接或间接地调用了函数本身这就叫做递归. 注:python在递归中没用像别的语言对递归进行优化,所以每一 ...
随机推荐
- 图-搜索-DFS-37. 解数独
2020-03-24 22:23:32 问题描述: 编写一个程序,通过已填充的空格来解决数独问题. 一个数独的解法需遵循如下规则: 数字 1-9 在每一行只能出现一次.数字 1-9 在每一列只能出现一 ...
- Contest 160
2019-10-29 16:36:24 总体感受:有一段时间没有打比赛,手居然有生疏的感觉,这次肯定是要掉分了,然后在做combination问题的时候没有敲对代码,很伤. 注意点:依然需要多练习,很 ...
- [dp+博弈]棋盘的必胜策略
链接:https://ac.nowcoder.com/acm/problem/21797来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 32768K,其他语言65536K ...
- FormDataBodyPart获取表单文件名乱码解决方法
FormDataMultiPart formData=; FormDataBodyPart filePart=; filePart.getFormDataContentDisposition().ge ...
- sql学习~pivot和unpivot用法
pivot 可以把列值转换为输出中的多个列. pivot 可以在其他剩余的列的值上执行聚合函数. unpivot 将列转换为列值 语法 SELECT <non-pivoted column&g ...
- 使用Keras进行深度学习:(一)Keras 入门
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! Keras是Python中以CNTK.Tensorflow或者Th ...
- 基于Andriod的简易计算器
这学期有安卓这门课,这里做了一个简易的计算器,实现了两位数加减乘除的基本功能,比较简单适合用来入门学习. 运行效果 预备知识 实现这个计算器之前要先了解实现计算器需要的基本组件 1.TextView ...
- iOS UITableView优化
一.Cell 复用 在可见的页面会重复绘制页面,每次刷新显示都会去创建新的 Cell,非常耗费性能. 解决方案:创建一个静态变量 reuseID,防止重复创建(提高性能),使用系统的缓存池功能. s ...
- spring boot 源码赏析之事件监听
使用spring Boot已经快1年多了,期间一直想点开springboot源码查看,但由于种种原因一直未能如愿(主要是人类的惰性...),今天就拿springboot 的监听事件祭刀. spring ...
- ubuntu查看并杀死自己之前运行的进程解决办法RuntimeError: CUDA error: out of memory
问题描述:在跑深度学习算法的时候,发现服务器上只有自己在使用GPU,但使用GPU总是会报RuntimeError: CUDA error: out of memory,这是因为自己之前运行的进程还存在 ...