python初学(三)
1.以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取,并按照排名先后顺序输出不同年份的前10位大学信息,要求对输出结果的排版进行优化。
import requests
from bs4 import BeautifulSoup class Univ:
def __init__(self, url, num):
self.url=url
self.allUniv=[]
self.num=num def get_htmltext(self):
try:
r=requests.get(self.url,timeout=30)
r.raise_for_status()
r.encoding='utf8'
return r.text
except:
return '' def fillUnivList(self,soup):
data=soup.find_all('tr')
for tr in data:
ltd=tr.find_all('td')
if len(ltd)==0:
continue
singleUniv=[]
for td in ltd:
singleUniv.append(td.string)
self.allUniv.append(singleUniv) def printUnivList(self):
print("{:^4}\t{:^20}\t{:^10}\t{:^8}\t{:^10}\t".format("排名","学校名称","省市","总分","生源质量"))
for i in range(self.num):
u=self.allUniv[i]
if u[0]:
print("{:^4}\t{:^20}\t{:^10}\t{:^8}\t{:^10}\t".format(u[0],u[1],u[2],u[3],u[4]))
else:
print("{:^4}\t{:^20}\t{:^10}\t{:^8}\t{:^10}\t".format(i+1,u[1],u[2],u[3],u[4])) def main(self):
html=self.get_htmltext()
soup=BeautifulSoup(html,'html.parser')
self.fillUnivList(soup)
self.printUnivList() if __name__ == "__main__":
url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2015_0.html"
print('')
u=Univ(url,10)
u.main()
years=["","","",""]
for year in years:
url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming"+year+".html"
print(year)
u=Univ(url,10)
u.main()
2.豆瓣图书评论数据爬取。在豆瓣图书上自行选择一本书,编写程序爬取豆瓣图书上针对该图书的短评信息,要求:
(1)对不同页码的短评信息均可以进行爬取;
(2)爬取的数据包含用户名、短评内容、评论时间和评分;
能够根据选择的排序方式进行爬取,并针对热门排序,输出前10个短评信息(包括用户名、短评内容、评论时间和评分);
(3)能够根据选择的排序方式进行爬取,并针对热门排序,输出前10个短评信息(包括用户名、短评内容、评论时间和评分);
(4)结合中文分词和词云生成,对前3页的短评内容进行文本分析,并生成一个属于自己的词云图形。
import requests
import re
import jieba
import wordcloud
from bs4 import BeautifulSoup
from fake_useragent import UserAgent class com:
def __init__(self, no,num,page):
self.no=no
self.page=page
self.num=num
self.url=None
self.header=None
self.bookdata=[]
self.txt='' def set_header(self):
ua = UserAgent()
self.header={
"User-Agent":ua.random
} def set_url(self,page):
self.url='https://book.douban.com/subject/{0}/comments/hot?p={1}'.format(str(self.no),str(page+1)) def get_html(self):
try:
r=requests.get(self.url,headers=self.header,timeout=30)
r.raise_for_status()
r.encoding='utf8'
return r.text
except:
return '' def fill_bookdata(self, soup):
commentinfo=soup.find_all('span','comment-info')
pat1=re.compile(r'allstar(\d+) rating')
pat2=re.compile(r'<span>(\d\d\d\d-\d\d-\d\d)</span>')
comments=soup.find_all('span','short')
for i in range(len(commentinfo)):
p=re.findall(pat1,str(commentinfo[i]))
t=re.findall(pat2,str(commentinfo[i]))
self.bookdata.append([commentinfo[i].a.string,comments[i].string,p,t[0]]) def printList(self, num):
for i in range(num):
u=self.bookdata[i]
try:
print("序号: {}\n用户名: {}\n评论内容: {}\n时间:{}\n评分: {}星\n".format(i+1,u[0],u[1],u[3],int(eval(u[2][0])/10)))
except:
print("序号: {}\n用户名: {}\n评论内容: {}\n".format(i+1,u[0],u[1])) def comment(self):
self.set_header()
self.set_url(0)
html=self.get_html()
soup=BeautifulSoup(html,'html.parser')
self.fill_bookdata(soup)
self.printList(self.num) def txtcloud(self):
self.set_header()
for i in range(self.page):
self.bookdata=[]
self.set_url(i)
html=self.get_html()
soup=BeautifulSoup(html,'html.parser')
self.fill_bookdata(soup)
for j in range(len(self.bookdata)):
self.txt+=self.bookdata[j][1]
w=wordcloud.WordCloud(width=1000,font_path="msyh.ttc",height=700,background_color="white")
w.generate(self.txt)
w.to_file("comment.png") def main(self):
self.comment()
self.txtcloud() if __name__ == "__main__":
com(34925415,10,10).main()
3.设 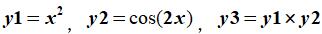 其中,完成下列操作:
其中,完成下列操作:
(1)在同一坐标系下用不同的颜色和线性绘制y1、y2和y3三条曲线;
import matplotlib.pyplot as plt
import numpy as np x=np.arange(0,360)
y1=x*x
y2=np.cos(x)
y3=y1*y2
plt.plot(x,y1,color='blue')
plt.plot(x,y2,color='red')
plt.plot(x,y3,color='green')
plt.show()
(2)在同一绘图框内以子图形式绘制y1、y2和y3三条曲线。
import matplotlib.pyplot as plt
import numpy as np x=np.arange(0,360)
y1=x*x
y2=np.cos(x)
y3=y1*y2
plt.subplot(311)
plt.plot(x,y1,color='blue')
plt.subplot(312)
plt.plot(x,y2,color='red')
plt.subplot(313)
plt.plot(x,y3,color='green')
plt.show()
4.已知 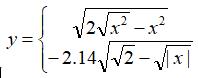 ,在-2<=x<=2区间绘制该分段函数的曲线,以及由该曲线所包围的填充图形。
,在-2<=x<=2区间绘制该分段函数的曲线,以及由该曲线所包围的填充图形。
import matplotlib.pyplot as plt
import numpy as np x=np.arange(-2,2,1e-5)
y1=np.sqrt(2*np.sqrt(np.power(x,2))-np.power(x,2))
y2=-2.14*np.sqrt(np.sqrt(2)-np.sqrt(np.abs(x)))
plt.plot(x,y1,'r',x,y2,'r')
plt.fill_between(x,y1,y2,facecolor='red')
plt.show()

python初学(三)的更多相关文章
- 初学Python(三)——字典
初学Python(三)——字典 初学Python,主要整理一些学习到的知识点,这次是字典. #-*- coding:utf-8 -*- d = {1:"name",2:" ...
- 孤荷凌寒自学python第四十五天Python初学基础基本结束的下阶段预安装准备
孤荷凌寒自学python第四十五天Python初学基础基本结束的下阶段预安装准备 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 今天本来应当继续学习Python的数据库操作,但根据过去我自 ...
- Python初学笔记之字符串
一.字符串的定义 字符串是就一堆字符,可以使用""(双引号).''(单引号)来创建. 1 one_str = "定义字符串" 字符串内容中包含引号时,可以使用转 ...
- 学习Python的三种境界
前言 王国维在<人间词话>中将读书分为了三种境界:"古今之成大事业.大学问者,必经过三种之境界:'昨夜西风凋碧树,独上高楼,望尽天涯路'.此第一境也.'衣带渐宽终不悔,为伊消得人 ...
- selenium webdriver (python) 第三版
感谢 感谢购买第二版的同学,谢谢你们对本人劳动成果的支持!也正是你们时常问我还出不出第三版了,也是你们的鼓励,让我继续学习整理本文档. 感谢乙醇前辈,第二版的文档是放在他的淘宝网站上卖的,感谢他的帮忙 ...
- Python第三天 序列 数据类型 数值 字符串 列表 元组 字典
Python第三天 序列 数据类型 数值 字符串 列表 元组 字典 数据类型数值字符串列表元组字典 序列序列:字符串.列表.元组序列的两个主要特点是索引操作符和切片操作符- 索引操作符让我 ...
- 简学Python第三章__函数式编程、递归、内置函数
#cnblogs_post_body h2 { background: linear-gradient(to bottom, #18c0ff 0%,#0c7eff 100%); color: #fff ...
- Python第三天 序列 5种数据类型 数值 字符串 列表 元组 字典 各种数据类型的的xx重写xx表达式
Python第三天 序列 5种数据类型 数值 字符串 列表 元组 字典 各种数据类型的的xx重写xx表达式 目录 Pycharm使用技巧(转载) Python第一天 安装 shell ...
- python selenium 三种等待方式详解[转]
python selenium 三种等待方式详解 引言: 当你觉得你的定位没有问题,但是却直接报了元素不可见,那你就可以考虑是不是因为程序运行太快或者页面加载太慢造成了元素不可见,那就必须要加等待 ...
- python第三十一课--递归(2.遍历某个路径下面的所有内容)
需求:遍历某个路径下面的所有内容(文件和目录,多层级的) import os #自定义函数(递归函数):遍历目录层级(多级) def printDirs(path): dirs=os.listdir( ...
随机推荐
- Scapy编写ICMP扫描脚本
使用Scapy模块编写ICMP扫描脚本: from scapy.all import * import optparse import threading import os def scan(ipt ...
- Oracle job启动与关闭
--查看job下次执行时间以及间隔时间 select * from dba_jobs where job = '774'; --启动job exec dbms_job.run(774); --停用jo ...
- 关于MySQL 建表的一些建议
由于在生产环境下,我们对MySQL数据库的操作通常是通过命令行进行操作,因此,建议建表的时候也手写MySQL语句(不建议用图形界面建表). 1.添加注释的格式 在编写MySQL语句时,我们通常会被要求 ...
- form组件源码
- hdu1026Ignatius and the Princess ,又要逃离迷宫了
题目链接:http://icpc.njust.edu.cn/Problem/Hdu/1026/ 题意就是一个迷宫,然后有些位置上有守卫,守卫有一个血量,要多花费血量的时间击败他,要求从(0,0)到(n ...
- link与@import区别整理,一个表格带你了解
网上有许多link和@import的文章,不过大多比较零散,个人觉得一个表格的话看起来能够直观的表达. 于是制作了如下表格: 关于权重这个存在着一些争议,这次碰巧看到了一篇的博客很好的解释了这个问题, ...
- Redis这些知识你知道吗?
1.什么是redis? Redis 是一个基于内存的高性能key-value数据库. 2.Redis的特点 Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库 ...
- 9.Maven的生命周期
Clean Lifecycle: 在进行真正的构建之前进行一些清理工作. Default Lifecycle :构建的核心部分,编译,测试,打包,部署等等. Site Lifecycle : 生成项目 ...
- 在操作Git Bash时出现的问题
参考博客:https://blog.csdn.net/weixin_44394753/article/details/91410463 1.问题1 $ git remote add origin gi ...
- JavaScript五子棋第二版
这是博主做的一个移动端五子棋小游戏,请使用手机体验.由于希望能有迭代开发的感觉,所以暂时只支持双人对战且无其他提示及对战界面,只有胜利提示,悔棋.对战双方显示.人机对战.集成TS(用于学习).和局 ...