教你爬取腾讯课堂、网易云课堂、mooc等所有课程信息
本文的所有代码都在GitHub上托管,想要代码的同学请点击这里
序:由于自己想要实现一个课程推荐系统,需要在各大视频网站上爬取所有视频课程,从而为后续的推荐工作提供大量数据,在此篇博客中我分别爬取了MOOC、网易云课堂、腾讯课堂、学堂在线共约15万条数据。
运行环境:
mysqlclient~=1.4.6requests~=2.22.0bs4~=0.0.1beautifulsoup4~=4.8.2
MOOC
首先进入网站,在这里我们分析他的API设计,先要找到他是从哪一个API获得相应课程的,经过分析之后我们发现是https://www.icourse163.org/web/j/courseBean.getCoursePanelListByFrontCategory.rpc这个API,其返回内容如下:

然后我们随意点击页面上的一个课程,找到其课程url的规律,打开沟通心理学这门课程,其URL是https://www.icourse163.org/course/HIT-1001515007,而沟通心理学这门课程返回的信息是:
// 在这里我只保留了我需要的一些数据
{
name: "沟通心理学",
id: 1001515007,
schoolPanel: {id: 9005, name: "哈尔滨工业大学", shortName: "HIT"}
}
我们可以发现课程的URL就是学校的简称-id,这样就可以组成课程URL,现在我们得知课程URL如何得知,那么这些课程数据需要传什么参数呢,如下:
{
categoryId: -1, // 类别id,因为我这里选的全部,所以是-1
type: 30,
orderBy: 0,
pageIndex: 1, // 第几页
pageSize: 20 // 每页多少条数据
}
到这里就新产生了一个问题,categoryId是怎么来的,我们继续看网页请求的api列表,找到这样一个APIhttps://www.icourse163.org/web/j/mocCourseCategoryBean.getCategByType.rpc,其返回结果如下:

数据结构大致如下:
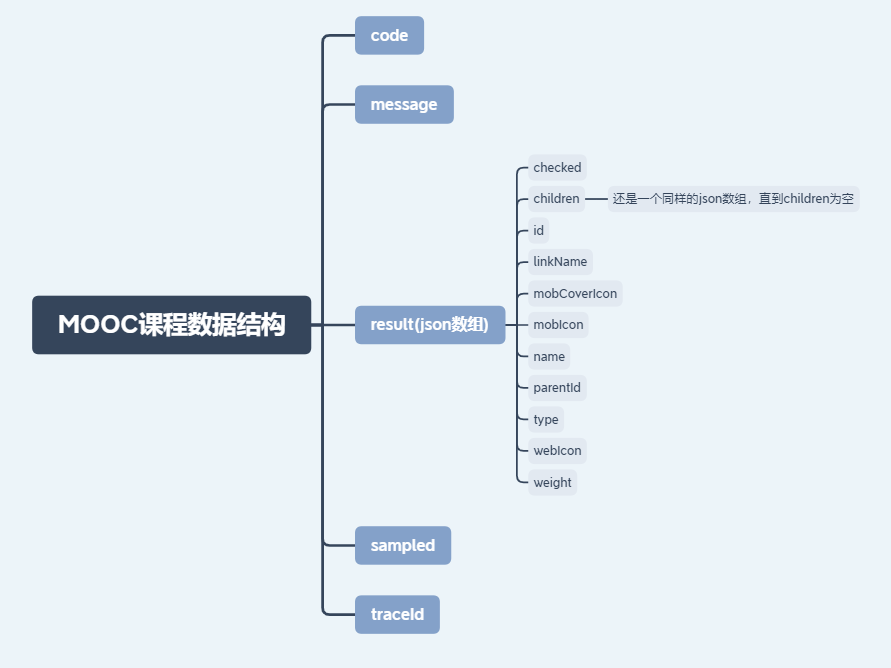
我们想要得到的课程分类特别细致的话就需要一直向下找json的children,直到children为空,算法的话就采用递归算法就可以。
到现在为止我们已经知道了如何获取类别id,如果由类别id获得课程数据,接下来我们就需要把获取到的数据存储到数据库中,我的数据库包含类别、课程名称、课程图片URL、课程URL、课程来源这四个字段,存储代码如下:
# 存储到数据库
def save_to_mysql(data, category_name):
sql = "insert into webCourses (category, name, site, imgUrl, resource) values ('{0}', '{1}', '{2}', '{3}', '{4}')".format(
category_name, data["name"],
'https://www.icourse163.org/course/' + str(data["schoolPanel"]["shortName"]) + "-" + str(data["id"]),
data["imgUrl"], "慕课")
print(sql)
execute(sql)
要注意这里的execute函数是我封装的一个函数,具体的作用就是运行sql语句,全部代码请到我的GitHub查看。
腾讯课堂
其实如果你看过了上面MOOC的获取所有课程的API设计,其他课程网站的API设计也是大致相同的,首先我们要获得类别id,然后再根据类别id去请求数据,与mooc不同的是腾讯课堂请求课程数据是通过beautifulsoup4解析html内容实现的。下面就来简单说一下:
获取课程类别的API:https://ke.qq.com/cgi-bin/get_cat_info
根据类别id获得数据的网页url: https://ke.qq.com/course/list?mt=1001&st=2001&tt=3001&page=2,这里的mt、st、tt分别是三个类别,st是mt的一个子类,tt是st的一个子类,page就是页数了。
得到的网站如下:
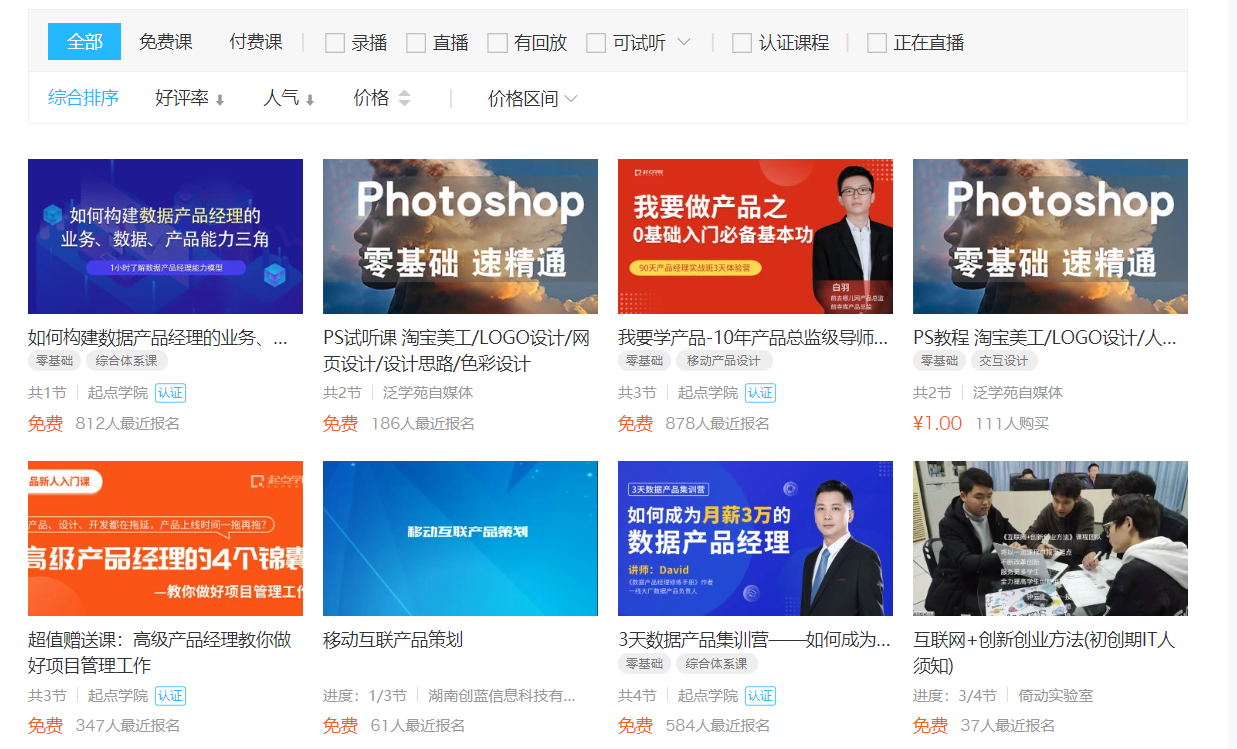
在这里我们需要的是每一个课程,其实思路很简单,按F12打开开发者工具,找到课程对应的dom块,用beautifulsoup4解析html内容,得到课程数组就可以了,代码如下:
# 获取课程数据
def get_course_data(mt, st, tt, page, category):
url = "https://ke.qq.com/course/list?mt=" + str(mt) + "&st=" + str(st) + "&tt=" + str(tt) + "&page=" + str(page)
response = requests.request("GET", url).text
bs = BeautifulSoup(response)
course_blocks = bs.find_all(name='li', attrs={"class": "course-card-item--v3 js-course-card-item"})
# print(course_blocks)
if len(course_blocks) != 0:
for i in range(len(course_blocks)):
bs = course_blocks[i]
img = bs.find(name="img", attrs={"class", "item-img"})
a = bs.find(name="a", attrs={"class", "item-img-link"})
save_to_mysql(img.attrs["alt"], a.attrs["href"], img.attrs["src"], category)
return True # 这里是返回该类别的下一页是否还有数据
else:
return False
得到数据之后再将这些数据存入到数据库中就可以了。
网易云课堂
其实网易云课堂就和MOOC的API设计非常类似了,毕竟都是网易公司的程序员写的,规范也都差不多,看懂MOOC的api设计的同学直接去我的github看代码就可以了。
学堂在线
学堂在线的API设计就比较简单,直接通过一个API就可以获得所有的数据,https://next.xuetangx.com/api/v1/lms/get_product_list/?page=1,返回的数据格式如下:
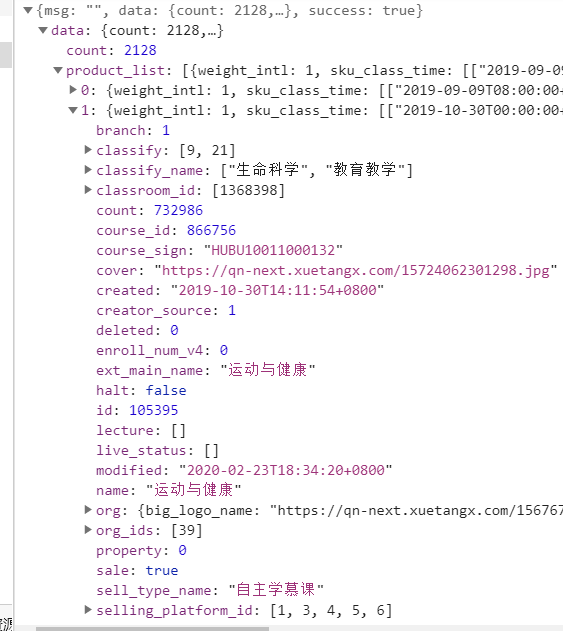
在这里一个API里面课程名称、分类、课程封面URL,课程id可以看的非常请求,下面我们就需要得到课程信息与课程url之间的关系,我们随意点开一个课程,分析他的URL,我们就可以发现,课程URL就是https://next.xuetangx.com/course/加上课程的course_sign组成的。
到这里就分析结束,存储到数据库即可。
小结
从上述的分析我们可以看出,各大课程网站的api设计都是类似的,并且他们都没有做api请求限制,所以我在爬取过程中没有遇到过被封IP的情况,也算是省了不少事。在这里把代码与思路分享给大家,希望能够给到大家一些帮助。所有代码请点击这里
教你爬取腾讯课堂、网易云课堂、mooc等所有课程信息的更多相关文章
- Python爬虫入门教程 21-100 网易云课堂课程数据抓取
写在前面 今天咱们抓取一下网易云课堂的课程数据,这个网站的数据量并不是很大,我们只需要使用requests就可以快速的抓取到这部分数据了. 你第一步要做的是打开全部课程的地址,找出爬虫规律, 地址如下 ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- Python爬取腾讯新闻首页所有新闻及评论
前言 这篇博客写的是实现的一个爬取腾讯新闻首页所有的新闻及其所有评论的爬虫.选用Python的Scrapy框架.这篇文章主要讨论使用Chrome浏览器的开发者工具获取新闻及评论的来源地址. Chrom ...
- Python实例之抓取网易云课堂搜索数据(post方式json型数据)并保存到数据库
本实例实现了抓取网易云课堂中以‘java’为关键字的搜索结果,经详细查看请求的方式为post,请求的结果为JSON数据 具体实现代码如下: import requests import json im ...
- Python3爬取人人网(校内网)个人照片及朋友照片,并一键下载到本地~~~附源代码
题记: 11月14日早晨8点,人人网发布公告,宣布人人公司将人人网社交平台业务相关资产以2000万美元的现金加4000万美元的股票对价出售予北京多牛传媒,自此,人人公司将专注于境内的二手车业务和在美国 ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- 用BeautifulSoup简单爬取BOSS直聘网岗位
用BeautifulSoup简单爬取BOSS直聘网岗位 爬取python招聘 import requests from bs4 import BeautifulSoup def fun(path): ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 使用Scrapy框架爬取腾讯新闻
昨晚没事写的爬取腾讯新闻代码,在此贴出,可以参考完善. # -*- coding: utf-8 -*- import json from scrapy import Spider from scrap ...
随机推荐
- java -封装一个类。(姓名、年龄、性别)
//定义一个类. public class Maopao1{ //创建私有的对象. private String name; private int age; private String sex; ...
- 面试官再问我如何保证 RocketMQ 不丢失消息,这回我笑了!
最近看了 @JavaGuide 发布的一篇『面试官问我如何保证Kafka不丢失消息?我哭了!』,这篇文章承接这个主题,来聊聊如何保证 RocketMQ 不丢失消息. 0x00. 消息的发送流程 一条消 ...
- 解析源码,彻底弄懂HashMap(持续更新中)
为啥突然想着看HashMap源码了? 无意间看到有人说HashMap能考验Java程序员的基本功,之前我作为面试官帮公司招人的时候偶尔问起HashMap,大部分人回答基本都会用,且多数仅停留在put, ...
- hdu1548 奇怪的电梯 dfs dijkstra bfs都可以,在此奉上dfs
题目链接:http://icpc.njust.edu.cn/Problem/Hdu/5706/ 简单的规定深度进行搜索,代码如下: #include<bits/stdc++.h> usin ...
- 毕业设计——基于ZigBee的智能窗户控制系统的设计与实现
题目:基于物联网的智能窗户控制系统的设计与实现 应用场景:突降大雨,家里没有关窗而进水:家中燃气泄漏,不能及时通风,威胁人身安全,存在火灾的隐患:家中窗户没关,让坏人有机可乘.长时间呆在人多.封闭的空 ...
- CF1326C Permutation Partitions 题解,
原题链接 简要题意: 给定一个 \(1\) ~ \(n\) 的置换,将数组分为 \(k\) 个区间,使得每个区间的最大值之和最大.求这个值,和分区的方案数. 关键在于 \(1\) ~ \(n\) 的置 ...
- [模拟] Codefroces 1175B Catch Overflow!
题目:http://codeforces.com/contest/1175/problem/B B. Catch Overflow! time limit per test 1 second memo ...
- Manjaro更新后 搜狗拼音输入法突然无法正常使用
之前Manjaro已经用了很久了,很多该配置的都已经配置好了,但是搜狗拼音在系统更新后突然无法使用 1检查 如下依赖 2.检查配置文件 3.发现一切配置没问题,此时输入 sogou-qimpanel ...
- 算法学习 八皇后问题的递归实现 java版 回溯思想
1.问题描述 八皇后问题是一个以国际象棋为背景的问题:如何能够在 8×8 的国际象棋棋盘上放置八个皇后,使得任何一个皇后都无法直接吃掉其他的皇后?为了达到此目的,任两个皇后都不能处于同一条横行.纵行或 ...
- Building Applications with Force.com and VisualForce (DEV401) (二十):Visualforce Pages: Visualforce Componets (Tags)
Dev401-021:Visualforce Pages: Visualforce Componets (Tags) Module Agenda1.Tag Basics2.Tag Bindings T ...