HashCode()与equals()深入理解
1、hashCode()和equals()方法都是Object类提供的方法,
hashCode()返回该对象的哈希码值,该值通常是一个由该对象的内部地址转换而来的int型整数,
Object的equals()方法等价于==,也就是判断两个引用的对象是否是同一对象,所谓同一对象就是指内存中同一块存储单元
2、要判断两个对象逻辑相等就要覆盖equals()方法,当覆盖equals()方法时建议覆盖hashCode()方法,
官方hashCode的常规协定是如果根据 equals(Object) 方法,两个对象是相等的,那么在两个对象中的每个对象上调用 hashCode 方法都必须生成相同的整数结果。
3、在一些散列存储结构的集合中(Hashset,HashMap...)判断两个对象是否相等是先判断两个对象的hashCode是否相等,再判断两个对象用equals()运算是否相等
4、hashCode是为了提高在散列结构存储中查找的效率,在线性表中没有作用。
5、若两个对象equals返回true,则hashCode有必要也返回相同的int数。
6、同一对象在执行期间若已经存储在集合中,则不能修改影响hashCode值的相关信息,否则会导致内存泄露问题。
一、equals()方法
equals是Object类提供的方法之一,众所周知,每一个java类都继承自Object类,所以说每一个对象都有equals这个方法。而我们在用这个方法时却一般都重写这个方法,why?
Object类中equals()方法的源代码:
public boolean equals(Object obj) {
return (this == obj);
}
从这个方法中可以看出,只有当一个实例等于它本身的时候,equals()才会返回true值。通俗地说,此时比较的是两个引用是否指向内存中的同一个对象,也可以称做是否实例相等。而我们在使用equals()来比较两个指向值对象的引用的时候,往往希望知道它们逻辑上是否相等,而不是它们是否指向同一个对象——这就是我们通常重写这个方法的原因。
重写equals()方法,必须要遵守通用约定。来自java.lang.Object的规范,equals方法实现了等价关系,以下是要求遵循的5点:
1.自反性:对于任意的引用值x,x.equals(x)一定为true。
2.对称性:对于任意的引用值x 和 y,当x.equals(y)返回true时,y.equals(x)也一定返回true。
3.传递性:对于任意的引用值x、y和z,如果x.equals(y)返回true,并且y.equals(z)也返回true,那么x.equals(z)也一定返回true。
4. 一致性:对于任意的引用值x 和y,如果用于equals比较的对象信息没有被修改,多次调用x.equals(y)要么一致地返回true,要么一致地返回false。
5.非空性:对于任意的非空引用值x,x.equals(null)一定返回false。
二、hashCode()方法
hashcode()这个方法也是从object类中继承过来的,在object类中定义如下:
public native int hashCode();
hashCode()返回该对象的哈希码值,该值通常是一个由该对象的内部地址转换而来的整数,它的实现主要是为了提高哈希表(例如java.util.Hashtable提供的哈希表)的性能。
官方文档给出的hashCode()的常规协定:
1、在 Java 应用程序执行期间,在同一对象上多次调用 hashCode 方法时,必须一致地返回相同的整数,前提是对象上 equals 比较中所用的信息没有被修改。从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。
2、如果根据 equals(Object) 方法,两个对象是相等的,那么在两个对象中的每个对象上调用 hashCode 方法都必须生成相同的整数结果。
3、以下情况不 是必需的:如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么在两个对象中的任一对象上调用 hashCode 方法必定会生成不同的整数结果。但是,程序员应该知道,为不相等的对象生成不同整数结果可以提高哈希表的性能。
4、实际上,由 Object 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,但是 JavaTM 编程语言不需要这种实现技巧。)
总结:
hashCode()的返回值和equals()的关系如下:
如果x.equals(y)返回“true”,那么x和y的hashCode()必须相等。
如果x.equals(y)返回“false”,那么x和y的hashCode()有可能相等,也有可能不等。
重写hashCode时注意事项
(1)返回的hash值是int型的,防止溢出。
(2)不同的对象返回的hash值应该尽量不同。(为了hashMap等集合的效率问题)
(3)《Java编程思想》中提到一种情况
“设计hashCode()时最重要的因素就是:无论何时,对同一个对象调用hashCode()都应该产生同样的值。如果在讲一个对象用put()添加进HashMap时产生一个hashCdoe值,而用get()取出时却产生了另一个hashCode值,那么就无法获取该对象了。所以如果你的hashCode方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,hashCode()方法就会生成一个不同的散列码”。
下面来看一张对象放入散列集合的流程图:
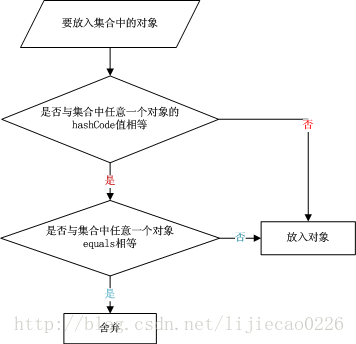
在存储一个对象时,先进行hashCode值的比较,然后进行equals的比较。来认识一下具体hashCode和equals在代码中是如何调用的。
测试一:覆盖equals(Object obj)但不覆盖hashCode(),导致数据不唯一性
public class HashCodeTest {
public static void main(String[] args) {
Collection set = new HashSet();
Point p1 = new Point(1, 1);
Point p2 = new Point(1, 1);
System.out.println(p1.equals(p2));
set.add(p1); // (1)
set.add(p2); // (2)
set.add(p1); // (3)
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object object = iterator.next();
System.out.println(object);
}
}
}
class Point {
private int x;
private int y;
public Point(int x, int y) {
super();
this.x = x;
this.y = y;
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
Point other = (Point) obj;
if (x != other.x) {
return false;
}
if (y != other.y) {
return false;
}
return true;
}
@Override
public String toString() {
return "x:" + x + ",y:" + y;
}
}
//结果:
true
x:1,y:1
x:1,y:1
原因分析:
(1)当执行set.add(p1)时集合为空,直接存入集合;
(2)当执行set.add(p2)时首先判断该对象(p2)的hashCode值所在的存储区域是否有相同的hashCode,因为没有覆盖hashCode方法,所以jdk使用默认Object的hashCode方法,返回内存地址转换后的整数,因为不同对象的地址值不同,所以这里不存在与p2相同hashCode值的对象,因此jdk默认不同hashCode值,equals一定返回false,所以直接存入集合。
(3)当执行set.add(p1)时,时,因为p1已经存入集合,同一对象返回的hashCode值是一样的,继续判断equals是否返回true,因为是同一对象所以返回true。此时jdk认为该对象已经存在于集合中,所以舍弃。
测试二:覆盖hashCode方法,但不覆盖equals方法,仍然会导致数据的不唯一性
public class HashCodeTest {
public static void main(String[] args) {
Collection set = new HashSet();
Point p1 = new Point(1, 1);
Point p2 = new Point(1, 1);
System.out.println(p1.equals(p2));
set.add(p1); // (1)
set.add(p2); // (2)
set.add(p1); // (3)
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object object = iterator.next();
System.out.println(object);
}
}
}
class Point {
private int x;
private int y;
public Point(int x, int y) {
super();
this.x = x;
this.y = y;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
@Override
public String toString() {
return "x:" + x + ",y:" + y;
}
}
//结果
false
x:1,y:1
x:1,y:1
原因分析:
(1)当执行set.add(p1)时(1),集合为空,直接存入集合;
(2)当执行set.add(p2)时(2),首先判断该对象(p2)的hashCode值所在的存储区域是否有相同的hashCode,这里覆盖了hashCode方法,p1和p2的hashCode相等,所以继续判断equals是否相等,因为这里没有覆盖equals,默认使用'=='来判断,所以这里equals返回false,jdk认为是不同的对象,所以将p2存入集合。
(3)当执行set.add(p1)时(3),时,因为p1已经存入集合,同一对象返回的hashCode值是一样的,并且equals返回true。此时jdk认为该对象已经存在于集合中,所以舍弃。
综合上述两个测试,要想保证元素的唯一性,必须同时覆盖hashCode和equals才行。
(注意:在HashSet中插入同一个元素(hashCode和equals均相等)时,会被舍弃,而在HashMap中插入同一个Key(Value 不同)时,原来的元素会被覆盖。)
测试三:在内存泄露问题
public class HashCodeTest {
public static void main(String[] args) {
Collection set = new HashSet();
Point p1 = new Point(1, 1);
Point p2 = new Point(1, 2);
set.add(p1);
set.add(p2);
p2.setX(10);
p2.setY(10);
set.remove(p2);
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object object = iterator.next();
System.out.println(object);
}
}
}
class Point {
private int x;
private int y;
public Point(int x, int y) {
super();
this.x = x;
this.y = y;
}
public int getX() {
return x;
}
public void setX(int x) {
this.x = x;
}
public int getY() {
return y;
}
public void setY(int y) {
this.y = y;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
Point other = (Point) obj;
if (x != other.x) {
return false;
}
if (y != other.y) {
return false;
}
return true;
}
@Override
public String toString() {
return "x:" + x + ",y:" + y;
}
}
x:1,y:1
x:10,y:10
原因分析:
假设p1的hashCode为1,p2的hashCode为2,在存储时p1被分配在1号桶中,p2被分配在2号筒中。这时修改了p2中与计算hashCode有关的信息(x和y),当调用remove(Object obj)时,首先会查找该hashCode值得对象是否在集合中。假设修改后的hashCode值为10(仍存在2号桶中),这时查找结果空,jdk认为该对象不在集合中,所以不会进行删除操作。然而用户以为该对象已经被删除,导致该对象长时间不能被释放,造成内存泄露。解决该问题的办法是不要在执行期间修改与hashCode值有关的对象信息,如果非要修改,则必须先从集合中删除,更新信息后再加入集合中。
测试4:
public class RectObject {
public int x;
public int y;
public RectObject(int x,int y){
this.x = x;
this.y = y;
}
@Override
public int hashCode(){
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
@Override
public boolean equals(Object obj){
return false;
}
}
public static void main(String[] args){
HashSet<RectObject> set = new HashSet<RectObject>();
RectObject r1 = new RectObject(3,3);
RectObject r2 = new RectObject(5,5);
RectObject r3 = new RectObject(3,3);
set.add(r1);
set.add(r2);
set.add(r3);
set.add(r1);
System.out.println("size:"+set.size());
}
运行结果:size:3
原因分析:
首先r1和r2的对象比较hashCode,不相等,所以r2放进set中,
再来看一下r3,比较r1和r3的hashCode方法,是相等的,然后比较他们两的equals方法,因为equals方法始终返回false,所以r1和r3也是不相等的,r3和r2就不用说了,他们两的hashCode是不相等的,所以r3放进set中,
再看r4,比较r1和r4发现hashCode是相等的,在比较equals方法,因为equals返回false,所以r1和r4不相等,同一r2和r4也是不相等的,r3和r4也是不相等的,所以r4可以放到set集合中,那么结果应该是size:4,那为什么会是3呢?
这时候我们就需要查看HashSet的源码了,下面是HashSet中的add方法的源码:
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
这里我们可以看到其实HashSet是基于HashMap实现的,hashset存放的元素作为hashMap里面唯一的key变量,value部分用一个PRESENT对象来存储。
我们在点击HashMap的put方法,源码如下:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果存储元素的table为空,则进行必要字段的初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 获取长度(16)
// 如果根据hash值获取的结点为空,则新建一个结点
//(先查找对应的索引位置有没有元素)
if ((p = tab[i = (n - 1) & hash]) == null) // 此处 & 代替了 % (除法散列法进行散列)
tab[i] = newNode(hash, key, value, null);
// 这里的p结点是根据hash值算出来对应在数组中的元素
else {
Node<K,V> e; K k;
// 如果新插入的结点和table中p结点的hash值,key值相同的话
//这里判断hashCode是否相等,再判断两个对象是否相等或者两个对象的equals方法,因为r1和r4是同一对象,
//所以其实这里是r4覆盖了r1
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果是红黑树结点的话,进行红黑树插入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
// 代表这个单链表只有一个头部结点,则直接新建一个结点即可
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 链表长度大于8时,将链表转红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// 及时更新p
p = e;
}
}
// 如果存在这个映射就覆盖
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 判断是否允许覆盖,并且value是否为空
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 回调以允许LinkedHashMap后置操作
return oldValue;
}
}
++modCount; // 更改操作次数
if (++size > threshold) // 大于临界值
// 将数组大小设置为原来的2倍,并将原先的数组中的元素放到新数组中
// 因为有链表,红黑树之类,因此还要调整他们
resize();
// 回调以允许LinkedHashMap后置操作
afterNodeInsertion(evict);
return null;
}
参考:
https://blog.csdn.net/u012088516/article/details/86495512
https://blog.csdn.net/wonad12/article/details/78958411
https://blog.csdn.net/AJ1101/article/details/79413939
HashCode()与equals()深入理解的更多相关文章
- 对hashcode、equals的理解
1.首先hashcode和equals都是java每个对象都存在的方法,因为他们两是Object的方法. 2.hashcode方法默认返回的是该对象内存地址的哈希码,然而你会发现,Object类中没有 ...
- 对hashmap与hashcode()、equals()的理解
1.equals方法没被重写的时候 比较的只是对象的地址 重写之后 比较的才是对象里的内容 2.重写equals的时候 务必需要重写hashcode 不然在用到容器的时候 会出现问题 因为容器会 ...
- HashCode和equals的理解
-------------------------------------------------------------------------------------------第一篇博客---- ...
- java中hashcode()和equals()的详解
今天下午研究了半天hashcode()和equals()方法,终于有了一点点的明白,写下来与大家分享(zhaoxudong 2008.10.23晚21.36). 1. 首先equals()和hashc ...
- Java hashCode() 和 equals()的若干问题
原文:http://www.cnblogs.com/skywang12345/p/3324958.html 本章的内容主要解决下面几个问题: 1 equals() 的作用是什么? 2 equals() ...
- Java hashCode() 和 equals()的若干问题解答
本章的内容主要解决下面几个问题: 1 equals() 的作用是什么? 2 equals() 与 == 的区别是什么? 3 hashCode() 的作用是什么? 4 hashCode() 和 equa ...
- Java中hashcode,equals和==
hashcode方法返回该对象的哈希码值. hashCode()方法可以用来来提高Map里面的搜索效率的,Map会根据不同的hashCode()来放在不同的位置,Map在搜索一个对象的时候先通过has ...
- java中hashcode和equals的区别和联系
HashSet和HashMap一直都是JDK中最常用的两个类,HashSet要求不能存储相同的对象,HashMap要求不能存储相同的键. 那么Java运行时环境是如何判断HashSet中相同对象.Ha ...
- Java 中正确使用 hashCode 和 equals 方法
在这篇文章中,我将告诉大家我对hashCode和equals方法的理解.我将讨论他们的默认实现,以及如何正确的重写他们.我也将使用Apache Commons提供的工具包做一个实现. 目录: hash ...
随机推荐
- (27)ASP.NET Core .NET标准REST库Refit
1.简介 Refit是一个受到Square的Retrofit库(Java)启发的自动类型安全REST库.通过HttpClient网络请求(POST,GET,PUT,DELETE等封装)把REST AP ...
- shell编程中星号(asterisk "*")的坑
今天分享一个有关shell编程中由通配符引起的问题. 1. 问题代码 cat test.logs 4567890 * ##*************************************## ...
- web前端问题整理
1.常用那几种浏览器测试?有哪些内核(Layout Engine)? (Q1)浏览器:IE,Chrome,FireFox,Safari,Opera (Q2)内核:Trident,Gecko,Prest ...
- PTP从时钟授时模块应用及介绍
PTP从时钟授时模块应用及介绍 随着网络技术的不断进步和发展,NTP网络时间协议已经满不了一些精密设备和仪器的精度要求,这时就需要精度更高的PTP协议,PTP协议是一种应用于分布式测量和控制系统中的精 ...
- OpenCV中Mat的基本用法:创建、复制
OpenCV中Mat的基本用法:创建.复制 一.Mat类的创建: 1.方法一: 通过读入一张图像,直接将其转换成Mat对象. Mat image = imread("test.jpg&quo ...
- JavaScript(js)函数声明与函数表达式的区别
在JavaScript中,函数是经常用到的,在实际开发的时候,我想很多人都没有太在意函数的声明与函数表达式的区别,但是呢,这种细节的东西对于学好js是非常重要的. 函数声明与函数表达式用代码写出来是这 ...
- vue的computed计算属性
computed可定义一些函数,这些函数叫做[计算属性] 只要data里面的数据发生变化computed会同步改变 引用[计算属性]时不要加 () ,应当普通属性使用 例:console.log(t ...
- guava限流器RateLimiter原理及源码分析
前言 RateLimiter是基于令牌桶算法实现的一个多线程限流器,它可以将请求均匀的进行处理,当然他并不是一个分布式限流器,只是对单机进行限流.它可以应用在定时拉取接口数据, 预防单机过大流量使用. ...
- eslint常用三种校验语句
1.关闭对整段代码的校验 /* eslint-disable */ code /* eslint-enable */ 2.关闭当前行代码的校验 line code // eslint-disable- ...
- emWin模拟器Visual Studio开发时无法printf打印的问题
1.emWin模拟器 为了方便用户学习evWin框架,Segger设计了一个PC仿真的工具,可以测试绝大部分GUI的功能,除了方便使用者学习之外,还可以加速项目开发进度.毕竟在PC上用Visual S ...