【面试QA】Attention
Attention机制的原理
- 关键的三个变量 Query, Key, Value,计算 Attention 的过程即使用一个 Query,对所有的 Key 计算相似度,然后根据相似度对 Value 进行加权求和
Attention机制的类别
Hard/Soft Attention:Soft Attention是利用注意力分数加权和的方法得到注意力表征,即传统的 Attention 计算。而 Hard Attention 则是一个随机过程,将将注意力分数当作采样概率,对 Value 进行采样,采样过程是无法求导的(即 Soft/Hard 的区别)
Local/Globel Attention:区别在于 Local Attention 需要定义一个窗口,最后只加权窗口之内的词信息,而 Globel Attention 则是关注整个上下文的信息。
一维匹配/二维匹配:一维匹配模型指的是 Query 直接表征为一个一维向量,注意力分数即为 Query 对 Key 中每个词的注意力分数,这个注意力关系是一个一维匹配的关系;而二维匹配模型则是可以看作有多个 Query 与多个 Key 计算相关分数,是一个 N2N 的二维匹配关系。
双向注意力
- 双向注意力模型即在求得二维匹配矩阵之后,在两个不同方向上的 Softmax 归一化即为两个不同方向上的注意力分数,再利用注意力分数对相应的注意力对象加权即可,得到 context-to-query attention 表征以及 query-to-context atteniton 表征,再通过拼接的方式将其整合为上下文的 query-aware 表征。
Self-Attention 与 Soft-Attention 的区别
- Soft-Attention 中的 Key 和 Query 为不同值,而 Self-Attention 中的 Key, Query 和 Value 为同一个值经过不同的线性变换的
Transformer

Multi-Head Attention 机制
- 多个 Self-Attention 并行堆叠在一起实现多头注意力模型。
- 并行堆叠的意义:通过初始化不同的线性映射矩阵,使得不同的 Self-Attention 能够聚焦在不同的位置,保证最后输出的多个表征具有多方面的自注意力信息。最后将多个 Self-Attention 的输出在词向量维度上拼接,通过一个线性映射将其压缩到原来的词表征维度。
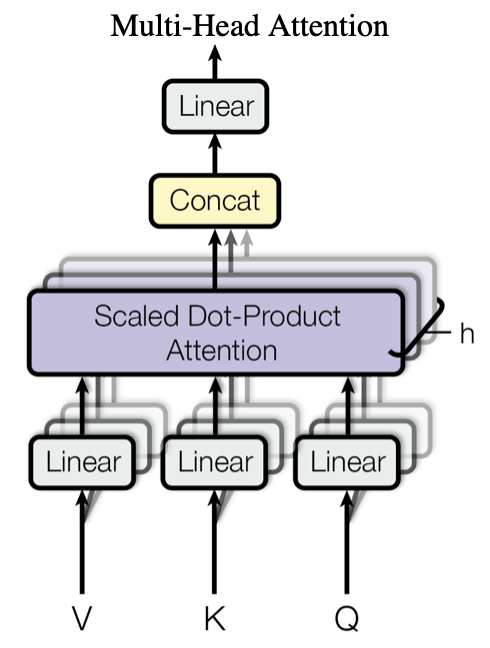
Self-Attention机制
- 输入的 Key、Query 和 Value 向量均为输入序列的线性映射,计算 Key 和 Query 的注意力分数再对 Value 进行注意力加权,实际上是一个对序列自身的注意力加权编码机制
\]

Position-wise Feed-Forward Layer
- Feed-Forward Layer 的作用就是将 Multi-Head Attention 输出的向量再投影到一个更大的空间,最后再投影回token向量原来的空间,便于在高维空间中提取需要的信息,激活函数使用ReLU
使用残差连接的部分
- Multi-Head Attention 前后和 Fead Forward 前后
- 残差连接之后还需要进行 Layer Normalization 进行归一化
Transformer Decoder 与 Encoder 之间的区别
- Transformer Decoder Block的结构与Encode Block略有不同,就是在Multi-Head Attention 之前额外添加了一个Masked Multi-Head Attention。
- Masked Attention,就是为了在解码过程中防止句子看到当前解码对象之后的序列,仅须对二维匹配注意力分数矩阵乘上一个下三角矩阵 \(M\) 即可,表明每一个时刻仅能看到过去时刻的解码输出
\]
位置编码
- 在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
- 这样的编码方式包含了相对位置信息,位置为pos+k的词可以由位置为pos和k的词来表示,且可以证明:间隔为k的任意两个位置编码的欧式空间距离是恒等的,只与k有关
PE_{2i}(p)=sin(p/10000^{2i/d_{pos}}) \\
PE_{2i+1}(p)=cos(p/10000^{2i/d_{pos}})
\end{cases}\]
- 相对位置的表示主要与下面的正余弦公式有关
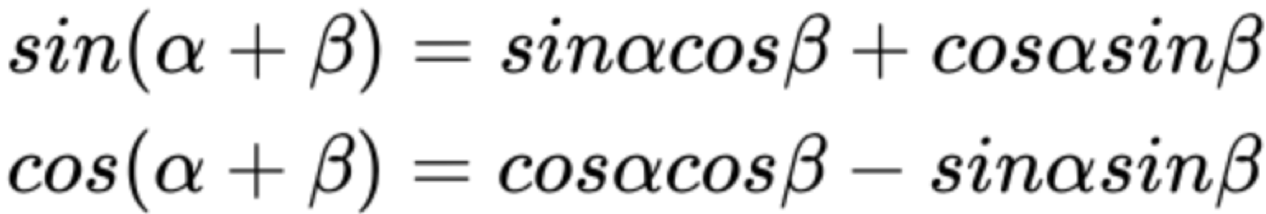
- 因此,可以将 \(PE_{pos}\) 和 \(PE_{pos+k}\) 的关系表示如下:
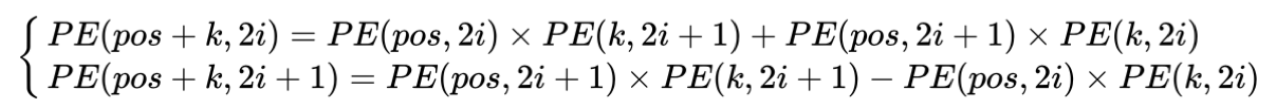
【面试QA】Attention的更多相关文章
- 如何面试QA(面试官角度)
面试是一对一 或者多对一的沟通,是和候选人 互相交换信息.平等的. 面试的目标是选择和雇佣最适合的人选.是为了完成组织目标.协助人力判断候选人是否合适空缺职位. 面试类型: (1)预判面试(查看简历后 ...
- 【NLP面试QA】预训练模型
目录 自回归语言模型与自编码语言 Bert Bert 中的预训练任务 Masked Language Model Next Sentence Prediction Bert 的 Embedding B ...
- 【NLP面试QA】基本策略
目录 防止过拟合的方法 什么是梯度消失和梯度爆炸?如何解决? 在深度学习中,网络层数增多会伴随哪些问题,怎么解决? 关于模型参数 模型参数初始化的方法 模型参数初始化为 0.过大.过小会怎样? 为什么 ...
- 【NLP面试QA】激活函数与损失函数
目录 Sigmoid 函数的优缺点是什么 ReLU的优缺点 什么是交叉熵 为什么分类问题的损失函数为交叉熵而不能是 MSE? 多分类问题中,使用 sigmoid 和 softmax 作为最后一层激活函 ...
- 机器阅读理解(看各类QA模型与花式Attention)
目录 简介 经典模型概述 Model 1: Attentive Reader and Impatient Reader Model 2: Attentive Sum Reader Model 3: S ...
- 机器阅读理解(看各类QA模型与花式Attention)(转载)
目录 简介 经典模型概述 Model 1: Attentive Reader and Impatient Reader Attentive Reader Impatient Reader Model ...
- PHP面试题目搜集
搜集这些题目是想在学习PHP方面知识有更感性的认识,单纯看书的话会很容易看后就忘记. 曾经看过数据结构.设计模式.HTTP等方面的书籍,但是基本看完后就是看完了,没有然后了,随着时间的推移,也就渐渐忘 ...
- .NET面试题目
简单介绍下ADO.NET和ADO主要有什么改进? 答:ADO以Recordset存储,而ADO.NET则以DataSet表示,ADO.NET提供了数据集和数据适配器,有利于实现分布式处理,降低了对数据 ...
- C语言面试
最全的C语言试题总结 第一部分:基本概念及其它问答题 1.关键字static的作用是什么? 这个简单的问题很少有人能回答完全.在C语言中,关键字static有三个明显的作用: 1). 在函数体,一个被 ...
随机推荐
- CPU网卡亲和绑定
#!/bin/bash # # Copyright (c) , Intel Corporation # # Redistribution and use in source and binary fo ...
- Jetson TX2镜像刷板法
使用Nvidia官方自带的脚本,备份镜像.恢复镜像,快速在新板子中部署DL环境 在之前的一篇博客中,详细介绍了使用JetPack刷系统以及使用离线包部署DL环境(cuda.cudnn.opencv.c ...
- spring入门-整合junit和web
整合Junit 导入jar包 基本 :4+1 测试:spring-test-5.1.3.RELEASE.jar 让Junit通知spring加载配置文件 让spring容器自动进行注入 1234567 ...
- 安卓权威编程指南-笔记(第21章 XML drawable)
在Andorid的世界里,凡事要在屏幕上绘制的东西都可以叫drawable,比如抽象图形,Drawable的子类,位图图形等,我们之前用来封装图片的BitmapDrawable就是一种drawable ...
- GNS3(1)——OSPF多区域配置
GNS3(1)——OSPF多区域配置 RIP适用于中小网络,比较简单.没有系统内外.系统分区,边界等概念,用到不是分类的路由. OSPF适用于较大规模网络.它把自治系统分成若干个区域,通过系列内外路由 ...
- PHP 导出网页表格如何对标签中的内容设置属性
当在使用php导出excel表格的时候,有时需要将某一列专门设置成文本属性 方法: 在需要设置属性的的<td>标签中 添加 style='vnd.ms-excel.numberforma ...
- C++中如何对单向链表操作
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- Centos 安装rabbitmq
此处是通过源码进行安装的rabbitmq,参考:http://www.cnblogs.com/huangxincheng/p/6006569.html 1.源码包下载 ① erlang : http: ...
- 转pdf
一.转印厂pdf(书本类及折页类) 1.储存为(Ctrl+Shift+S) 2.保存类型选择 pdf 3.常规==>Adobe PDF预设==>选择印刷质量 4.选择标记和出血==&g ...
- 如何搭建自己的SpringBoot源码调试环境?--SpringBoot源码(一)
1 前言 这是SpringBoot2.1源码分析专题的第一篇文章,主要讲如何来搭建我们的源码阅读调试环境.如果有经验的小伙伴们可以略过此篇文章. 2 环境安装要求 IntelliJ IDEA JDK1 ...