[IROS 2018]Semantic Mapping with Simultaneous Object Detection and Localization
论文地址:https://arxiv.org/abs/1810.11525论文视频:https://www.youtube.com/watch?v=W-6ViSlrrZgwww.youtube.com
简介
目标

创新点
核心思想
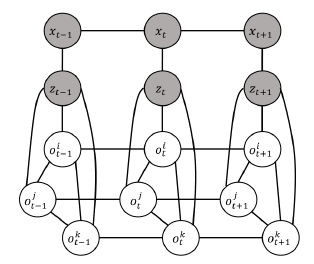
作者是如何建模的?
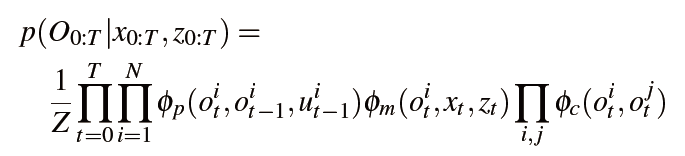
如何建模时间一致性?
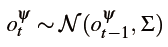
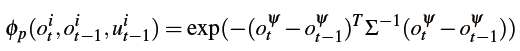
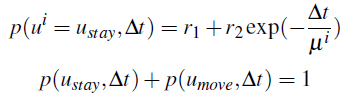
如何给定物体三维网格的观察模型?
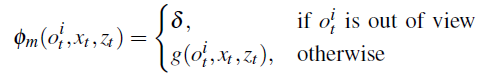
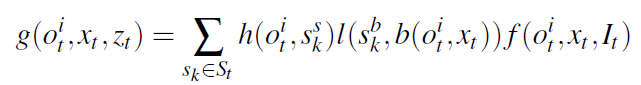
如何捕获物体之间的上下文关系?
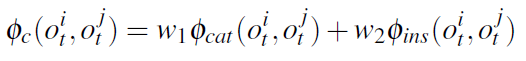
粒子滤波的算法

实验和效果
物体检测

位姿估计

本文作者:耗子
CSDN:https://blog.csdn.net/lh641446825
github:https://github.com/lh641446825
知乎:https://www.zhihu.com/people/hao-zi-meng-jian-mao/activities
[IROS 2018]Semantic Mapping with Simultaneous Object Detection and Localization的更多相关文章
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- Adversarial Examples for Semantic Segmentation and Object Detection 阅读笔记
Adversarial Examples for Semantic Segmentation and Object Detection (语义分割和目标检测中的对抗样本) 作者:Cihang Xie, ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 目标检测(一)RCNN--Rich feature hierarchies for accurate object detection and semantic segmentation(v5)
作者:Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik 该论文提出了一种简单且可扩展的检测算法,在VOC2012数据集上取得的mAP比当 ...
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
- 2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick Jeff ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- (转)Awesome Object Detection
Awesome Object Detection 2018-08-10 09:30:40 This blog is copied from: https://github.com/amusi/awes ...
随机推荐
- 没有admin权限如何免安装使用Node和NPM
此教程只针对于在windows系统上没有admin权限和软件安装权限,但是又希望能像安装版一样使用Node和NPM的用户. 步骤一: 下载压缩版node 访问https://nodejs.org/en ...
- 菜篮子成血战场!生鲜O2O为何厮杀如此惨烈
衣食住行作为与大众生活直接挂钩的刚需,已经被诸多互联网企业全面渗入,并在彻底颠覆大众原有的生活形态.但其中作为最底层.最基本的"菜篮子"--生鲜市场,似乎仍然没有被互联网元素完全& ...
- NIO-EPollSelectorIpml源码分析
目录 NIO-EPollSelectorIpml源码分析 目录 前言 初始化EPollSelectorProvider 创建EPollSelectorImpl EPollSelectorImpl结构 ...
- 超全!python的文件和目录操作总结
文件的基本读写 path = r'C:\Users\Brady\Documents\tmp' with open(path + r'\demo.txt', 'r', encoding='utf-8') ...
- AI:深度学习用于文本处理
同本文一起发布的另外一篇文章中,提到了 BlueDot 公司,这个公司致力于利用人工智能保护全球人民免受传染病的侵害,在本次疫情还没有引起强烈关注时,就提前一周发出预警,一周的时间,多么宝贵! 他们的 ...
- javascript常用工具函数总结(不定期补充)未指定标题的文章
前言 以下代码来自:自己写的.工作项目框架上用到的.其他框架源码上的.网上看到的. 主要是作为工具函数,服务于框架业务,自身不依赖于其他框架类库,部分使用到es6/es7的语法使用时要注意转码 虽然尽 ...
- 编程史话第四期-饱受争议的前端之王JavaScript的血泪成长史
写在前面 这篇博文主要介绍javaScript的发展史,根据作者在B站发布的同名视频的文案整理修改而成,对视频感兴趣的博友可访问https://www.bilibili.com/video/av945 ...
- Markdown语法说明及常用软件推荐(附链接)
Markdown语法同样支持HTML标签 以下所有字符均为英文字符 标题 标题级别由#决定,一个为一级 样例 # 一级标题 ## 二级标题 ### 三级标题 #### 四级标题 ##### 五级标题 ...
- 论JS函数传参时:值传递与引用传递的区别
什么是值传递:值传递是指在调用函数时将实际参数(实参)复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数. 值传递的总结:也就是说,将实参复制到函数中的这个过程叫值传递 什么是 ...
- echarts 图点击事件
有三种方式,介绍一下,大家学习哈 1.利用tooltip记录信息,使用zr 监听事件,进行事件处理. 这种方法是利用showTip方法或者tooltip的formatter函数记录选中的数据信息,并在 ...