(数据科学学习手札81)conda+jupyter玩转数据科学环境搭建
本文示例yaml文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
我们在使用Python进行数据分析时,很多时候都在解决环境搭建的问题,不同版本、依赖包等问题经常给数据科学工作流的搭建和运转带来各种各样令人头疼的问题,本文就将基于笔者自己摸索出的经验,以geopandas环境的搭建为例,教你使用conda+jupyter轻松搞定环境的搭建、管理与拓展。
 图1
图1
2 虚拟环境的搭建与使用
2.1 使用conda创建虚拟环境
以Windows操作系统为例,因为全程主要使用命令行,所以其他系统方法类似,有少许语句有差异的地方遇到问题时可以自行查找解决。首先我们要解决的是环境的创建,第一步需要安装conda服务,这里我们有Anaconda和miniconda两种方式,本文选择miniconda体积小巧,不会像Anaconda那样自带数量众多的科学计算相关包而显得臃肿。
有条件上外网的读者朋友可以在官网( https://docs.conda.io/en/latest/miniconda.html )下载与你的操作系统对应的安装包,也可以在清华大学镜像站-获取下载链接-应用软件-Conda( https://mirrors.tuna.tsinghua.edu.cn/ )中下载对应的最新的安装包:
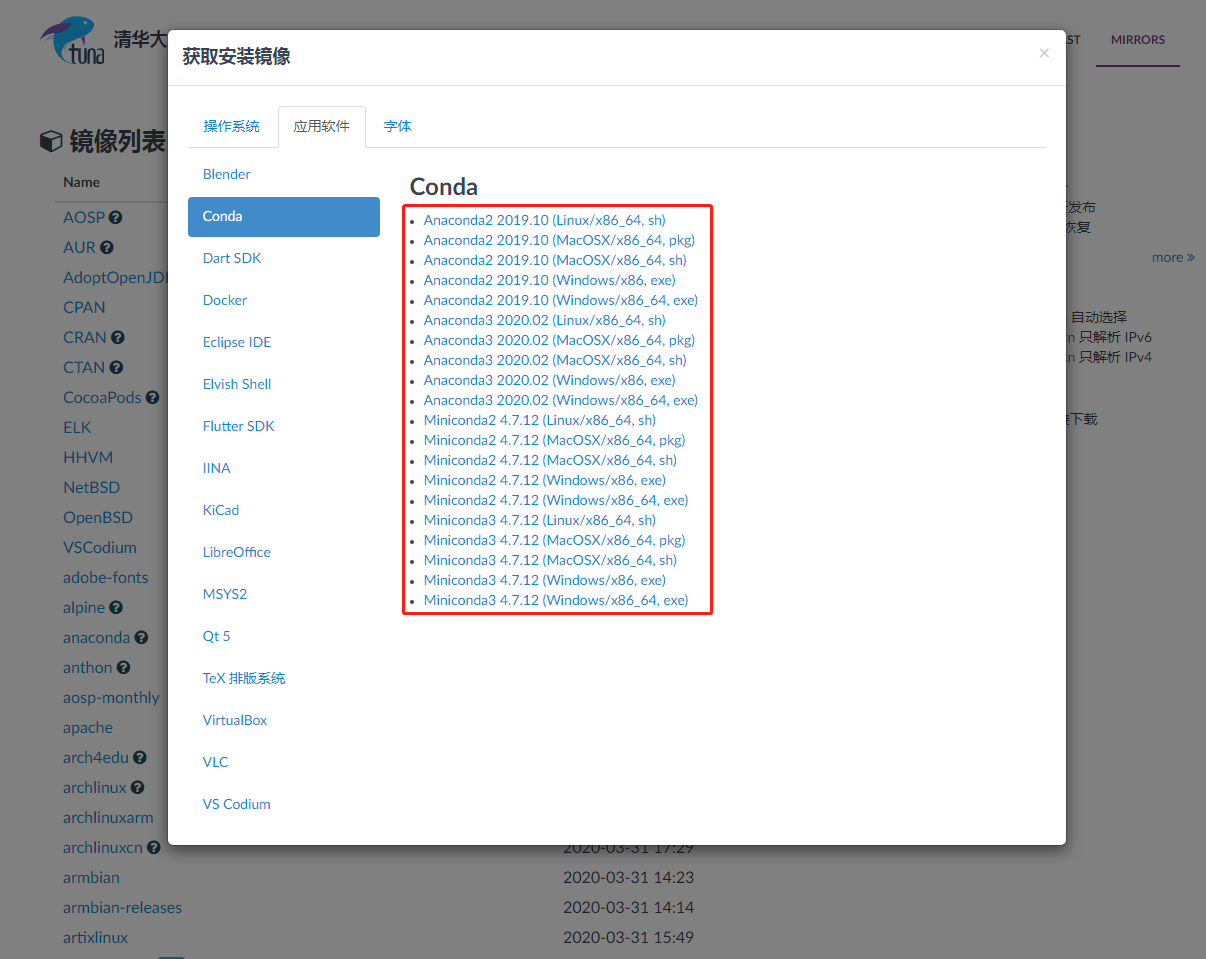 图2
图2
本文选择的是从官网下载的最新版本4.8.2,因为miniconda自带Python,之后所有新环境的创建我们都可以通过conda来实施,所以建议你在安装之前系统中不要保有其他Python环境。下载完成之后直接打开安装,一路可以按照默认的选项继续,到图3显示的步骤时为了方便之后的使用建议都勾选上:
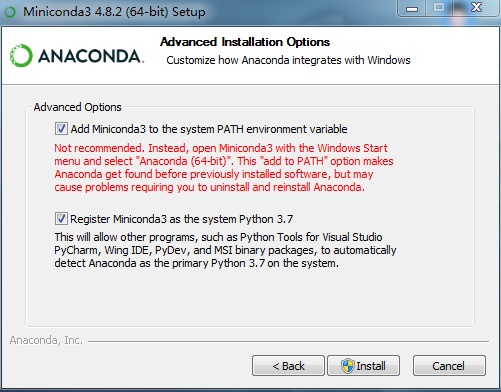 图3
图3
完成安装后我们进入控制台输入conda --version检查是否成功安装:
C:\Users\hp>conda --version
conda 4.8.2
输入conda env list查看当前存在的所有环境:
C:\Users\hp>conda env list
# conda environments:
#
base * C:\Conda
可以看到我们当前只有1个环境base,即miniconda自带的Python,因为图3中我们勾选了Register Miniconda3 as the system Python 3.7,所以在控制台中直接输入python可以得到下列结果:
C:\Users\hp>python
Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Warning:
This Python interpreter is in a conda environment, but the environment has
not been activated. Libraries may fail to load. To activate this environment
please see https://conda.io/activation
Type "help", "copyright", "credits" or "license" for more information.
>>> quit() # 退出
C:\Users\hp>
控制台输入conda list可以看到当前仅有的base环境中仅有下列包:
C:\Users\hp>conda list
# packages in environment at C:\Conda:
#
# Name Version Build Channel
asn1crypto 1.3.0 py37_0 defaults
ca-certificates 2020.1.1 0 defaults
certifi 2019.11.28 py37_0 defaults
cffi 1.14.0 py37h7a1dbc1_0 defaults
chardet 3.0.4 py37_1003 defaults
conda 4.8.2 py37_0 defaults
conda-package-handling 1.6.0 py37h62dcd97_0 defaults
console_shortcut 0.1.1 4 defaults
cryptography 2.8 py37h7a1dbc1_0 defaults
idna 2.8 py37_0 defaults
menuinst 1.4.16 py37he774522_0 defaults
openssl 1.1.1d he774522_4 defaults
pip 20.0.2 py37_1 defaults
powershell_shortcut 0.0.1 3 defaults
pycosat 0.6.3 py37he774522_0 defaults
pycparser 2.19 py37_0 defaults
pyopenssl 19.1.0 py37_0 defaults
pysocks 1.7.1 py37_0 defaults
python 3.7.6 h60c2a47_2 defaults
pywin32 227 py37he774522_1 defaults
requests 2.22.0 py37_1 defaults
ruamel_yaml 0.15.87 py37he774522_0 defaults
setuptools 45.2.0 py37_0 defaults
six 1.14.0 py37_0 defaults
sqlite 3.31.1 he774522_0 defaults
tqdm 4.42.1 py_0 defaults
urllib3 1.25.8 py37_0 defaults
vc 14.1 h0510ff6_4 defaults
vs2015_runtime 14.16.27012 hf0eaf9b_1 defaults
wheel 0.34.2 py37_0 defaults
win_inet_pton 1.1.0 py37_0 defaults
wincertstore 0.2 py37_0 defaults
yaml 0.1.7 hc54c509_2 defaults
接下来我们开始来搭建本文用于举例说明的geopandas环境,使用conda create -n 环境名称 python=版本来创建新的环境,譬如这里我们创建名为python_spatial的虚拟环境,Python版本选择3.7:
C:\Users\hp>conda create -n python_spatial python=3.7
遇到Proceed ([y]/n)?输入y继续,等相关资源下载并安装配置完成后,再次查看当前存在的所有环境:
C:\Users\hp>conda env list
# conda environments:
#
base * C:\Conda
python_spatial C:\Conda\envs\python_spatial
可以看到与之前相比多了我们刚刚创建好的python_spatial环境,使用conda activate 环境名称来激活指定的环境:
C:\Users\hp>conda activate python_spatial
(python_spatial) C:\Users\hp>
可以发现这时命令行开头多了(python_spatial),这代表我们已经进入激活的python_spatial环境中,接着我们就可以使用conda命令在当前环境中安装geopandas,按照官网的推荐方式从conda-forge对应的channel进行安装,执行conda install --channel conda-forge geopandas,遇到需要选择的地方一样地输入y,这里依赖包较多,需要等待较长时间,直到最后done出现表示安装成功,在控制台中直接进入python,检查geopandas是否正确安装:
(python_spatial) C:\Users\hp>python
Python 3.7.7 (default, Mar 23 2020, 23:19:08) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import geopandas as gpd
>>>
至此,我们已经完成了geopandas基础环境的搭建,接下来我们来配置使用jupyter。
2.2 配置jupyter lab
类似conda,jupyter也分为jupyter notebook和jupyter lab,两者核心功能都差不多,但jupyter lab拥有更多的拓展功能,并且界面和操作方式也更加炫酷方便,所以本文选择jupyter lab,在上一节中创建好的python_spatial环境下使用conda install jupyterlab安装基础部分,安装结束之后,在python_spatial环境下可以通过执行jupyter lab来打开它,在此之前需要先为jupyter lab配置虚拟环境,否则只能识别到默认的base环境。
安装ipykernel
退出虚拟环境后执行
conda install ipykernel。为虚拟环境安装ipykernel
执行
conda install -n python_spatial ipykernel。激活虚拟环境&将虚拟环境写入jupyter的kernel中
C:\Users\hp>conda activate python_spatial
(python_spatial) C:\Users\hp>python -m ipykernel install --user --name python_spatial --display-name
"spatial"
Installed kernelspec python_spatial in C:\Users\hp\AppData\Roaming\jupyter\kernels\python_spatial
(python_spatial) C:\Users\hp>
这时我们在jupyter lab中已经可以切换到python_spatial环境了,接下来为了使用jupyter lab的插件拓展,需要安装nodejs,我们在python_spatial下执行conda install nodejs即可,完成安装之后根据自己对插件功能的需要可以分别安装不同的插件,下面举几个常用的例子:
html交互部件插件
为了在
jupyter lab中渲染一些html部件,譬如tqdm中的交互式进度条,在虚拟环境下执行下列命令:
pip install ipywidgets
jupyter labextension install @jupyter-widgets/jupyterlab-manager
完成后执行jupyter lab,在打开的操作界面中notebook下点击python_spatial创建新的notebook,执行如下命令(请提前安装好tqdm),可以看到出现了交互式的进度条:
 图4
图4
目录插件
在
ipynb文件中可以用markdown编写各级别标题,在使用下列插件自动生成目录:
jupyter labextension install @jupyterlab/toc
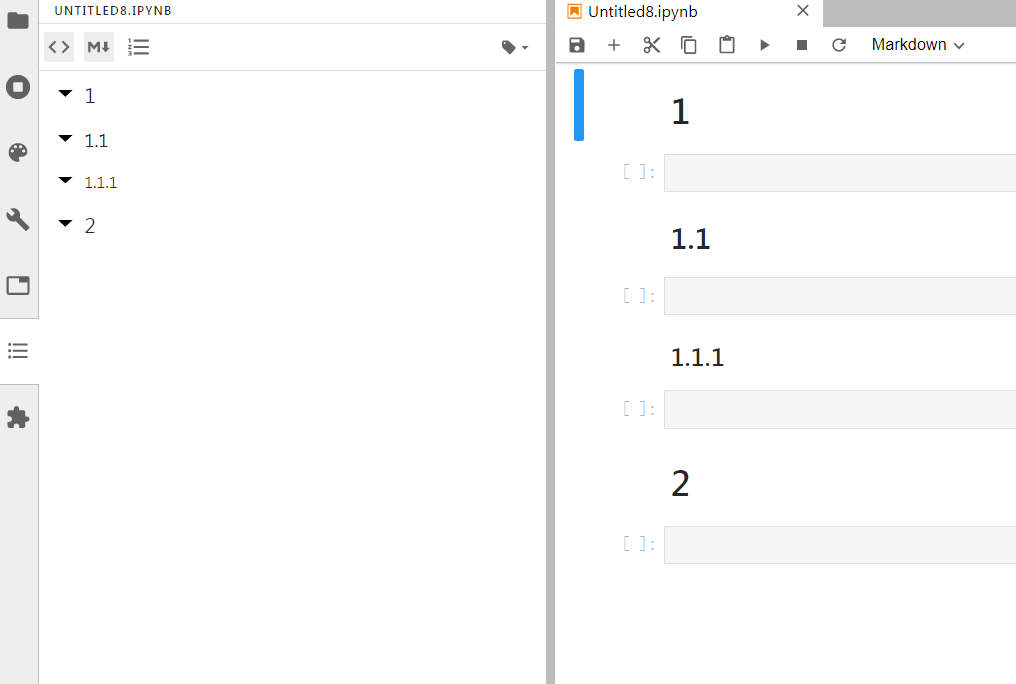 图5
图5
matplotlib交互式绘图
使用
matplotlib交互式绘图模式:
pip install ipympl
jupyter labextension install @jupyter-widgets/jupyterlab-manager jupyter-matplotlib
安装完成后就可以使用%matplotlib widget开启交互式绘图模式(请提前安装好geopandas绘图依赖包descartes):
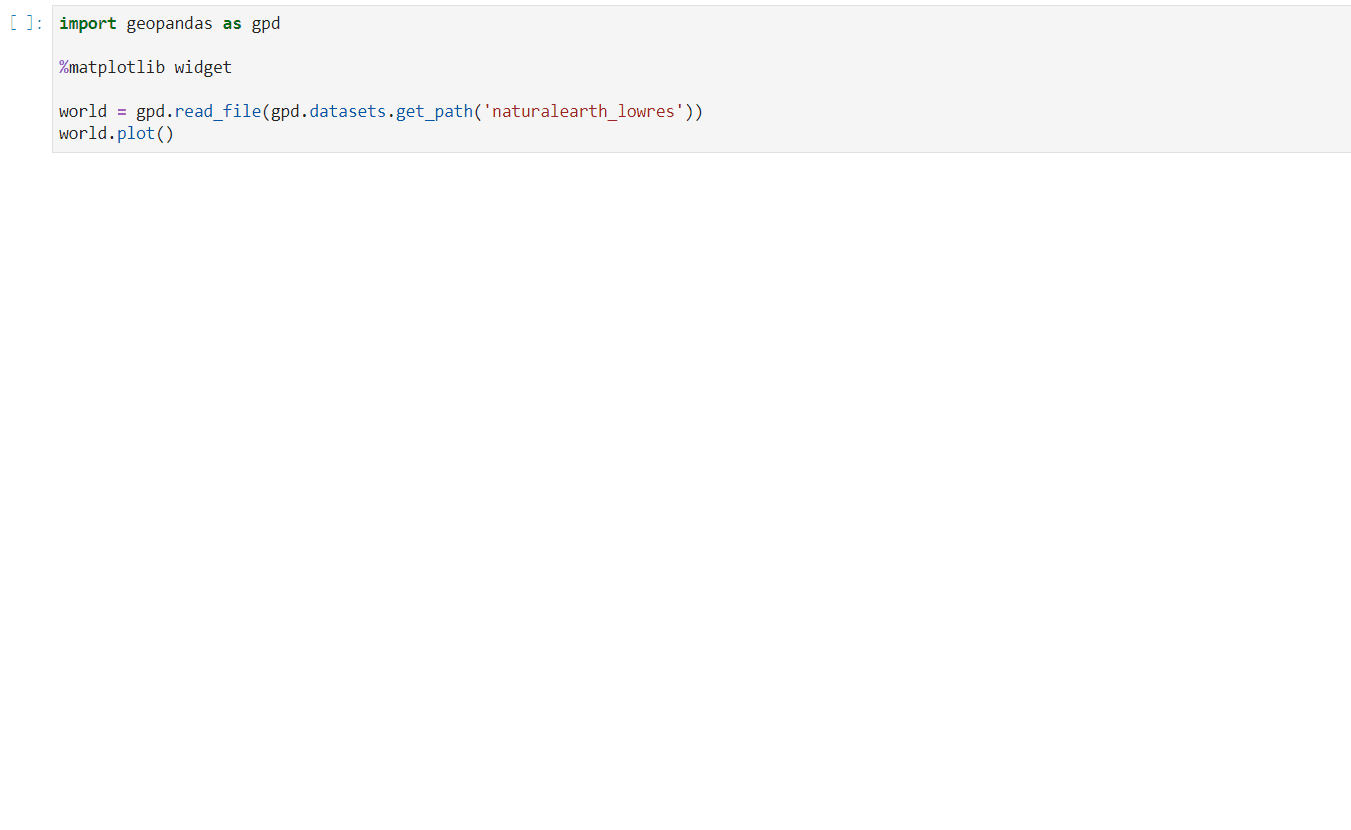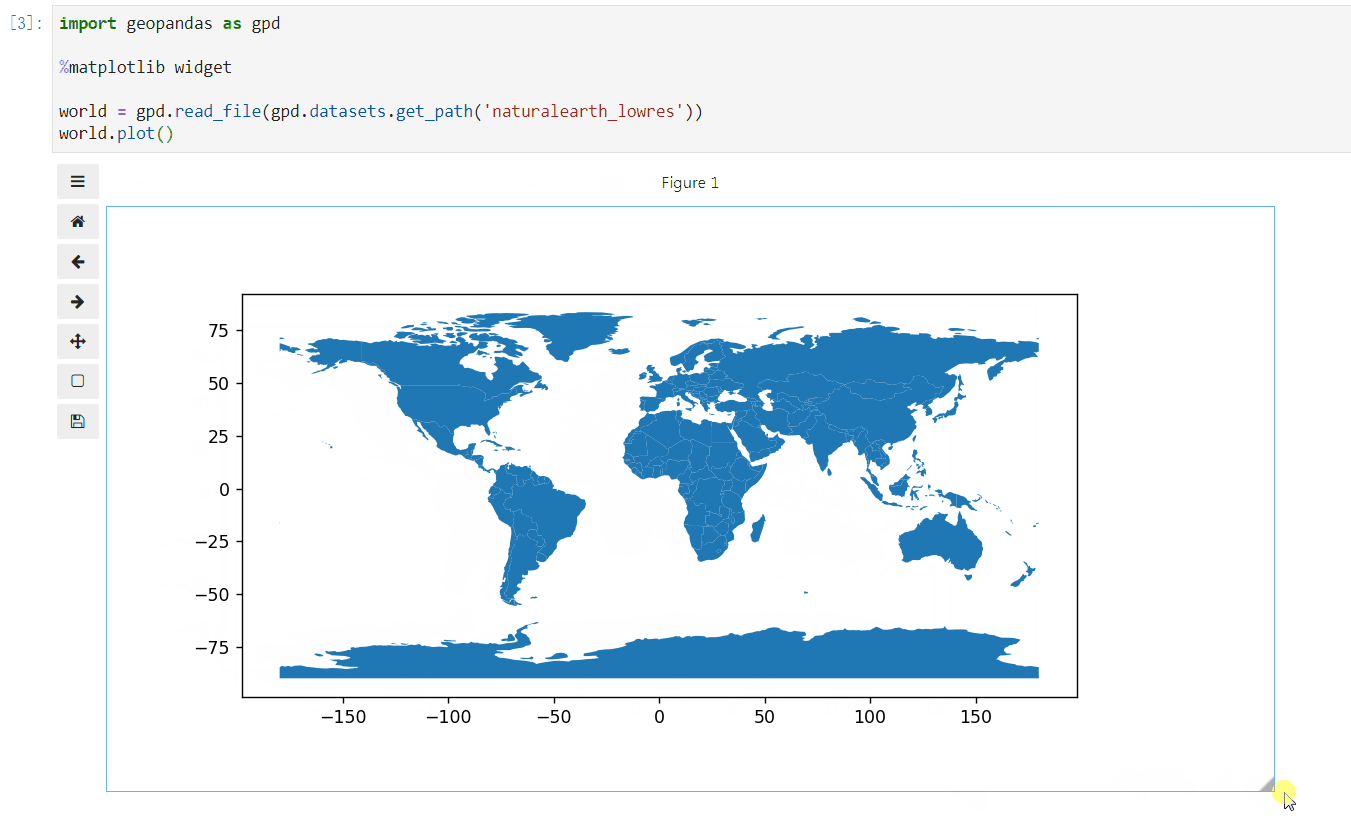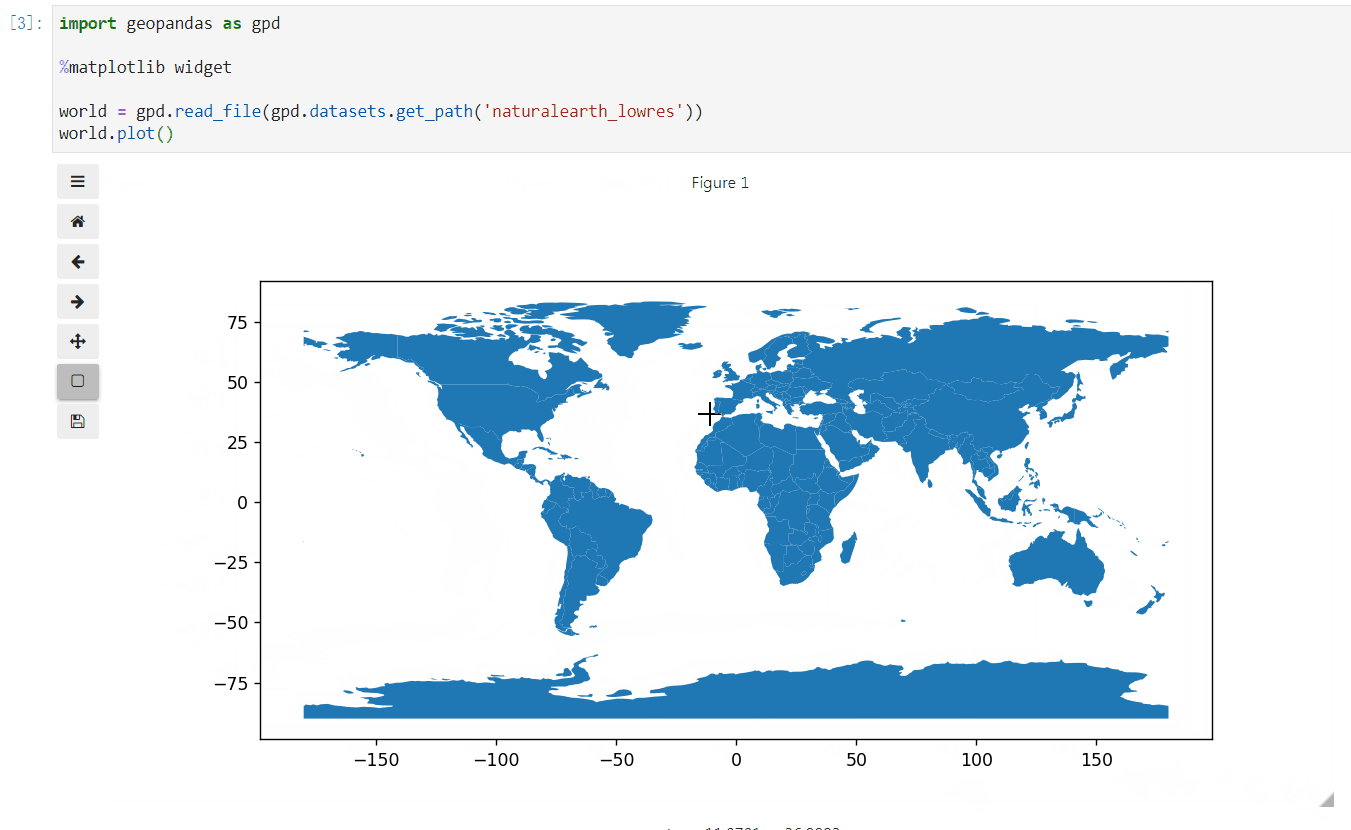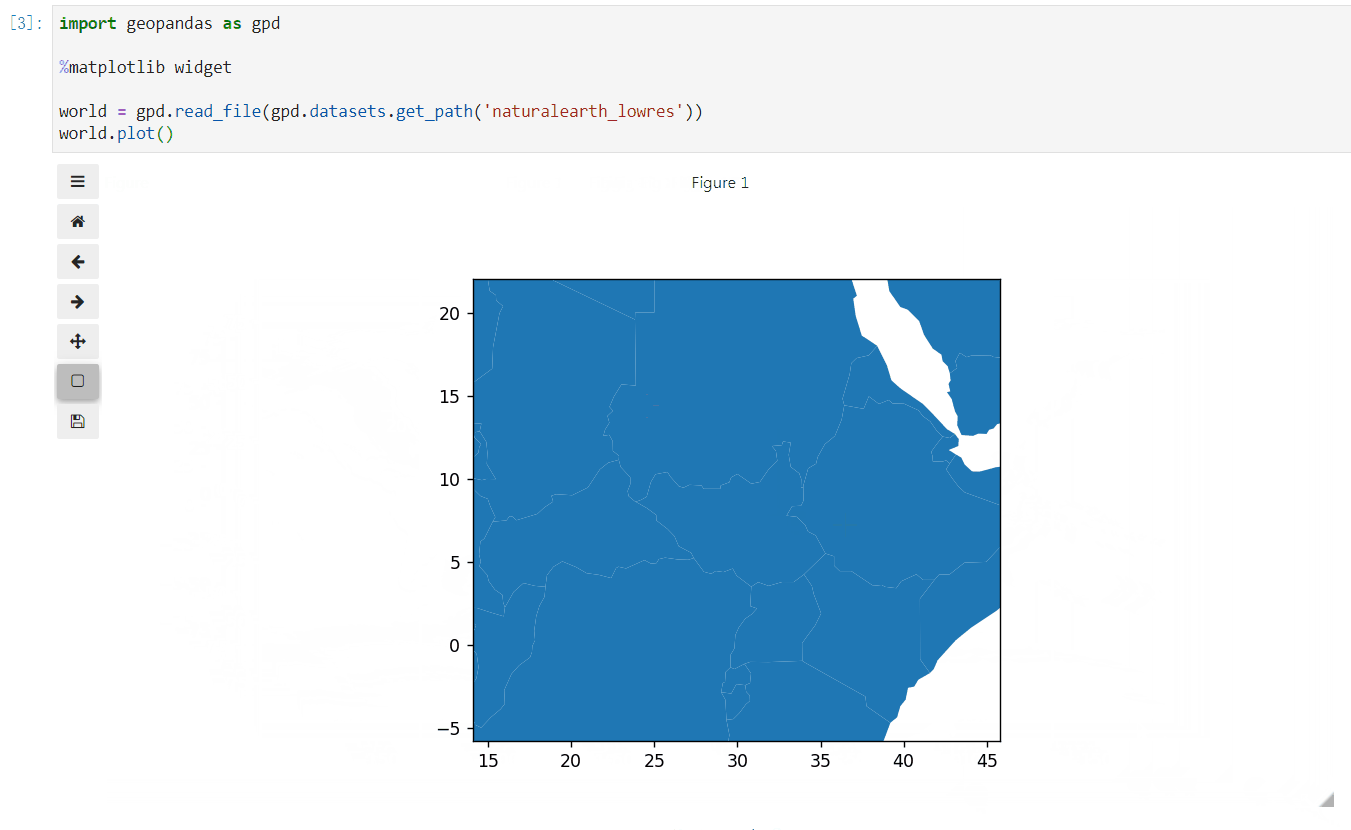 图6
图6
你也可以在侧边栏中发现更多的实用插件:
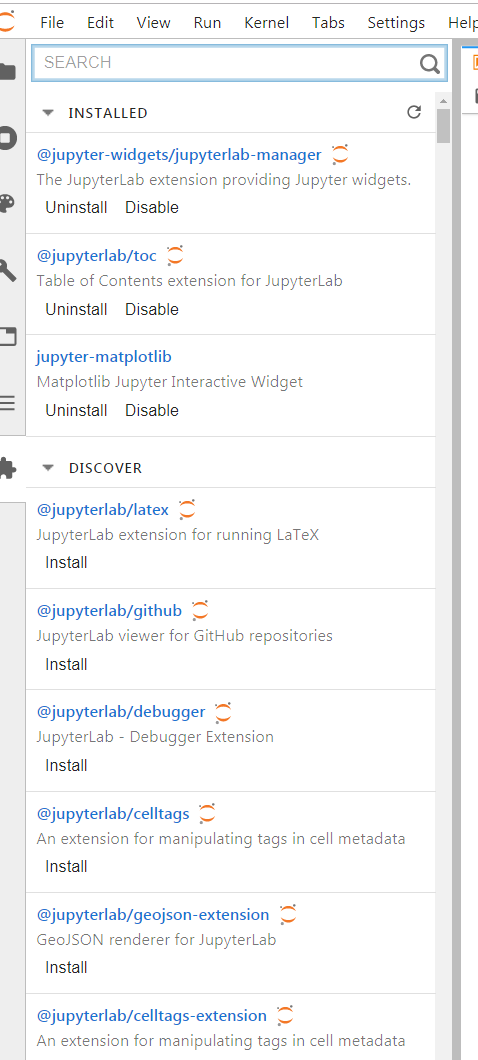 图7
图7
2.3 虚拟环境的备份和恢复
conda提供了将虚拟环境导出为yaml文件的功能,使得我们可以保留好不容易创建好的虚拟环境中的配置信息,格式如conda env export > 导出路径\文件名.yml,譬如我们导出前面创建好的python_spatial到所需路径下:
(python_spatial) C:\Users\hp>conda env export > C:\Users\hp\Desktop\python_spatial.yml
(python_spatial) C:\Users\hp>
之后你可以在安装好conda服务的其他机器上按照conda env create -n 新环境名称 -f 路径\文件名.yml,譬如我们就在本机上用已经导出的python_spatial.yml复制为新的虚拟环境,耐心等待之后conda会自动完成前面所有我们手动实现的步骤:
conda env create -n new_python_spatial -f C:\Users\hp\Desktop\python_spatial.yml
之后只需要像前文中一样执行python -m ipykernel install --user --name new_python_spatial --display-name "new spatial"从而为jupyter lab添加新的虚拟环境的kernel信息,在new_python_spatial环境下启动jupyter lab,这是我们可使用的环境变成了3个:
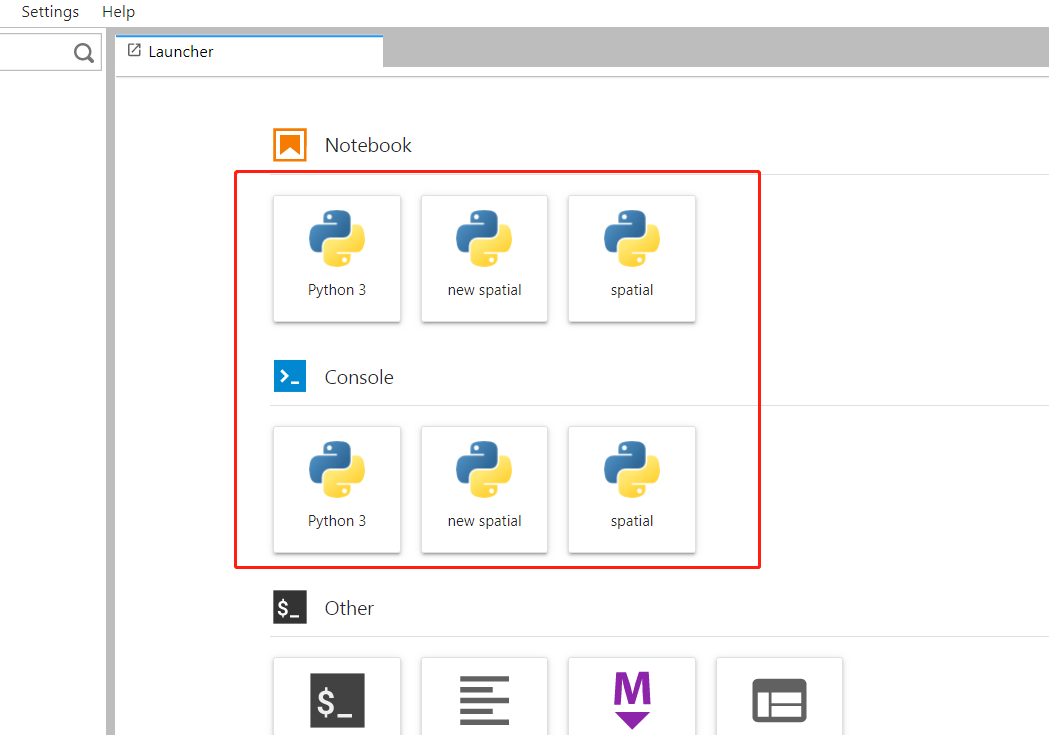 图8
图8
2.4 虚拟环境的移除
使用conda remove -n 环境名称 --all 来移除已经创建的环境,譬如我们使用conda remove -n new_python_spatial -all将new_python_spatial移除之后,再次查看所有环境:
C:\Users\hp>conda env list
# conda environments:
#
base * C:\Conda
python_spatial C:\Conda\envs\python_spatial
但这时会存在一个恼人的地方,我们这里只是移除了虚拟环境,但前面注册到jupyter lab中的kernel还会显示,但实际上是没有对应环境存在的,所以强行选择已经移除的环境对应的kernel会报错:
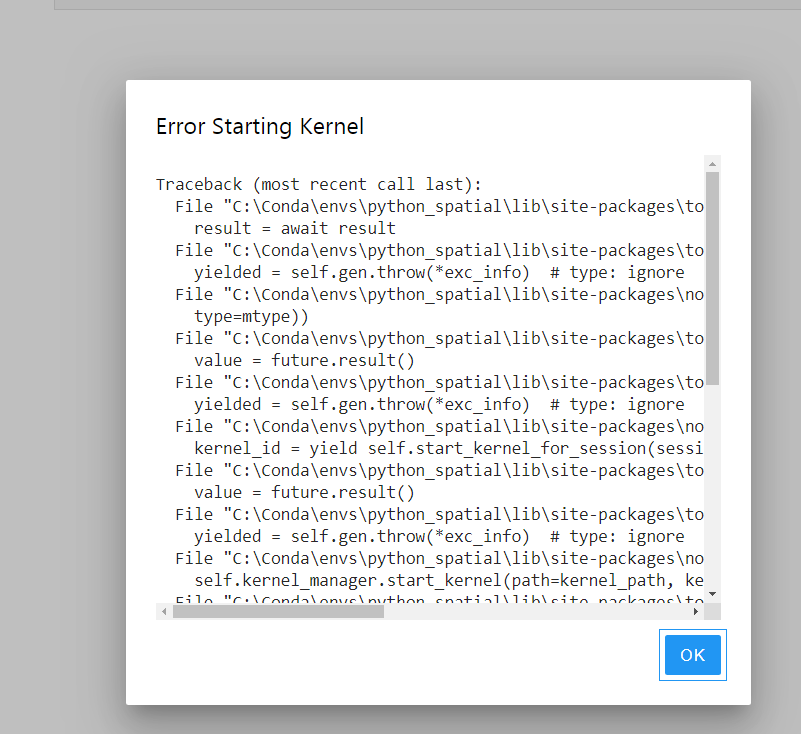 图9
图9
控制台中使用jupyter kernelspec list查看信息:
C:\Users\hp>jupyter kernelspec list
Available kernels:
new_python_spatial C:\Users\hp\AppData\Roaming\jupyter\kernels\new_python_spatial
python_spatial C:\Users\hp\AppData\Roaming\jupyter\kernels\python_spatial
python3 C:\Conda\share\jupyter\kernels\python3
接着使用jupyter kernelspec remove kernel名称对其进行移除即可:
C:\Users\hp>jupyter kernelspec remove new_python_spatial
Kernel specs to remove:
new_python_spatial C:\Users\hp\AppData\Roaming\jupyter\kernels\new_python_spatial
Remove 1 kernel specs [y/N]: y
[RemoveKernelSpec] Removed C:\Users\hp\AppData\Roaming\jupyter\kernels\new_python_spatial
之后在启动jupyter lab就会发现残余的kernel跟着消失了,而如果想要修改某个kernel的显示名称,可以同样在对应的虚拟环境下使用jupyter kernelspec list查看每个kernel以及其对应的路径,前往路径下把kernel.json中display_name键对应的值改成新名称即可。
以上就是本文的全部内容,对应的yaml文件已上传至文章开头的Github仓库中,你可以直接基于它创建对应本文python_spatial的虚拟环境,如有疑问之处可以留言或在Github仓库下创建issues向我提问。
(数据科学学习手札81)conda+jupyter玩转数据科学环境搭建的更多相关文章
- (数据科学学习手札05)Python与R数据读入存出方式的总结与比较
在数据分析的过程中,外部数据的导入和数据的导出是非常关键的部分,而Python和R在这方面大同小异,且针对不同的包或模块,对应着不同的函数来完成这部分功能: Python 1.TXT文件 导入: 以某 ...
- (数据科学学习手札59)从抓取数据到生成shp文件并展示
一.简介 shp格式的文件是地理信息领域最常见的文件格式之一,很好的结合了矢量数据与对应的标量数据,而在Python中我们可以使用pyshp来完成创建shp文件的过程,本文将从如何从高德地图获取矢量信 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
随机推荐
- Tian Tian 菾菾 导游 陪同
自画像系列是梵高的代表作之一,他是一位自学成才的画家,下笔完全自由,主观提取了当时印象派画家学到的技巧,在这幅画中,我们可以看到,颜色在画中的堆叠,色彩与笔在画中表现的形态,都表现出,梵高在他作画中内 ...
- 5G时代,什么将会消失?
5G时代说着说着就来了,当然,它不可能一撮而就,但正如4G.移动互联网和WIFI这些东西基本上是日益精进的水平,现如今饭馆的生意是否火爆,不仅仅在于其菜品和服务的质量,更在于他们有没有WIFI以及 ...
- Machine-learning-DecisionTree
前言 决策树是一种自上而下,对样本数据进行树形分类的过程,由结点和有向边组成.结点分为内部结点和叶结点,其中每个内部结点表示一个特征或属性,叶节点表示类别.从顶部根节点开始,所有样本聚在一起,经过根节 ...
- 基本类型和引用类型的值 [重温JavaScript基础(一)]
前言: JavaScript 的变量与其他语言的变量有很大区别.JavaScript 变量松散类型的本质,决定了它只是在特定时间用于保存特定值的一个名字而已.由于不存在定义某个变量必须要保存何种数据类 ...
- Kali系统中20个超好用黑客渗透工具,你知道几个?
1. Aircrack-ng Aircrack-ng是用来破解WEP/WAP/WPA 2无线密码最佳的黑客工具之一! 它通过接收网络的数据包来工作,并通过恢复的密码进行分析.它还拥有一个控制台接口.除 ...
- js面试-手写代码实现new操作符的功能
我们要搞清楚new操作符到底做了一些什么事情? 1.创建一个新的对象 2.将构造函数的作用域赋给新对象(因此this指向了这个新对象) 3.执行构造函数中的代码(为这个新对象添加属性) 4.返回新对象 ...
- CSS的常用单位 %和 vw vh 和 box-sizing:border-box; 和flex简介
一.% 理解: %号是CSS中的常用单位,它是相对于父容器而言的.如:一个父容器的宽是100px,给它的子元素一个10%,那么子元素的宽就是100px的10% 10px. 效果图: (利用%设置了li ...
- SQLyog试用到期的解决方法(仅供个人学习使用,禁止转载或用于商业盈利)
作者:EzrealYi 本章链接:https://www.cnblogs.com/ezrealyi/p/12434105.html win+r->输入regedit->进入注册表 在计算机 ...
- Tomcat8优化--Apache JMeter测试
一.部署测试java web项目(压力测试环境搭建) 1.mysql环境 #切换到mysql目录 cd /usr/local/mysql #查看mysql环境 rpm -qa | grep -i my ...
- NSFileHandle的用法(用于读写文件)
利用NSFilehandle类提供的方法,允许更有效地使用文件. 一般而言,处理文件时都要经历以下三个步骤: 1.打开文件,并获取一个NSFileHandle对象,以便在后面的I/O操作中引用该文件 ...