kafka集群搭建及结合springboot使用
1.场景描述
因kafka以前用的不多,只往topic中写入和读取过数据,这次刚好又要用到,记录下kafka集群搭建及结合springboot使用。
2. 解决方案
2.1 简单介绍
(一)关于kafka,网上的介绍有很多,简单说就是消息中间件,大数据项目中经常使用,我们项目是用于接收日志流水数据。
(二)关于消息中间件,主要有四个:
(1)ActiveMQ:历史悠久,以前项目中使用多,现在更新慢,性能相对不高。
(2)RabbitMQ:可靠性高、安全,模式比较多,java使用比较多,每秒十万级别
(3)Kafka:分布式、高性能、跨语言,性能超高,每秒百万级别,模式简单。
(4)RocketMQ:阿里开源的消息中间件,纯Java实现,有商业版,收费,导致推广一般。
(三)kafka与其他三个相比,优势在于:
(1)性能高,每秒百万级别;
(2)分布式,高可用,水平扩展。
(四) kafka官网图
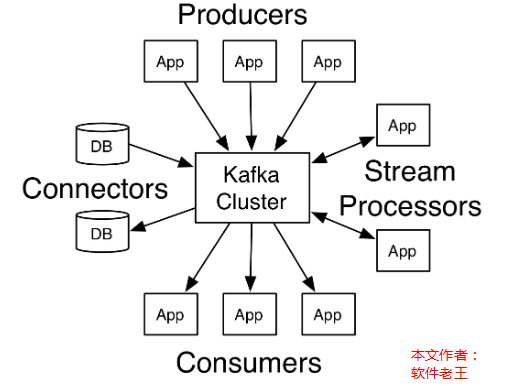
有中文官网,可以详细看看。
地址:http://kafka.apachecn.org/intro.html

2.2 软件下载
2.2.1 kakfa下载
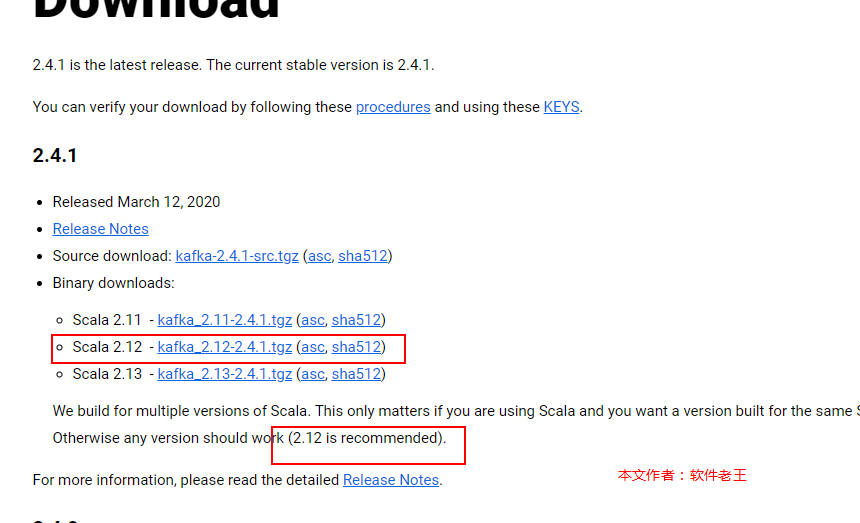
地址:http://kafka.apache.org/downloads,下载最新的2.4.1。
2.2.2 zookeeper下载
(1)因为kafka要依赖于zookeeper做调度,kafka中实际自带的有kafka,但是一般建议使用独立的zookeeper,方便后续升级及公用。
(2)下载地址:
http://zookeeper.apache.org/,最新的是3.6.0,不过发布不久,建议先跟kafka内置zookeeper保持一致,使用3.5.7版本。

2.2.3 下载说明
文件都不大,zk是9m多,kafka是50多兆

2.3 kafka单机部署及集群部署
说明:软件老王本地弄了三台虚拟机,ip分别为:
192.168.85.158
192.168.85.168
192.168.85.178
2.3.1 单机部署
(1)上传jar包,就不再新建用户了,直接在root账户下执行,将kafka和zookeeper的tar包上传到/root/tools目录下。
(2)解压
[root@ruanjianlaowang158 tools]# tar -zxvf kafka_2.12-2.4.1.tgz
[root@ruanjianlaowang158 tools]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
(3)配置zookeeper及启动
[root@ruanjianlaowang158 apache-zookeeper-3.5.7-bin]# cd /root/tools/apache-zookeeper-3.5.7-bin
#软件老王,首先创建个空文件夹,在接下来的配置文件中配置
[root@ruanjianlaowang158 apache-zookeeper-3.5.7-bin]# mkdir data
[root@ruanjianlaowang158 conf]# cd /root/tools/apache-zookeeper-3.5.7-bin/conf
[root@ruanjianlaowang158 conf]# cp zoo_sample.cfg zoo.cfg
[root@ruanjianlaowang158 conf]# vi zoo.cfg
#单机只改一个值,保存退出。
#dataDir=/tmp/zookeeper
dataDir=/root/tools/apache-zookeeper-3.5.7-bin/data
#启动zookeeper
[root@ruanjianlaowang158 bin]# cd /root/tools/apache-zookeeper-3.5.7-bin/bin
[root@ruanjianlaowang158 bin]# ./zkServer.sh start
(4)配置kafka及启动
[root@ruanjianlaowang158 kafka_2.12-2.4.1]# cd /root/tools/kafka_2.12-2.4.1
#软件老王,新建个空文件夹
[root@ruanjianlaowang158 kafka_2.12-2.4.1]# mkdir data
#软件老王,更改配置文件
[root@ruanjianlaowang158 config]# cd /root/tools/kafka_2.12-2.4.1/config
[root@ruanjianlaowang158 config]# vi server.properties
#需要改3个值
#log.dirs=/tmp/kafka-logs
log.dirs=/root/tools/kafka_2.12-2.4.1/data
#listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://192.168.85.158:9092
#zookeeper.connect=localhost:2181
zookeeper.connect=192.168.85.158:2181
#启动kafka
[root@ruanjianlaowang158 bin]# cd /root/tools/kafka_2.12-2.4.1/bin
[root@ruanjianlaowang158 bin]# ./zookeeper-server-start.sh ../config/server.properties &
启动完毕,单机验证就不验证了,直接在集群中进行验证。
2.3.2 集群部署
(1)集群方式,首先把上面的单机模式,再在192.168.85.168和192.168.85.178服务器上先解压配置一遍。
(2)zookeeper是还是更改zoo.cfg
158,168,178三台服务器一样:
[root@ruanjianlaowang158 conf]# cd /root/tools/apache-zookeeper-3.5.7-bin/conf
[root@ruanjianlaowang158 conf]# vi zoo.cfg
#其他不变,最后面新加,三行,三台服务器配置一样,软件老王
server.1=192.168.85.158:2888:3888
server.2=192.168.85.168:2888:3888
server.3=192.168.85.178:2888:3888
158服务器执行:
echo "1" > /root/tools/apache-zookeeper-3.5.7-bin/data/myid
168服务器执行:
echo "2" > /root/tools/apache-zookeeper-3.5.7-bin/data/myid
178服务器执行:
echo "3" > /root/tools/apache-zookeeper-3.5.7-bin/data/myid
(3)kafka集群配置
[root@ruanjianlaowang158 config]# cd /root/tools/kafka_2.12-2.4.1/config
[root@ruanjianlaowang158 config]# vi server.properties
#broker.id 三台服务器不一样,158服务器设置为1,168服务器设置为2,178服务器设置为3
broker.id=1
#三个服务器配置一样
zookeeper.connect=192.168.85.158:2181,192.168.85.168:2181,192.168.85.178:2181
Kafka常用Broker配置说明:
| 配置项 | 默认值/示例值 | 说明 |
|---|---|---|
| broker.id | 0 | Broker唯一标识 |
| listeners | PLAINTEXT://192.168.85.158:9092 | 监听信息,PLAINTEXT表示明文传输 |
| log.dirs | /root/tools/apache-zookeeper-3.5.7-bin/data | kafka数据存放地址,可以填写多个。用","间隔 |
| message.max.bytes | message.max.bytes | 单个消息长度限制,单位是字节 |
| num.partitions | 1 | 默认分区数 |
| log.flush.interval.messages | Long.MaxValue | 在数据被写入到硬盘和消费者可用前最大累积的消息的数量 |
| log.flush.interval.ms | Long.MaxValue | 在数据被写入到硬盘前的最大时间 |
| log.flush.scheduler.interval.ms | Long.MaxValue | 检查数据是否要写入到硬盘的时间间隔。 |
| log.retention.hours | 24 | 控制一个log保留时间,单位:小时 |
| zookeeper.connect | 192.168.85.158:2181, 192.168.85.168:2181, 192.168.85.178:2181 |
ZooKeeper服务器地址,多台用","间隔 |
(4)集群启动
启动方式跟单机一样:
#启动zookeeper
[root@ruanjianlaowang158 bin]# cd /root/tools/apache-zookeeper-3.5.7-bin/bin
[root@ruanjianlaowang158 bin]# ./zkServer.sh start
#启动kafka
[root@ruanjianlaowang158 bin]# cd /root/tools/kafka_2.12-2.4.1/bin
[root@ruanjianlaowang158 bin]# ./zookeeper-server-start.sh ../config/server.properties &
(5)注意点
集群启动的时候,单机那台服务器(158)可能会报:Kafka:Configured broker.id 2 doesn't match stored broker.id 0 in meta.properties.
方案:在158服务器data中有个文件:meta.properties,文件中的broker.id也需要修改成与server.properties中的broker.id一样,所以造成了这个问题。
(6)创建个topic,后面springboot项目测试使用。
[root@ruanjianlaowang158 bin]# cd /root/tools/kafka_2.12-2.4.1/bin
[root@ruanjianlaowang158 bin]# ./kafka-topics.sh --create --zookeeper 192.168.85.158:2181,192.168.85.168:2181,192.168.85.178:2181 --replication-factor 3 --partitions 5 --topic aaaa
2.4 结合springboot项目
2.4.1 pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.itany</groupId>
<artifactId>kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>kafka</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
说明:
主要就两个gav,一个是spring-boot-starter-web,启动web服务使用;一个是spring-kafka,这个是springboot集成额kafka核心包。
2.4.2 application.yml
spring:
kafka:
# 软件老王,kafka集群服务器地址
bootstrap-servers: 192.168.85.158:9092,192.168.85.168:9092,192.168.85.178:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: test
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
2.4.3 producer(消息生产者)
@RestController
public class KafkaProducer {
@Autowired
private KafkaTemplate template;
//软件老王,topic使用上测试创建的aaaa
@RequestMapping("/sendMsg")
public String sendMsg(String topic, String message){
template.send(topic,message);
return "success";
}
}
2.3.4 consumer(消费者)
@Component
public class KafkaConsumer {
//软件老王,这里是监控aaaa这个topic,直接打印到idea中,软件老王
@KafkaListener(topics = {"aaaa"})
public void listen(ConsumerRecord record){
System.out.println(record.topic()+":"+record.value());
}
}
2.4.5 验证结果
(1)浏览器上输入
http://localhost:8080/sendMsg?topic=aaaa&message=bbbb
(2)软件老王的idea控制台打印信息
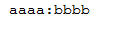
I’m 「软件老王」,如果觉得还可以的话,关注下呗,后续更新秒知!欢迎讨论区、同名公众号留言交流!
kafka集群搭建及结合springboot使用的更多相关文章
- kafka集群搭建和使用Java写kafka生产者消费者
1 kafka集群搭建 1.zookeeper集群 搭建在110, 111,112 2.kafka使用3个节点110, 111,112 修改配置文件config/server.properties ...
- Kafka【第一篇】Kafka集群搭建
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- kafka学习(三)-kafka集群搭建
kafka集群搭建 下面简单的介绍一下kafka的集群搭建,单个kafka的安装更简单,下面以集群搭建为例子. 我们设置并部署有三个节点的 kafka 集合体,必须在每个节点上遵循下面的步骤来启动 k ...
- Zookeeper + Kafka 集群搭建
第一步:准备 1. 操作系统 CentOS-7-x86_64-Everything-1511 2. 安装包 kafka_2.12-0.10.2.0.tgz zookeeper-3.4.9.tar.gz ...
- 大数据 --> Kafka集群搭建
Kafka集群搭建 下面是以三台机器搭建为例,(扩展到4台以上一样,修改下配置文件即可) 1.下载kafka http://apache.fayea.com/kafka/0.9.0.1/ ,拷贝到三台 ...
- 消息队列kafka集群搭建
linux系统kafka集群搭建(3个节点192.168.204.128.192.168.204.129.192.168.204.130) 本篇文章kafka集群采用外部zookeeper,没采 ...
- [Golang] kafka集群搭建和golang版生产者和消费者
一.kafka集群搭建 至于kafka是什么我都不多做介绍了,网上写的已经非常详尽了. 1. 下载zookeeper https://zookeeper.apache.org/releases.ht ...
- zookeeper及kafka集群搭建
zookeeper及kafka集群搭建 1.有关zookeeper的介绍可参考:http://www.cnblogs.com/wuxl360/p/5817471.html 2.zookeeper安装 ...
- 【转】kafka集群搭建
转:http://www.cnblogs.com/luotianshuai/p/5206662.html Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否 ...
随机推荐
- MAC上安装maven以及配置Intellij IDEA
大前提:java环境已经配置好 maven是对于java工程的管理 一.maven安装到mac 1.首先,maven下载地址http://maven.apache.org/download.cgi 点 ...
- leetcode第38题:报数
这是一道简单题,但是我做了很久,主要难度在读题和理解题上. 思路:给定一个数字,返回这个数字报数数列.我们可以通过从1开始,不断扩展到n的数列.数列的值为前一个数列的count+num,所以我们不断叠 ...
- gitbook安装及初步使用
gitbook安装 https://www.jianshu.com/p/421cc442f06c https://blog.csdn.net/lu_embedded/article/details/8 ...
- pressure to compete|listen to sb do|have sb do|felt like|shouldn't have done|spring up|in honour of|not more than|much as|
The pressure to compete causes Americans to be energetic, but it also puts then under a constant emo ...
- 转-Zeus资源调度系统介绍
摘要: 本文主要概述阿里巴巴Zeus资源调度系统的背景和实现思路. 本文主线:问题.解决方案.依赖基础知识.工程实践.目标.经验分享.立足企业真实问题.常规解决策略,引出依赖的容器技术.实践方案,所有 ...
- 关于HTTP请求GET和POST的区别
1.GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头<request-line>中),以?分割URL和传输数据,多个参数用&连接;例如:login.actio ...
- IOS下的safari下localStorage不起作用的问题
我们的一个小应用,使用百度地图API获取到用户的坐标之后用localStorage做了下缓存,测试上线之后有运营同学反馈页面数据拉取不到, 测试的时候没有发现问题,而且2台相同的iphone一台可以一 ...
- hql错误:No data type for node: org.hibernate.hql.ast.tree.IdentNode
今天写了一个查询,用的是hql,数据库是mysql.多表联查,结果报错了报: \-[IDENT] IdentNode: 'routerNumber' {originalText=routerNumbe ...
- 吴裕雄--python学习笔记:sqlite3 模块的使用与学生信息管理系统
import sqlite3 cx = sqlite3.connect('E:\\student3.db') cx.execute( '''CREATE TABLE StudentTable( ID ...
- 吴裕雄--天生自然 R语言开发学习:中级绘图(续一)
#------------------------------------------------------------------------------------# # R in Action ...