13-Semi-supervised Learning
半监督学习(semi-supervised learning)
1、introduction
2、Semi-supervised Learning for Generative Model
3、Low-density Separation Assumption:非黑即白
4、Smoothness Assumption:近朱者赤,近墨者黑
5、Better Representation:去芜存菁,化繁为简
Introduction

在做transductive的时候,你的unlabel data就是你的testing data,inductive learning 就是说:不把unlabel data考虑进来。
为什么做semi-supervised learning,因为有人常会说,我们缺data,其实我们不是缺data,其实我们缺的是与label的data。比如说,你收集image很容易(在街上一直照就行了),但是这些image是没有的label。label data 是很少的,unlabel是非常多的。所以semi-surprvised learning如果可以利用这些unlabel data来做某些事是会很有价值的。
我们人类可能一直是在semi-supervised learning,比如说,小孩子会从父母那边得到一点点的supervised(小孩子在街上,问爸爸妈妈这是什么,爸爸妈妈说:这是狗。在以后的日子里,小孩子会看到很多奇奇怪怪的东西,也没有人在告诉这是什么动物,但小孩子依然还是会判别出狗)。
Why semi-supervised learning help?

为什么semi-supervised learning会有效呢?
The distribution of the unlabeled data tell us something.
unlabeled data虽然只有input,但它的分布,却可以告诉我们一些事情
以下图为例,在只有labeled data的情况下,红线是二元分类的分界线

但当我们加入unlabeled data的时候,由于特征分布发生了变化,分界线也随之改变

semi-supervised learning的使用往往伴随着假设,而该假设的合理与否,决定了结果的好坏程度;比如上图中的unlabeled data,它显然是一只狗,而特征分布却与猫被划分在了一起,很可能是由于这两张图片的背景都是绿色导致的,因此假设是否合理显得至关重要。
Semi-supervised Learning for Generative Model
Supervised Generative Model

Semi-supervised Generative Model


以上的背后理论是什么?


Low-density Separation Assumption
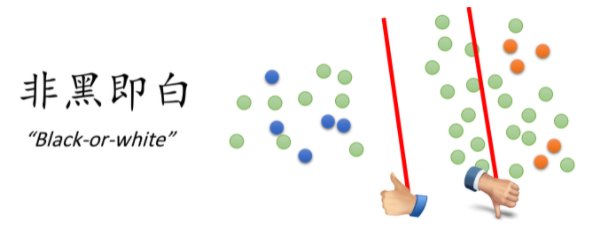
接下来介绍一种新的方法,它基于的假设是Low-density separation
通俗来讲,就是这个世界是非黑即白的,在两个class的交界处data的密度(density)是很低的,它们之间会有一道明显的鸿沟,此时unlabeled data(下图绿色的点)就是帮助你在原本正确的基础上挑一条更好的boundary。


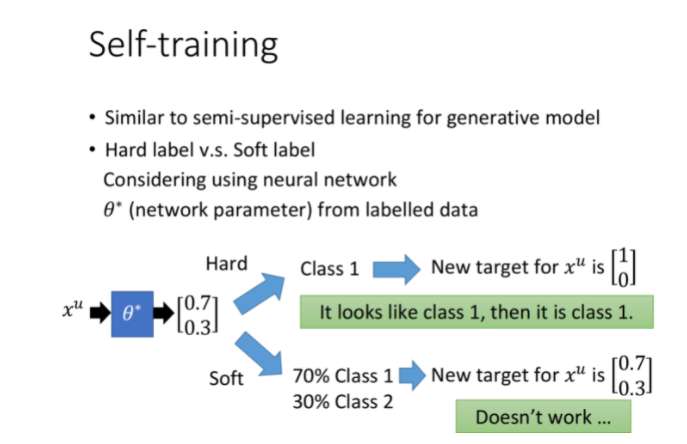
实际上,该方法与之前提到的generative model还是挺像的,区别在于:
- Self Training使用的是hard label:假设一笔data强制属于某个class
- Generative Model使用的是soft label:假设一笔data可以按照概率划分,不同部分属于不同class


Entropy-based Regularization
该方法是low-density separation的进阶版,你可能会觉得hard label这种直接强制性打标签的方式有些太武断了,而entropy-based regularization则做了相应的改进:
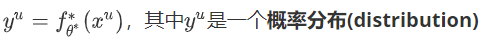


Semi-supervised SVM
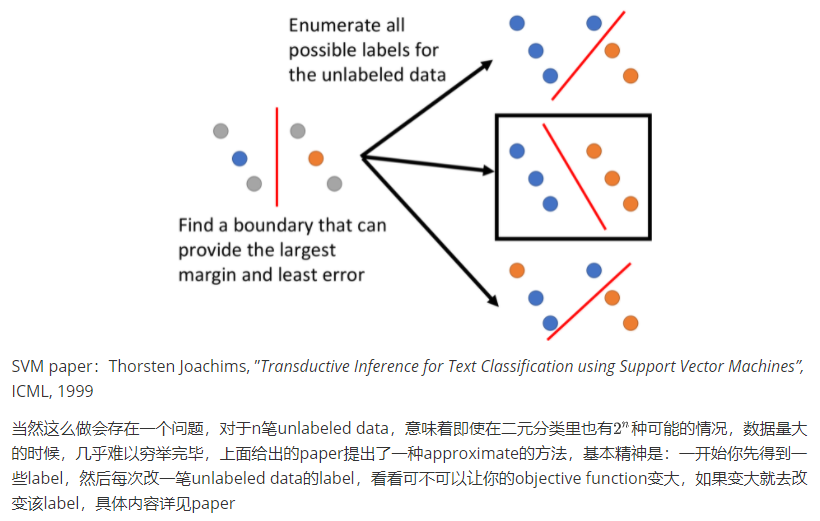
SVM要做的是,给你两个class的data,去找一个boundary:
- 要有最大的margin,让这两个class分的越开越好
- 要有最小的分类错误
对unlabeled data穷举所有可能的label,下图中列举了三种可能的情况;然后对每一种可能的结果都去算SVM,再找出可以让margin最大,同时又minimize error的那种情况,下图中是用黑色方框标注的情况
Smoothness Assumption
concepts

file classification
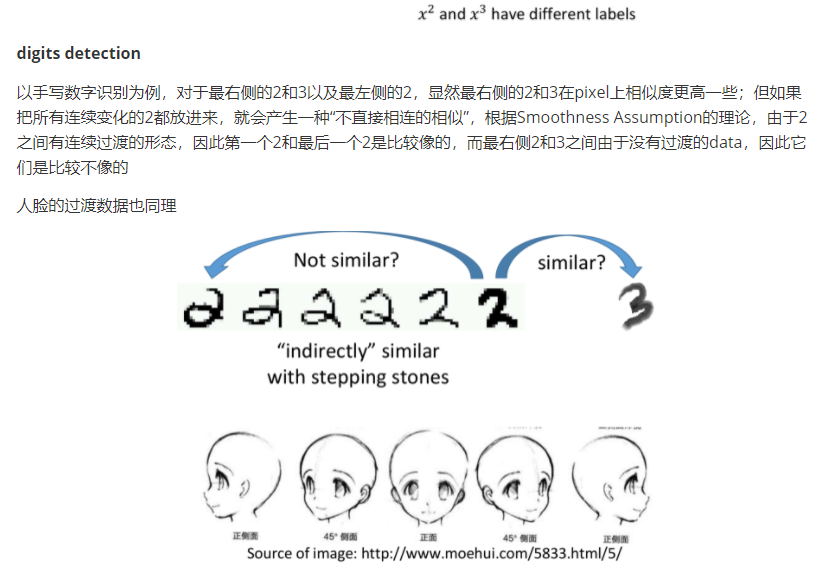
Smoothness Assumption在文件分类上是非常有用的
假设对天文学(astronomy)和旅行(travel)的文章进行分类,它们各自有专属的词汇,此时如果unlabeled data与label data的词汇是相同或重合(overlap)的,那么就很容易分类;但在真实的情况下,unlabeled data和labeled data之间可能没有任何重复的words,因为世界上的词汇太多了,sparse的分布很难会使overlap发生
但如果unlabeled data足够多,就会以一种相似传递的形式,建立起文档之间相似的桥梁。

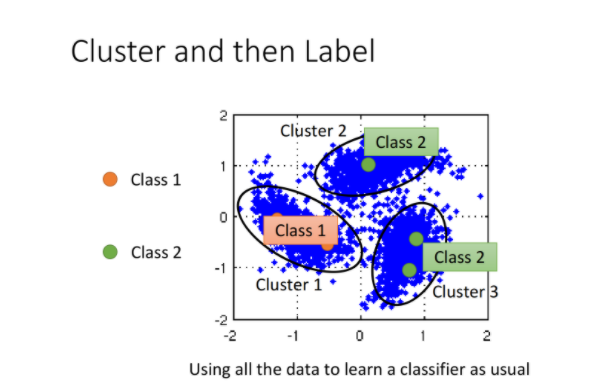
cluster and then label
在具体实现上,有一种简单的方法是cluster and then label,也就是先把data分成几个cluster,划分class之后再拿去训练,但这种方法不一定会得到好的结果,因为它的假设是你可以把同一个class的样本点cluster在一起,而这其实是没那么容易的
对图像分类来说,如果单纯用pixel的相似度来划分cluster,得到的结果一般都会很差,你需要设计一个很好的方法来描述image(类似Deep Autoencoder的方式来提取feature),这样cluster才会有效果。
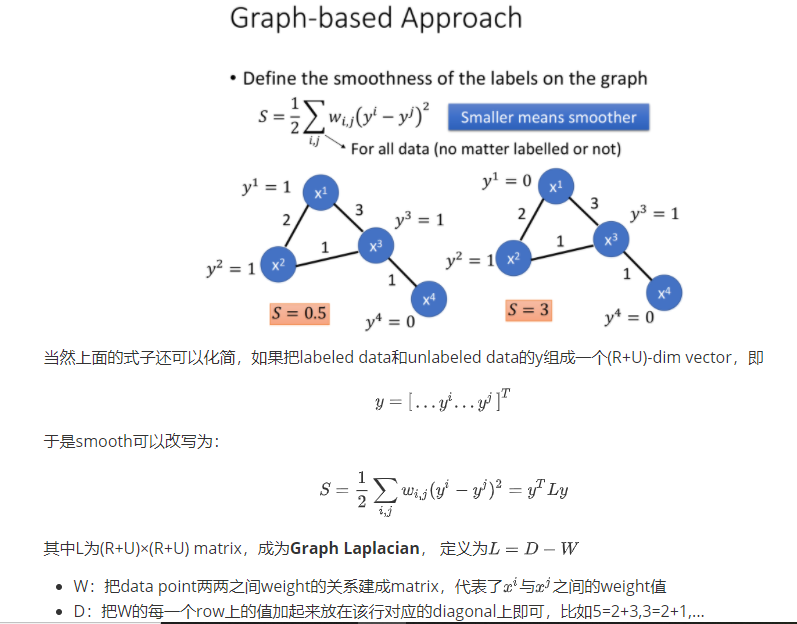
Graph-based Approach
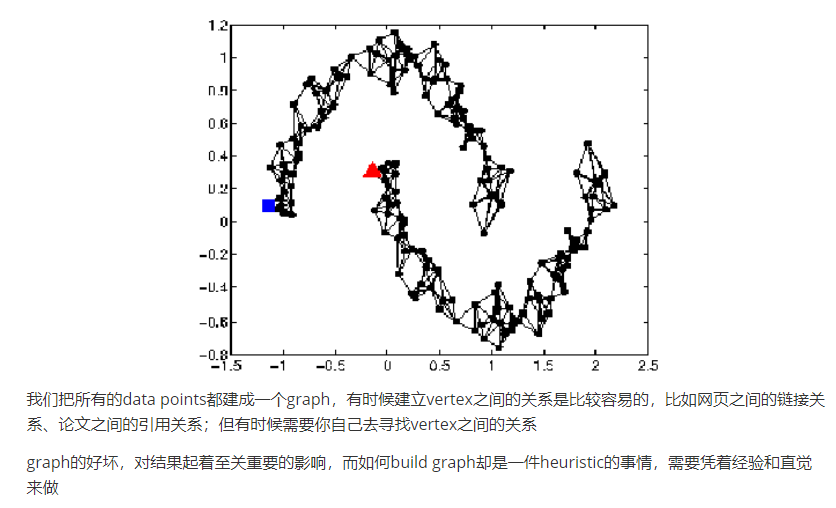
之前讲的是比较直觉的做法,接下来引入Graph Structure来表达connected by a high density path这件事

graph-based approach的基本精神是,在graph上已经有一些labeled data,那么跟它们相连的point,属于同一类的概率就会上升,每一笔data都会去影响它的邻居,而graph带来的最重要的好处是,这个影响是会随着edges传递出去的,即使有些点并没有真的跟labeled data相连,也可以被传递到相应的属性。
比如下图中,如果graph建的足够好,那么两个被分别label为蓝色和红色的点就可以传递完两张完整的图;从中我们也可以看出,如果想要让这种方法生效,收集到的data一定要足够多,否则可能传递到一半,graph就断掉了,information的传递就失效了。
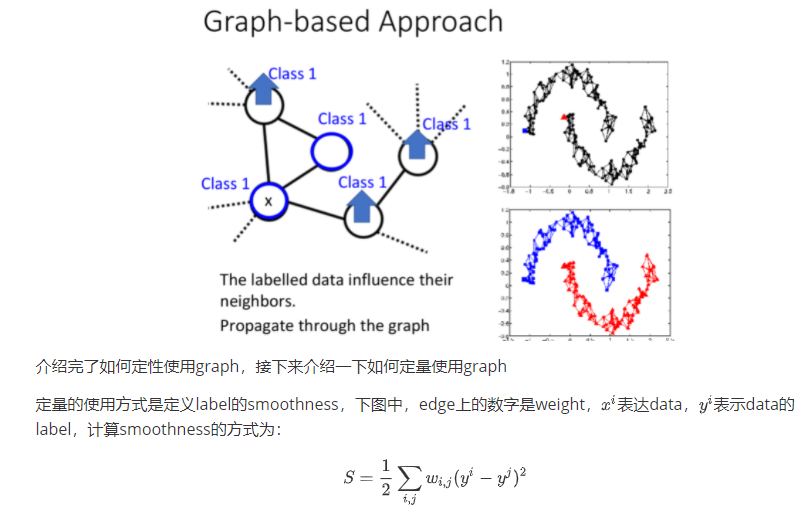
我们期望smooth的值越小越好
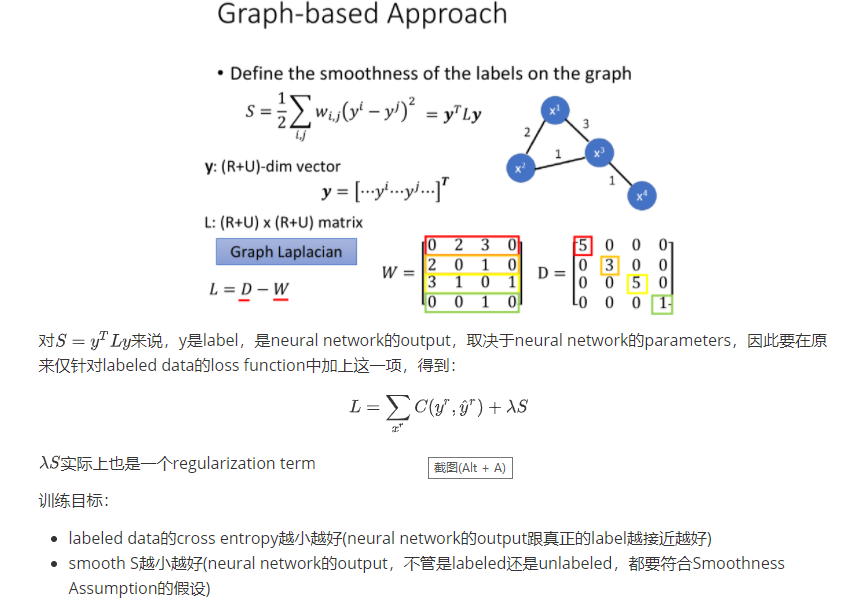

Better Representation
Better Representation的精神是,去芜存菁,化繁为简
我们观察到的世界是比较复杂的,而在它的背后其实是有一些比较简单的东西,在操控着这个复杂的世界,所以只要你能够看透这个世界的假象,直指它的核心的话,就可以让training变得比较容易
举一个例子,在神雕侠侣中,杨过要在三招之内剪掉樊一翁的胡子,虽然胡子的变化是比较复杂的,但头的变化是有限的,杨过看透了这一件事情就可以把胡子剪掉。在这个例子中,樊一翁的胡子就是original representation,而他的头就是你要找的better representation

算法具体思路和内容到unsupervised learning的时候再介绍
13-Semi-supervised Learning的更多相关文章
- Machine Learning Algorithms Study Notes(2)--Supervised Learning
Machine Learning Algorithms Study Notes 高雪松 @雪松Cedro Microsoft MVP 本系列文章是Andrew Ng 在斯坦福的机器学习课程 CS 22 ...
- A brief introduction to weakly supervised learning(简要介绍弱监督学习)
by 南大周志华 摘要 监督学习技术通过学习大量训练数据来构建预测模型,其中每个训练样本都有其对应的真值输出.尽管现有的技术已经取得了巨大的成功,但值得注意的是,由于数据标注过程的高成本,很多任务很难 ...
- A Brief Review of Supervised Learning
There are a number of algorithms that are typically used for system identification, adaptive control ...
- Supervised Learning and Unsupervised Learning
Supervised Learning In supervised learning, we are given a data set and already know what our correc ...
- 监督学习Supervised Learning
In supervised learning, we are given a data set and already know what our correct output should look ...
- 学习笔记之Supervised Learning with scikit-learn | DataCamp
Supervised Learning with scikit-learn | DataCamp https://www.datacamp.com/courses/supervised-learnin ...
- (转载)[机器学习] Coursera ML笔记 - 监督学习(Supervised Learning) - Representation
[机器学习] Coursera ML笔记 - 监督学习(Supervised Learning) - Representation http://blog.csdn.net/walilk/articl ...
- Introduction - Supervised Learning
摘要: 本文是吴恩达 (Andrew Ng)老师<机器学习>课程,第一章<绪论:初识机器学习>中第3课时<监督学习>的视频原文字幕.为本人在视频学习过程中逐字逐句记 ...
- supervised learning|unsupervised learning
监督学习即是supervised learning,原始数据中有每个数据有自己的数据结构同时有标签,用于classify,机器learn的是判定规则,通过已成熟的数据training model达到判 ...
- 1-3.监督学习(supervised learning)
定义:监督学习指的就是我们给学习算法一个数据集,这个数据集由“正确答案”组成,然后运用学习算法,算出更多的正确答案.术语叫做回归问题 [监督学习可分为]:回归问题.分类问题.两种 例:一个学生从波特兰 ...
随机推荐
- 使用gitlab runner 进行CI(二):gitlab runner的安装与配置
参考 https://docs.gitlab.com/runner/install/index.html,可以选择与gitlab相同的版本. gitlab runner可以通过安装binary包或do ...
- python自定义翻页配置
1.创建pager.py文件,针对翻页进行函数书写 class PageInfo(object): # current_page 当前页数 # all_count 所有行 # per_page 每页的 ...
- CI/CD-企业级DevOps
CI/CD-企业级DevOps 什么是DevOps? DevOps是一种思想或方法论,它涵盖开发.测试.运维的整个过程! DevOps强调软件开发人员与软件测试.软件运维.质量保障(QA) 部门之间有 ...
- 2020.1.30--vj补题
C - C CodeForces - 991C 题目内容: After passing a test, Vasya got himself a box of n candies. He decided ...
- RabbitMQ延时队列应用场景
应用场景 我们系统未付款的订单,超过一定时间后,需要系统自动取消订单并释放占有物品 常用的方案 就是利用Spring schedule定时任务,轮询检查数据库 但是会消耗系统内存,增加了数据库的压力. ...
- sip信令跟踪工具sngrep
概述 在VOIP的使用过程中,最常见的问题就是信令不通和语音质量问题. 通常的问题跟踪手段包括日志分析.抓包分析. 抓包的工具有wireshark.tcpdump等等,如果是只针对sip信令的抓包,则 ...
- Alpha发布声明
项目 内容 这个作业属于哪个课程 2021春季软件工程(罗杰 任健) 这个作业的要求在哪里 Alpha-发布声明 我们是谁 删库跑路对不队 我们在做什么 题士 进度如何 进度总览 一.功能与特性 1. ...
- Canal Server发送binlog消息到Kafka消息队列中
Canal Server发送binlog消息到Kafka消息队列中 一.背景 二.需要修改的地方 1.canal.properties 配置文件修改 1.修改canal.serverMode的值 2. ...
- Flutter应用在夜神模拟器启动白屏问题
Flutter应用在夜神模拟器启动白屏问题 flutter run 出现如下错误 [ERROR:flutter/shell/gpu/gpu_surface_gl.cc(39)] Failed to ...
- 洛谷 P4867 Gty的二逼妹子序列
链接: P4867 题意: 给出长度为 \(n(1\leq n\leq 10^5)\) 的序列 \(s\),保证\(1\leq s_i\leq n\).有 \(m(1\leq m\leq 10^6)\ ...