Python编解码问题与文本文件处理
编解码器
在字符与字节之间的转换过程称为编解码,Python自带了超过100种编解码器,比如:
- ascii(英文体系)
- gb2312(中文体系)
- utf-8(全球通用)
- latin1
- utf-16
编解码器一般有多个别名,比如
utf8、utf-8、U8。
这些编解码器可以传给open()、str.encode()、bytes.decode()等函数的encoding参数。
UnicodeEncodeError
多数非UTF编解码器(比如cp437)只能处理Unicode字符的一小部分子集。把字符转换成字节时,如果目标编码中没有定义这个字符,那么就会抛出UnicodeEncodeError异常。
处理方式一:使用utf8编码。
处理方式二:添加errors参数:
# 忽略 如b'So Paulo'
city.encode("cp437", errors="ignore")
# 替换为? 如b'S?o Paulo'
city.encode("cp437", errors="replace")
# 替换为XML实体 如b'São Paulo'
city.encode("cp437", errors="xmlcharrefreplace")
UnicodeDecodeError
把字节转换为字符时,遇到无法转换的字节时会抛出UnicodeDecodeError异常。这是因为不是每个字节都包含有效的ASCII字符,也不是每个字符都是有效的UTF-8。
处理方式也有两种,跟上面一样。
SyntaxError
Python3默认使用UTF-8编码源码。如果加载的.py模块中包含UTF-8之外的数据,而且没有声明编码,就会抛出SyntaxError异常。
处理方式是在文件顶部添加coding注释:
# coding: cp1252
但是这个办法并不好,最好还是找到这些报错字符,把它们转换为UTF-8。
从网上直接复制代码到IDE中执行经常会报这个错。
处理文本文件
Unicode三明治:
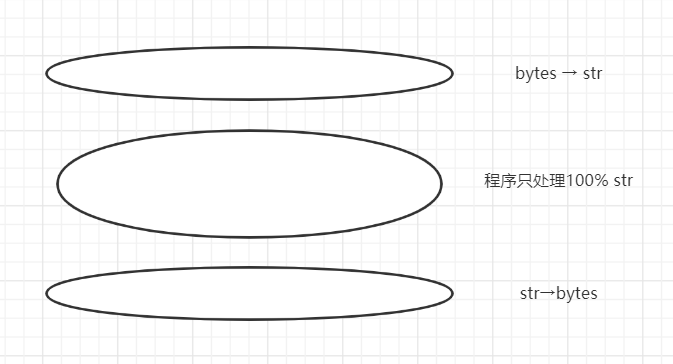
在程序中尽量少接触二进制,把字节解码为字符,只处理字符串对象。比如在Django中,view应该输出Unicode字符串,Django会负责把响应数据编码成字节序列,而且默认使用UTF-8编码。
Python内置的open函数就是采用了这个原则,在读取文件时会做必要的解码,以文本模式写入文件时会做必要的编码。
文件乱码
Windows更容易遇到这个问题,因为Windows并不是统一的UTF-8编码,比如在Windows10中:
>>> open("cafe.txt", "w", encoding="utf8").write("café")
4
>>> open("cafe.txt").read()
'caf茅'
写入文件时指定了utf8,但是读取文件没有指定,Python就会使用系统默认编码:
>>> import locale
# 打开文件用这个
# 如果没有设置PYTHONENCODING环境变量,sys.stdout/stdin/stderr也用这个
>>> locale.getpreferredencoding()
'cp936'
cp936把最后一个字节解码成了茅而不是é。
>>> import sys
# 二进制数据和字符串之间转换用这个
>>> sys.getdefaultencoding()
'utf-8'
>>> import sys
# 文件名(不是文件内容)用这个
>>> sys.getfilesystemencoding()
'utf-8'
GNU/Linux或Mac OS X不会遇到这个问题,因为多年来它们的默认编码都是UTF-8。
解决办法是一定不能依赖系统默认编码,打开文件时始终应该明确传入encoding=参数,因为不同的设备使用的默认编码可能不同,有时隔一天也会发生变化。
小结
本文介绍了Python的编解码器,以及可能出现的UnicodeEncodeError、UnicodeDecodeError、SyntaxError问题,然后给出了Python的open函数处理文本文件的原则,最后对Windows容易出现的文件乱码问题进行了说明。
参考资料:
《流畅的Python》
Python编解码问题与文本文件处理的更多相关文章
- Python 编解码
字符串编码常用类型:utf-8,gb2312,cp936,gbk等. python中,我们使用decode()和encode()来进行解码和编码 在python中,使用unicode类型作为编码的基础 ...
- python rsa 加密解密 (编解码,base64编解码)
最近有需求,需要研究一下RSA加密解密安全:在网上百度了一下例子文章,很少有文章介绍怎么保存.传输.打印加密后的文本信息,都是千篇一律的.直接在一个脚本,加密后的文本信息赋于变量,然后立马调用解密.仔 ...
- python base64 编解码,转换成Opencv,PIL.Image图片格式
二进制打开图片文件,base64编解码,转成Opencv格式: # coding: utf-8 import base64 import numpy as np import cv2 img_file ...
- Python 下JSON的两种编解码方式实例解析
概念 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写.在日常的工作中,应用范围极其广泛.这里就介绍python下它的两种编解码方法: ...
- 编解码原理,Python默认解码是ascii
编解码原理,Python默认解码是ascii 首先我们知道,python里的字符默认是ascii码,英文当然没问题啦,碰到中文的时候立马给跪. 不知道你还记不记得,python里打印中文汉字的时候需要 ...
- 【听如子说】-python模块系列-AIS编解码Pyais
Pyais Module Introduce pyais一个简单实用的ais编解码模块 工作中需要和ais打交道,在摸鱼的过程中发现了一个牛逼的模块,对ais编解码感兴趣的可以拿项目学习一下,或者运用 ...
- python中的字符串编码问题——4.unicode编解码(以实际工作中遇到的韩文编码为例)
韩文unicode编解码 问题是这样,工作中遇到有韩文数据出现乱码,说是unicode码. 类似这样: id name 323 52186863 149 63637538 314 65516863 ...
- 编解码-protobuf
Google的Protobuf在业界非常流行,很多商业项目选择Protobuf作为编解码框架,Protobuf的优点. (1)在谷歌内部长期使用,产品成熟度高: (2)跨语言,支持多种语言,包括C++ ...
- 【转】Java web 编解码
几种常见的编码格式 为什么要编码 不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言 ...
随机推荐
- Day009 稀疏数组
稀疏数组(数据结构) 场景 需求:编写五子棋游戏中,有存盘和续上盘的功能. 分析问题:因为该二维数组的很多值默认都是0,因此记录了很多没有意义的数据. 解决:稀疏数组 稀疏数组介绍 当一个数组大部分元 ...
- @ResponseBody、@RequestBody
@ResponseBody 我们在刚刚接触Springboot的第一个hello工程的时候,我们就接触了一个RestController,而通过进入它的源码,我们会发现@ResponseBody @R ...
- 【maven】pom.xml中"spring-boot-maven-plugin"报红问题
问题原因 插件下载速度太慢了,即是从国外的中央仓库里下载的. 没有刷新maven spring-boot-maven-plugin没加版本号(有些电脑不加版本号,也是不会爆红的) 问题解决 maven ...
- [技术博客]iview组件样式踩坑记录
[技术博客]iview组件样式踩坑记录 iview官方文档. 在本次项目开发中,前端项目主要使用vue框架+iview组件构建,其中iview组件在使用过程中遇到了许多官方文档中没有明确说明或是很难注 ...
- 通俗易懂的JS之Proxy
与掘金文章同步,地址:https://juejin.cn/post/6964398933229436935 什么是代理模式 引入一个现实生活中的案例 我们作为用户需要去如何评估一个房子的好坏.如何办理 ...
- Django(26)HttpResponse对象和JsonResponse对象
HttpResponse对象 Django服务器接收到客户端发送过来的请求后,会将提交上来的这些数据封装成一个HttpRequest对象传给视图函数.那么视图函数在处理完相关的逻辑后,也需要返回一个响 ...
- ES系列(五):获取单条数据get处理过程实现
前面讲的都是些比较大的东西,即框架层面的东西.今天咱们来个轻松点的,只讲一个点:如题,get单条记录的es查询实现. 1. get语义说明 get是用于搜索单条es的数据,是根据主键id查询数据方式. ...
- [刷题] PTA 6-10 阶乘计算升级版
要求: 实现一个打印非负整数阶乘的函数 N是用户传入的参数,其值不超过1000.如果N是非负整数,则该函数必须在一行中打印出N!的值,否则打印"Invalid input" 1 # ...
- Linux 用 ps 與 top 指令找出最耗費 CPU 與記憶體資源的程式最占cpu的进程
Linux 用 ps 與 top 指令找出最耗費 CPU 與記憶體資源的程式 2016/12/220 Comments ######### ps -eo pid,ppid,%mem,%cpu,cmd ...
- Linux_配置辅助DNS服务(基础)
[RHEL8]-DNSserver1:[RHEL7]-DNSserver2:[Centos7]-DNSclient !!!测试环境我们首关闭防火墙和selinux(DNSserver1.DNSserv ...