[RabbitMQ]AMQP 0-9-1:模型
上一篇文章(RabbitMQ:下载 & 安装)中,我们下载并且安装了RabbitMQ,并且成功注册了RabbitMQ服务。本文我们将学习RabbitMQ中最基础、最重要的概念:AMQP 0-9-1协议模型。
0 前言
要学好一项技术,千万不要死记硬背那些调用API,而是要理解它的执行逻辑。
RabbitMQ的执行逻辑本质上是它所支持的通讯协议。
RabbitMQ支持很多通讯协议,包括AMQP 0-9-1、AMQP 1.0、MQTT和STOMP等。其中,最重要、最常用的是AMQP 0-9-1(默认)。我们只需要充分理解这个协议,就能够解决日常工作中绝大部分RabbitMQ相关的问题。
AMQP(Advanced Message Queuing Protocol,高级消息队列协议)是二进制消息协议,即底层传输的消息是二进制数据。它的版本划分方式为major-minor[-revision]或major.minor[.revision]。AMQP 0-9-1是AMQP的0-9-1版本(major=0,minor=9,rivision=1)。
从本质上来看,AMQP 0-9-1具备两个核心功能:
- 接收消息。
- 转发消息。
为了实现这两个功能,AMQP 0-9-1提出了两方面规范:
- 在服务端层面,提出了AMQ Model(Advanced Message Queuing Protocol
Model,高级消息队列协议模型):由一系列具备路由/存储消息功能的组件,以及组件之间交互的规则组成。 - 在网络传输层面,提出了在AMQ模型下客户端与服务端以及组件之间交互的规范,具体可以分成两部分:
- 方法层(Functional Layer):规范了客户端与服务端之间、AMQ模型之间的命令。
- 传输层(Transport Layer):规范了二进制数据(包括命令和消息)的传输格式。
因此,学习AMQP 0-9-1的核心内容可以分成上述三个部分:AMQ 模型、方法和传输数据格式。
本文介绍的是第一部分:AMQ 模型。其余两部分可查看后续文章。
1 AMQ模型
再次回顾AMQ Model的定义:由一系列具备路由/存储消息功能的组件,以及组件之间交互的规则组成。
其中,核心组件包括:
- Exchange(交换机)。
- Message Queue(消息队列)。
- Binding(绑定)
其他重要的基本概念包括:Message、Connection、Channel以及Virtual Host。
消息中间件工作方式是典型的C/S模式,通常将服务器中运行的消息中间件程序称为Broker,而发布和接收消息的客户端应用程序分别称为Publisher和Consumer。
AMQ Model的组件就工作于Broker的消息中间件(如rabbitmq-server)进程中。为了方便统一管理,在创建时需要为这些组件指定对应的Virtual Host(类似于Java中的包)。
因此,AMQ模型的结构图以及工作流程如下:
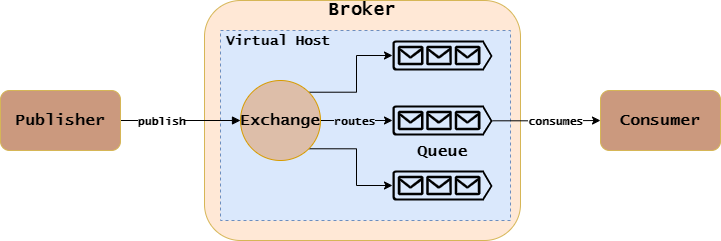
- Publisher和Consumer使用客户端工具(如rabbitmq的amqp-client),通过TCP/IP协议连接到指定的Broker。
- 服务端或客户端创建Exchange和Queue,并使用Binding组件进行绑定。
- Consumer监听Queue。
- Publisher指定某个Virtual Host下的Exchange和路由规则,发送消息。
- Broker中对应的Exchange接收到消息后,根据路由规则将消息转发给所绑定的某个/某些Queue。
- Queue将消息推送给正在监听它的Consumer。
AMQP协议的主要特点是将路由和存储消息的功能分给交给Exchange和Message Queue组件,而在AMQP之前的消息队列协议通常将路由和存储消息定义在同一个功能组件中。这样做的好处在于可以实现更灵活、多样和健壮的消息中间件系统。
2 Exchange
2.1 工作流程
Exchange的作用是:接收从Publisher发来的消息,然后根据路由规则转发消息给Message Queue。
需要注意的是,在这个过程中Exchange并不会保存消息。
如果能找到匹配的Message Queue,那么消息就能够成功转发。但是如果匹配失败,Exchange会根据自身是否存在替补交换机(Alternate Exchange)进行重新分发消息,也会根据Publisher发布消息是否指定为mandatory进行丢弃或返回给Publisher。
同时,为了保证数据安全,如果手动开启了Publisher确认机制,当消息被Broker中的Exchange接收时会返回一个确认消息basic.ack,如果没有Exchange能够接收则会响应异常信息。后续文章会深入讨论确认机制的细节。
因此,考虑到所有常见情况,RabbitMQ中Exchange的基本工作流程是:
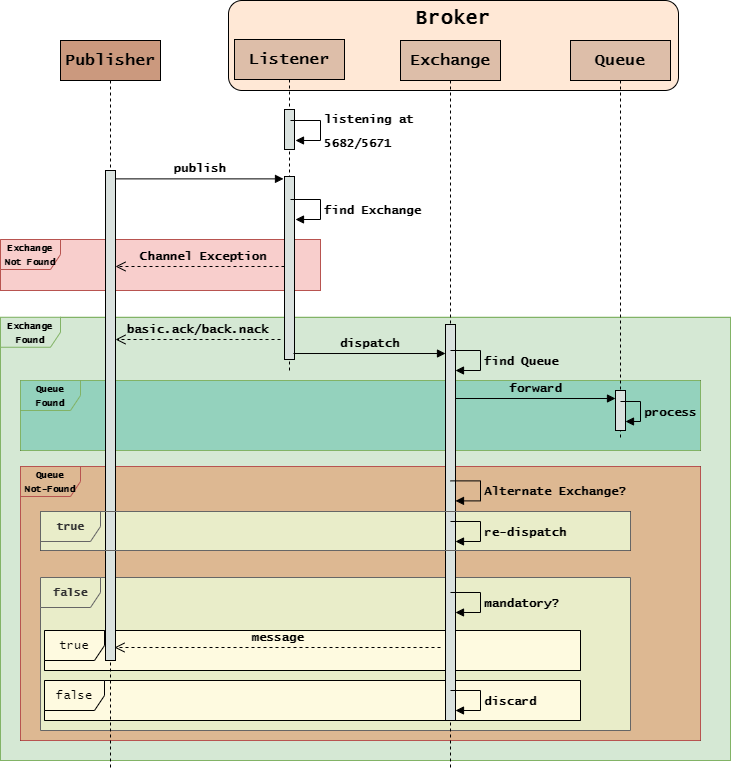
- Broker监听服务器的5682(non-ssl)或5671(ssl)端口。
- Publisher指定Exchange和路由规则,发送消息给Broker。
- Broker接收到消息:
- 未找到Exchange:响应Channel级别异常给Publisher,终止流程。
- 找到Exchange:分发消息给对应的Exchange,同时响应
basic.ack给Publisher,进行下一步。
- Exchange解析路由规则,遍历Binding列表:
- 找到Message Queue:转发消息到对应的Message Queue,终止流程。
- 未找到Message Queue,判断是否存在替补交换机:
- 存在:重新分发消息给替补交换机,替补交换机按照自己的方式解析路由规则。
- 不存在,判断
mandatory属性:false,丢弃消息,终止流程。true:返回消息给Publisher,终止流程。
2.2 交换机类型
Exchange本质上是一种路由算法,它会分析发布消息时指定的routingKey或headers,从Binding列表中找到匹配的Queue进行转发。
为了适应不同的路由情况,AMQP 0-9-1预先定义了几种不同类型的Exchange,分别对应不同的路由算法:
- Direct Exchange
- Faout Exchange
- Topic Exchange
- Headers Exchange
- System Exchange
这些交换机类型足以满足日常工作中的各种场景。
RabbitMQ实现了前四种,并在Broker中默认创建了如下Exchange实例:
amq.direct:Direct Exchange。amq.faout:Faout Exchange。amq.headers:Headers Exchange。amq.match:Headers Exchange。amq.rabbitmq.trace:Topic Exchange。amq.topic:Topic Exchange。
1、Direct Exchange
Direct Exchange工作原理:
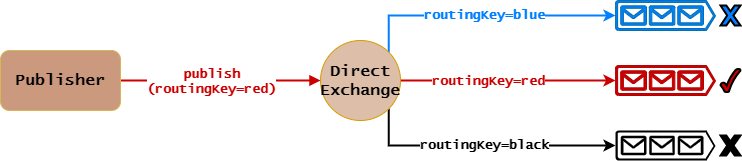
- Queue绑定到Direct Exchange时需要指定
routingKey。 - Publisher发布消息给Direct Exchange时需要指定
routingKey的值。 - Direct Exchange接收到消息时,会执行如下路由算法:
- 读取
routingKey值。 - 遍历Binding列表,找到所有
routingKey匹配的Queue。 - 转发消息给匹配Queue。
- 读取
很明显,上面原理图中,Direct Exchange会将消息转发给routingKey=red的Queue。
特别需要注意的是,Direct Exchange路由算法的唯一指标是routingKey。同时,它会将消息转发给所有匹配的Queue,而不是说找到了一个匹配的Queue就停止遍历了。
RabbitMQ默认创建了名为 (空字符串)的默认Direct Exchange,它会自动与所有Queue绑定,并指定routingKey为队列名。因此,在向默认交换机发送消息时可以直接将routingKey指定为队列名。
此外,日常工作中也习惯将routingKey与队列名使用相同值,所以容易引起混淆,让人们误以为Direct Exchange是根据队列名进行路由的。
2、Faout Exchange
Faout Exchange工作原理:
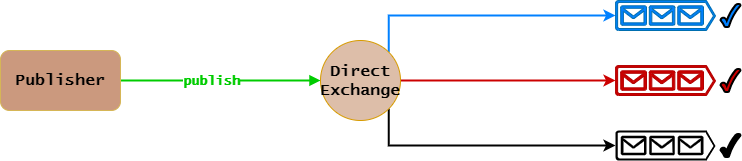
- Queue绑定到Faout Exchange时不需要指定参数。
- Publisher发布消息给Faout Exchange时也不需要指定参数。
- 遍历Binding列表,找到与之绑定的Queue。
- Faout Exchange会无条件将消息转发给所有与它绑定的Queue。
很明显,上面原理图中,Faout Exchange会将消息同时转发给与它绑定的三个Queue。
特别需要注意的是,Faout Exchange路由算法没有路由指标,它会将消息转发给所有与它绑定的Queue。
Faout Exchange的原理与计算机网络中的组播类似,通常用于实现发布/订阅场景。
3、Topic Exchange
Topic Exchange工作原理:
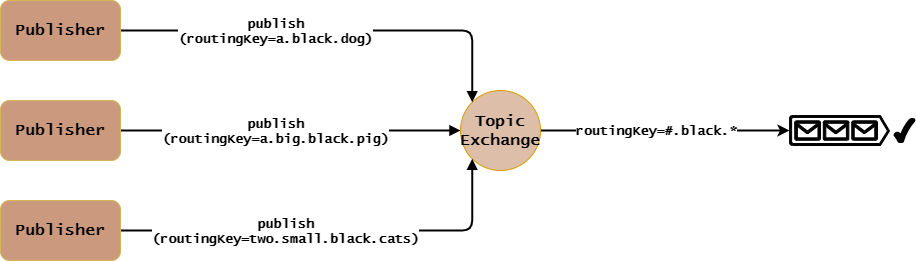
- Queue绑定到Topic Exchange时需要指定
routingKey,其值通常为以“.”分隔的多个单词。使用通配符#或*进行模糊匹配:#:匹配零或多个单词。*:匹配一个单词。
- Publisher发布消息给Topic Exchange时需要指定
routingKey,其值为确定值(即没有通配符的概念)。 - Topic Exchange接收到消息时,会执行如下路由算法:
- 读取
routingKey值。 - 遍历Binding列表,找到所有
routingKey匹配的Queue。 - 转发消息给匹配Queue。
- 读取
很明显,上面原理图中,Topic Exchange会将两条消息都转发给routingKey=#.black.*的Queue。
特别需要注意的是,Topic Exchange路由算法的唯一指标也是routingKey。同时,它会将消息转发给所有匹配的Queue,而不是说找到了一个匹配的Queue就停止遍历了。
将Direct Exchange和Topic Exchange进行对比,可以很明显地发现:
- Direct Exchange是低配版的Topic Exchange,
routingKey与Queue之间为一对一关系:一个Queue只能接收routingKey唯一对应的消息。 - Topic Exchange是高配版的Direct Exchange,
routingKey与Queue之间为多对一关系:一个Queue可以接收多种routingKey的消息。
4、Headers Exchange
Headers Exchange工作原理:
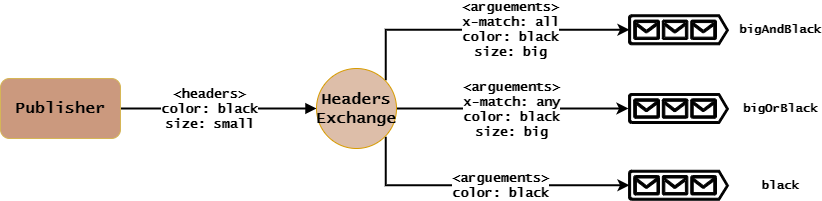
- Queue绑定到Headers Exchange时需要指定
arguement作为匹配条件,其值为key-value键值对。多个key-value键值对时,可以使用x-match指定多条件匹配关系:all:所有key-value键值对都要匹配才会进行转发,即匹配条件之间为“且”的关系。默认值。any:只要有一个key-value键值对匹配就会进行转发,即匹配条件之间为“或”的关系。
- Publisher发布消息给Headers Exchange时需要指定
headers,此时不需要添加x-match。 - headers Exchange接收到消息时,会执行如下路由算法:
- 读取请求
headers。 - 遍历Binding列表,读取绑定
arguement。 - 判断绑定
arguement的x-match值:all或没有声明x-match:绑定arguement中所有key-value在请求headers中都存在且匹配则成功,否则失败。any:绑定arguement中只要有一个key-value键值对在请求headers中存在且匹配就成功,所有绑定arguement的key-value键值对在请求headers中都不存在或不匹配才失败。
- 转发消息给匹配Queue。
- 读取请求
很明显,上面原理图中,Headers Exchange会将消息转发给bigOrBlack和black队列。
5、System Exchange
System Exchange的工作原理为:
- Publisher向System Exchange发送
routingKey=S的消息。 - System Exchange会将该消息转发给名为
S的系统服务。
RabbitMQ默认没有支持该类型交换机,所以在这里不进行过多讲解。
2.3 交换机属性
通过导出RabbitMQ的Definitions,我们可以得到Broker中的许多配置信息,从中我们可以找到交换机数据结构的存储格式如下:
"exchanges": [
{
"name": "test.exchange",
"vhost": "/",
"type": "direct",
"durable": true,
"auto_delete": false,
"internal": false,
"arguments": {
"alternate-exchange": "amq.direct",
"testArgumentsName": "testArgumentsValue"
}
}
]
exchanges:存放交换机实例的数组,内部每一个对象表示一个交换机实例。name:交换机名字。vhost:交换机所属Virtual Host。type:交换机类型,RabbitMQ中可选值为direct、faout、topic和headers。durable:是否可以持久化,可选值为true(持久化)和false(非持久化)。持久化交换机会保存到本地磁盘,Broker重启后能获取原有交换机数据。auto_delete:是否自动删除,可选值为true和false:true:当该交换机没有与之绑定的消息队列时,会被自动删除。false:当该交换机没有与之绑定的消息队列时,不会被删除,仍然可以独立存在。
internal:是否时内部使用的交换机,可选值为true和false。true:内部使用交换机,Publisher不能指定发送消息给内部交换机。false:外部使用交换机,Publisher可以将消息发送给外部交换机。通常我们声明的都是外部使用交换机。
arguments:可选参数,内部为key-value键值对,可用于完成Exchange的特定功能。例如,alternate-exchange可指定替补交换机。
3 Message Queue
3.1 工作流程
Message Queue是FIFO(First In First Out,先进先出)队列,它的作用是:
- 接收消息(from Exchange)
- 保存消息
- 发送消息(to Consumer)
RabbitMQ中Message Queue的基本工作流程是:
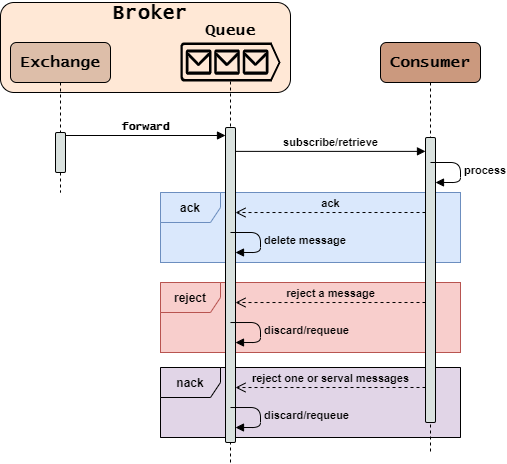
- Message Queue接收到Exchange转发的消息后,将消息保存到内存/磁盘中。
- Consumer通过订阅/拉取的方式向Message Queue获取消息。
- Message Queue将队列头部消息复制并发送给Consumer。
- 在开启手动确认模式后,Consumer会响应
ack/reject/nack给Message Queue(可以在业务处理之前或之后):ack:确认接收并处理消息(Message Queue会删除队列中保存的该消息)。reject:拒绝一条消息。nack:拒绝一条/多条消息。
- 接收
reject/nack响应后,Message Queue会根据响应是否requeue进行下一步处理:true:不删除队列中该消息,之后可以将该消息发给另外的Consumer处理。false:删除队列中该消息,可能会造成消息丢失。
- 接收
reject/nack响应后,如果设置x-dead-letter-exchange还可以重新转发给替补交换机。
3.2 消息队列属性
通过导出RabbitMQ的Definitions,我们可以得到Broker中的许多配置信息,从中我们可以找到消息队列数据结构的存储格式如下(其中不包含消息队列的内容):
"queues": [
{
"name": "testQueue",
"vhost": "/",
"durable": true,
"auto_delete": false,
"arguments": {
"x-queue-type": "classic"
}
}
]
queues:存放消息队列实例的数组,内部每一个对象表示一个消息队列实例。name:消息队列名字。vhost:消息队列所属Virtual Host。durable:是否可以持久化,可选值为true(持久化)和false(非持久化)。持久化消息队列会保存到本地磁盘,Broker重启后能获取原有消息队列数据(包括其中的消息)。exclusive:是否排他,可选值为true和false:true:消息队列独属于当前Channel,Channel关闭时消息队列会被删除。false:消息队列可以多个Channel共享。
auto_delete:是否自动删除,可选值为true和false:true:当没有Consumer订阅该消息队列时,会被自动删除。false:当没有Consumer订阅该消息队列时,不会被删除,仍然可以独立存在。
arguments:可选参数,内部为key-value键值对,可用于完成Message Queue的特定功能。例如:x-message-ttl:没有被Consumer消费的情况下,消息能够在队列中存活的时间(毫秒)。x-expires:没有被Consumer订阅的情况下,消息队列能够存活的时间(毫秒)。x-single-active-consumer:值为true/false,一次只有一个Consumer从队列中获取消息。x-dead-letter-exchange:指定消息过期或被reject(死信)后,用来重新转发消息的交换机的名字。x-dead-letter-routing-key:死信在交换机路由过程中所使用的routingKey,如果没有指定则使用原先的routingKey。x-max-length:消息队列最大能存放消息的数量。x-max-length-bytes:消息队列最大能存放消息的字节长度。x-max-priority:消息队列能提供的最小优先级。如果没有指定则不能提供消息优先级功能。x-queue-mode:是否为懒模式:lazy:消息队列会尽可能将消息保存到磁盘,而不是内存中。default(未设置):消息队列尽可能将消息保存到内存中,以实现消息的快速发送。
x-queue-master-locator:设置消息队列集群中主节点的地址。x-queue-type:设置消息队列的类型,可选值为classic、quorum和stream。
4 Binding
Exchange和Message Queue并没有存储对方的信息,那么Exchange在转发过程中是如何找到正确的Message Queue的呢?这需要借助Binding组件。
Binding中保存着source和destination属性,可以将交换机作为消息源,交换机/消息队列作为转发地址。当交换机路由消息时,会遍历Binding数组,找到source为自身的绑定关系,判断消息属性是否满足routing_key或arguments进行转发。
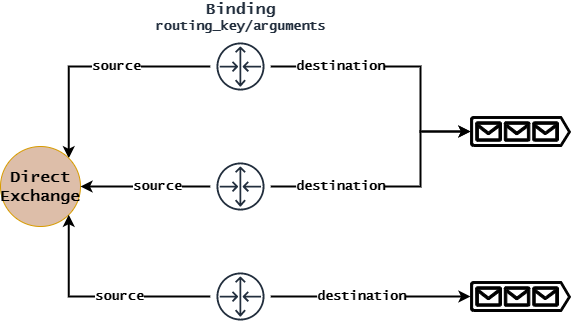
通过导出RabbitMQ的Definitions,我们可以得到Broker中的许多配置信息,从中我们可以找到Binding数据结构的存储格式如下:
"bindings": [
{
"source": "amq.headers",
"vhost": "/",
"destination": "bigAndBlue",
"destination_type": "queue",
"routing_key": "",
"arguments": {
"color": "blue",
"size": "big",
"x-match": "all"
}
}
]
source:数据源,只能是交换机。vhost:绑定关系所属Virtual Host。。destination:数据转发地址,可以是交换机或消息队列。destination_type:数据转发地址类型。queue-消息队列,exchange-交换机。routing_key:routingKey。arguments:路由参数。
5 Message
AMQP 0-9-1中传输数据的基本结构是Frame(帧),分成三类:
- 方法帧(Method Frame),RabbitMQ服务器会按照以下步骤执行方法:
- 读取方法帧载荷。
- 解析载荷到对应数据结构。
- 校验权限和参数格式。
- 执行方法。
- 内容帧(Content Frame),封装具体业务消息,包含消息头帧(content header frame)和消息体帧(content body frame)。
- 心跳帧(Heartbeat Frame),维持TCP/IP连接的心跳数据。
6 Connection & Channel
简单来说,Connection表示客户端与RabbitMQ服务器一个TCP连接。
为了对TCP连接进行多路复用,一个Connection内部可以创建多个Channel,用于不同的业务。客户端中不同Channel在发送或接收数据时,使用的都是同一个Connection。
7 Virtual Host
Virtual Host的作用类似Java中Package(包)的概念,它的作用是:建立命名空间,用来分隔交换机和消息队列。我们可以在不同Virtual Host下声明同名的交换机或消息队列。
Virtual Host本质上只是一个字符串:
"vhosts": [
{
"name": "/"
}
]
[RabbitMQ]AMQP 0-9-1:模型的更多相关文章
- RabbitMQ AMQP (高级消息队列协议)
目录 RabbitMQ AMQP (高级消息队列协议) Message Queue 简介 概念 基本组成 场景及作用 AMQP简介 模型架构 基础组件 AMQP-RabbitMQ 简介 模型 特性 参 ...
- 什么是事件代理?DOM2.0标准事件模型的三个阶段
体验更优排版请移步原文:http://blog.kwin.wang/programming/js-event-delegation.html 事件代理,又称事件委托(Delegation),就是将处理 ...
- Thinkphp5.0 的使用模型Model的获取器与修改器
Thinkphp5.0 的使用模型Model的获取器.修改器.软删除 一.获取器 在model中使用 get+字段名+Attr,可以修改字段的返回值. 数据库中性别保存为,0未知.1男.2女,查询时返 ...
- Thinkphp5.0 的使用模型Model删除数据
Thinkphp5.0 的使用模型Model删除数据 一.使用destory()删除数据 //删除id为3的记录 $res = User::destroy(3); //返回影响的行数 dump($re ...
- Thinkphp5.0 的使用模型Model更新数据
Thinkphp5.0 的使用模型Model更新数据 (1)使用update()方法进行更新数据 一.where条件写在更新数据中 (这种情况更新的数据,必须含主键) $res = User::upd ...
- Thinkphp5.0 的使用模型Model添加数据
Thinkphp5.0 的使用模型Model添加数据 使用create()方法添加数据 $res = TestUser::create([ 'name' => 'zhao liu', 'pass ...
- Thinkphp5.0 的使用模型Model查询
Thinkphp5.0 的使用模型Model查询 一.查询多条记录 获取多个数据可以使用:select()方法和all()方法. 示例一:使用all()方法. //(1)筛选条件使用闭包函数 $res ...
- Thinkphp5.0 的Model模型
Thinkphp5.0 的Model模型 新建user模型User.php: <?php namespace app\index\model; use think\Model; class Us ...
- R_针对churn数据用id3、cart、C4.5和C5.0创建决策树模型进行判断哪种模型更合适
data(churn)导入自带的训练集churnTrain和测试集churnTest 用id3.cart.C4.5和C5.0创建决策树模型,并用交叉矩阵评估模型,针对churn数据,哪种模型更合适 决 ...
- pytorch入门2.0构建回归模型初体验(数据生成)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
随机推荐
- hive -- 外部表、内部表、临时表
1.外部表 关键字:EXTERNAL 外部表创建时需要指定LOCATION 删除外部表时,数据不被删除 CREATE EXTERNAL TABLE page_view(viewTime INT, us ...
- 传统表单提交文件上传,以及FormData异步ajax上传文件
传统的文件上传: 只用将form表单的entype修改成multipart/form-data,然后就可以进行文件上传,这种方式常用并且简单. 以下是另一种方式FormData,有时候我们需要ajax ...
- linux安装mysql80
打开网址:https://dev.mysql.com/downloads/repo/yum/,选择对应li 安装mysql源 yum -y localinstall mysql80-community ...
- 小程序es6
在小程序中使用ES6的新特性ECMAScript 6(简称ES6)是于2015年6月正式发布的JavaScript语言的标准,正式名为ECMAScript 2015(ES2015). 小程序在很久之前 ...
- mybaits源码分析--缓存模块(六)
一.缓存模块 MyBatis作为一个强大的持久层框架,缓存是其必不可少的功能之一,Mybatis中的缓存分为一级缓存和二级缓存.但本质上是一样的,都是使用Cache接口实现的.缓存位于 org.apa ...
- Mybatis笔记(2)
一.Mybatis的Dao层实现 1.1 代理开发方式介绍 Mapper 接口开发需要遵循以下规范: 1. Mapper.xml文件中的namespace与mapper接口的全限定名相同 2. Map ...
- Qt之类反射机制
在java语言中,可以使用getObject(String)函数,从类型直接构建新的对象. 而在C++中是没有这种机制的,Qt虽然提供了元对象机制,但只可以获取对象的类名,不能反向构建. 所以搜索一下 ...
- ECMAScript版本知识点汇总
ECMAScript版本知识点汇总 ES5 btoa.atob 对参数进行base64格式编码.解码 /** * btoa() * base64编码 * @param {string} str * @ ...
- 关于 antd tree 组件的推拽操作
最近项目中使用到 tree 组件的推拽操作, 按常理来说应该主要用到其中的 onDrop 事件,但其中的参数又没有详细的说明,只是在官网给了个例子,网上搜索后又没有发现到位的总结. 因此经过N次的测试 ...
- 一文读懂Base64编码
Base64编码 字符对应表 上表就是用来表示Base64,一共64个字符,A-Z,a-z,0-9,+,-,还有=(作为补位) 无论将文件,字符串,还是什么转为Base64,一定是用上表的字符表示. ...