The art of multipropcessor programming 读书笔记-硬件基础2
本系列是 The art of multipropcessor programming 的读书笔记,在原版图书的基础上,结合 OpenJDK 11 以上的版本的代码进行理解和实现。并根据个人的查资料以及理解的经历,给各位想更深入理解的人分享一些个人的资料
硬件基础
处理器和线程(processors and threads)
多处理器(multiprocessor)包括多个硬件处理器,每个都能执行一个顺序程序。当讨论多处理器架构的时候,基本的时间单位是指令周期(cycle):即处理器提取和执行一条指令需要的时间。
线程是一个顺序程序,是一个软件抽象。上下文切换(context switch)指的是处理器可以执行一个线程一段时间之后去执行另一个线程。处理器可以因为各种原因撤销一个线程或者从调度中删除该线程:
- 线程发出了一个内存请求,而该请求需要一段时间才能完成
- 线程已经运行了足够长的时间,该让别的线程执行了。
当线程被从调度中删除时,他可能重新在另一个处理器上执行。
互连线(interconnect)
目前常见的三种服务器基本互联结构:
- SMP(symmetric multiprocessing,对称多处理)
- NUMA(nonuniform memory access,非一致内存访问)
SMP 指多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存。每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构(即 UMA:Uniform Memory Access)。一般 SMP 架构中,CPU 和内存之间存在高速缓存。并且,处理器和主存都有用来负责发送和监听总线上广播信息的总线控制单元(bus controller)。整体结构如下图所示:
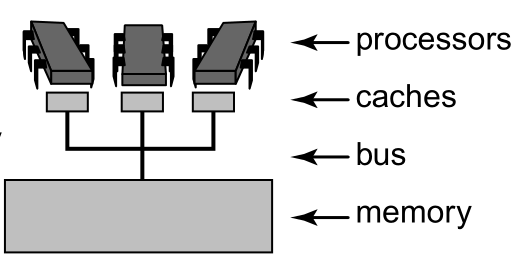
这种结构最为容易实现,但是随着处理器的增多,总线并不能扩展导致总线终将过载。
在 NUMA 系统结构中,与 SMP 相反,一系列节点通过点对点网络互相连接,有点像一个小型的局域网,每个节点包含若干个处理器和本地内存。一个节点的本地存储对于其他节点也是可以访问的,当然,访问自己的本地内存要快于访问其他节点的内存。网络比总线复杂,需要更加复杂的协议,但是带来了扩展性。如下图所示:

从程序员的角度看,无论底层是 SMP 还是 NUMA,互连线都是有限的资源。写代码的时候,要考虑这一点避免使用过多的互联线资源。
内存(memory)
所有处理器共享内存,通常会被抽象成为一个很大的“字”(words)数组,数组下标即为地址(address)。字长度和平台相关,现在多为 64 位,地址的最大长度也是这么长。64 位能表示的内存就已经很大了。
处理器访问内存的流程,简单概括包括:
- 处理器通过给内存发送一个包含要读取的地址的消息,来获取内存上对应地址的值
- 处理器通过给内存发送一个包含要写入的地址和值的消息,数据写入后,内存回复一个确认消息。
高速缓存(Cache)
缓存命中率
如果处理器一直直接从内存中读取,处理器直接访问内存消耗时间很长,可能需要几百个指令周期,这样效率会很低。一般需要引入若干个高速缓存(Cache):与处理器紧挨着的小型存储器,位于处理器和内存之间。
当需要读取一个地址的值时,访问高速缓存看是否存在:存在代表命中(hit),直接读取。不存在被称为缺失(miss)。同样的,如果需要写一个值到一个地址,这个地址在缓存中存在也就不需要访问内存了。
我们一般比较关心高速缓存中命中的请求比例,也就是缓存命中率
局部性与缓存行
大部分程序都表现出较高的局部性(locality):
- 如果处理器读或写一个内存地址,那么它很可能很快还会读或写同一个地址。
- 如果处理器读或写一个内存地址,那么它很可能很快还会读或写附近的地址。
针对局部性,高速缓存一般会一次操作不止一个字,而是一组临近的字,称为缓存行。
多级高速缓存
现代处理器中一般不止一级缓存,而是多级缓存,从离处理器最近到最远分别是 L1 Cache,L2 Cache 和 L3 Cache:
- L1 Cache 通常和处理器位于同一个芯片,离处理器最近,访问仅需要 1~3 个指令周期
- L2 Cache 通常和处理器位于同一个芯片,处于边缓位置,访问需要通过更远的铜线,甚至更多的电路,从而增加了延时,一般在 8 ~ 11 个指令周期左右
- L3 Cache L1/L2 为每个处理器私有的,这样导致对于很多相同的数据,也只能每个处理器独有的缓存各保存一份。所以需要考虑引入一个所有处理器共用的缓存,这就是 L3 缓存。L3 缓存的材质以及布线都和 L1/L2 不同,需要更长的时间访问,一般在 20 ~ 25 个指令周期左右
高速缓存内存有限,在同一时刻只有一部分内存单元被放置在高速缓存中,因此我们需要缓存替换策略。如果替换策略可以替换任何缓存行,则该高速缓存是全相联(fully associative)的。相反,如果只能替换一个特定的缓存行,他就是直接映射(direct mapped)的。如果取其折中,即允许使用一组大小为 k 的集合中任一缓存行来替换,则称为k 级组相联(k-way set associative)的。
一致性(coherence)
当一个处理器访问另一个处理器已经装载入高速缓存的主存地址的时候,就会发生共享(sharing,或者称为争用 contention)。需要考虑缓存一致性的问题,因为如果一个处理器要更新共享的缓存行,则另一个处理器的副本需要作废以免读取到过期的值。
MESI 缓存一致性协议,缓存行存在以下四种状态:
- Modified:缓存行被修改,最终一定会被写回入主存,在此之前其他处理器不能再缓存这个缓存行。
- Exclusive:缓存行还未被修改,但是其他的处理器不能将这个缓存行载入缓存
- Shared:缓存行未被修改,其他处理器可以加载这个缓存行到缓存
- Invalid:缓存行中没有有意义的数据
举例:假设处理器和主存由总线连接,如图所示:
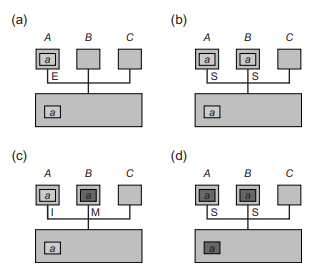
a) 处理器 A 从地址 a 读取数据,将数据存入他的高速缓存并置为 Exclusive
b) 处理器 B 从地址 a 读取数据,处理器 A 检测到地址冲突,响应缓存中 a 地址的数据,之后, 地址 a 的数据被 A 和 B 以 Shared 状态装入缓存
c) 处理器 B 对于 a 进行写操作,状态修改为 Modified,并广播提醒 A(所有其他已经将该数据装入缓存的处理器),状态置为 Invalid。
d) 随后 A 还需要访问 a,它会广播这个请求,B 将修改过的数据发到 A 和主存上,并且置两个副本状态为 Shared。
当处理器访问逻辑上不同的数据,但是这些数据恰好处于同一内存行,这种情况被称为错误共享(false sharing)
自旋(Spinning)
自旋即:某个处理器不断地检查内存中的某个字,等待另一个处理器改变它。
对于具有高速缓存的 SMP 或者 NUMA 系统结构,自旋仅消耗非常少的资源。根据上面我们对于 MESI 的介绍,第一次读取地址时,会产生一个高速缓存缺失,将该地址的内容加载到缓存块中。此后,只要数据没有改变,处理器仅从高速缓存读取数据,不需要占用互连线。当这个地址被修改时,处理器也会接收到 Invalid 并且重新请求这个数据并获取到修改。
为何 TTASLock 要优于 TASLock。
通过之前的分析,我们可以知道, TASLock 的每次 LOCKED.compareAndSet(this, false, true) 的时候,都会产生修改信号,占用互连线带宽。while 循环每次都执行,会产生大量修改信号。但是 TTASLock 的 LOCKED.get(this) 仅仅是一次本地自旋。所以 TTASLock 要比 TASLock 性能快得多。
The art of multipropcessor programming 读书笔记-硬件基础2的更多相关文章
- The art of multipropcessor programming 读书笔记-硬件基础1
本系列是 The art of multipropcessor programming 的读书笔记,在原版图书的基础上,结合 OpenJDK 11 以上的版本的代码进行理解和实现.并根据个人的查资料以 ...
- The art of multipropcessor programming 读书笔记-3. 自旋锁与争用(2)
本系列是 The art of multipropcessor programming 的读书笔记,在原版图书的基础上,结合 OpenJDK 11 以上的版本的代码进行理解和实现.并根据个人的查资料以 ...
- The Art of Multiprocessor Programming读书笔记 (更新至第3章)
这份笔记是我2013年下半年以来读“The Art of Multiprocessor Programming”这本书的读书笔记.目前有关共享内存并发同步相关的书籍并不多,但是学术文献却不少,跨越的时 ...
- Head First HTML5 Programming 读书笔记
1:HTML5引入了简单化的标记,新的语义和媒体元素,另外要依赖于一组支持web应用的js库. 2:关于js 对象是属性的结合 window对象是全局变量. document对象是window的一个属 ...
- Clr Via C#读书笔记---线程基础
趣闻:我是一个线程:http://kb.cnblogs.com/page/542462/ 进程与线程 进程:应用程序的一个实例使用的资源的集合.每个进程都被赋予了一个虚拟地址空间. 线程:对CPU进行 ...
- 3D数学读书笔记——矩阵基础
本系列文章由birdlove1987编写,转载请注明出处. 文章链接:http://blog.csdn.net/zhurui_idea/article/details/24975031 矩 ...
- PILE读书笔记_基础知识
程序的构成 Linux下二进制可执行程序的格式一般为ELF格式. 我们可以用readelf命令来读取二进制的信息. ELF文件的主要内容就是由各个section及symbol表组成的. 下面来分别介绍 ...
- 3D数学读书笔记——矩阵基础番外篇之线性变换
本系列文章由birdlove1987编写.转载请注明出处. 文章链接:http://blog.csdn.net/zhurui_idea/article/details/25102425 前面有一篇文章 ...
- Javascript DOM 编程艺术(第二版)读书笔记——DOM基础
1.DOM是什么 D=document(文档) O=object(对象) M=Model(模型) DOM又称节点树 一些术语: parent(父) child(子) sibling(兄弟) ...
随机推荐
- css - 样式 - 可见性
visibility 可见性 取值:visible(可见) | hidden(隐藏.保留占位) 设置给:块.行内块.行内元素 作用:设置元素在文档上的可见性 此属性只是隐藏元素,但会为元素保留占位. ...
- Git(GitHub)配合TortoiseGit使用
1.首先下载安装配置Git 安装请参照 https://www.cnblogs.com/xueweisuoyong/p/11914045.html 配置请参照 https://www.jianshu. ...
- 五分钟搞定Docker安装ElasticSearch
前言 项目准备上ElasticSearch,为了后期开发不卡壳只能笨鸟先飞,在整个安装过程中遇到以下三个问题. Docker安装非常慢 ElasticSearch-Head连接出现跨域 Elastic ...
- mini-ndn0.5.0 安装教程 (避免踩坑)
写在前面 首先需要确定一些配置,因为在安装的过程中需要编译一些内容,所以需要提前准备好. 本人之前ubuntu系统可能比较乱,在尝试很多次安装后,仍然失败,所以就直接重装了一下.说一下我自己的一些配置 ...
- IO和零拷贝
I/O介绍 I/O主要为:网络IO(本质是socket文件读取).磁盘IO 每次IO,都要经由两个阶段: 第一步:将数据从文件先加载至内核内存空间(缓冲区),等待数据准备完成,时间较长 第二步:将数据 ...
- 洛谷P1314 聪明的质监员 题解
题目 聪明的质监员 题解 这道题和之前Sabotage G的那道题类似,都是用二分答案求解(这道题还要简单一些,不需要用数学推导二分条件,只需简单判断一下即可). 同时为了降低复杂度,肯定不能用暴力求 ...
- Hounter
这题是概率与期望,不是很熟,所以冲了两篇题解才来写总结. 首先可以发现1猎人死的轮数是他之前死了的列人数加一. 那么题目转化为求先于一号猎人死的猎人数的期望值. 考虑这样一个事情,就是 ...
- Spring Dependency Injection浅析
Dependency Injection 依赖注入,在Spring框架负责创建Bean对象时,动态的将依赖对象注入到Bean组件. 1.在UserService中提供一个get/set的name方法, ...
- Haproxy搭建web集群
目录: 一.常见的web集群调度器 二.Haproxy应用分析 三.Haproxy调度算法原理 四.Haproxy特性 五.Haproxy搭建 Web 群集 一.常见的web集群调度器 目前常见的we ...
- [第九篇]——Docker 镜像使用之Spring Cloud直播商城 b2b2c电子商务技术总结
Docker 镜像使用 当运行容器时,使用的镜像如果在本地中不存在,docker 就会自动从 docker 镜像仓库中下载,默认是从 Docker Hub 公共镜像源下载. 下面我们来学习: 1.管理 ...