python之基本数据类型及深浅拷贝
一.数据基本类型之set集合
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key
set集合,是一个无序且不重复的元素集合
1.创建
s = set() #创建空集合
s = {'values1','values2'} #非空集合
2.转换
l = [1,2,5,11]
t = (11,22,12)
#元组转集合
st2 = set(t)
#列表转集合
st = set(l)
print(st)
print(st2)
3.常用支持操作
添加元素-->add(key)
s = set()
s.add()
print(s)
删除元素-->remove(key)
s = set([1,2,3])
s.remove(1)
print(s)
清除元素-->clear()
s = set([1,2,3,4,5])
print(s)
s.clear()
print(s)
比较元素-->difference()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#set1中有而set2中没有的值
ret = set1.difference(set2)
print(ret)
删除两集合中相同的元素-->difference_update()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#从set1中删除和set2中相同的元素
set1.difference_update(set2)
print(set1)
print(set2)
移除元素-->discard(values)
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#移除指定元素,不存在不会报错,remove()不存在会报错,建议discard
set1.discard(44)
print(set1)
取交集值-->intersection()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#取两个set集合的交集值
ret = set1.intersection(set2)
print(ret)
取交集并更新-->intersection_update()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#取交集并更新到set1中
set1.intersection_update(set2)
print(set1)
判断是否交集-->isdisjoint()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#如果两个集合有交集返回false,反之返回true
print(set1.isdisjoint(set2))
子序列-->issubset()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#判断是否是子集,是返回true,反之返回Flase
print(set1.issubset(set2))
父序列-->issuperset()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#是否是父序列,是返回True,反之返回Flase
print(set1.issuperset(set2))
对称交集-->symmetric_difference()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#对称交集,取两个集合中互不存在的元素,生成一个新的集合
ret = set1.symmetric_difference(set2)
print(ret)
对称交集并更新-->symmetric_difference_update()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#对称交集,并更新元素到set1中
set1.symmetric_difference_update(set2)
print(set1)
并集-->union()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#并集并更新到新的集合中
ret = set1.union(set2)
print(ret)
二.深浅拷贝
1.数字和字符串
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址
import copy
# ######### 数字、字符串 #########
n1 = 123
# n1 = "i am alex age 10"
print(id(n1))
# ## 赋值 ##
n2 = n1
print(id(n2))
# ## 浅拷贝 ##
n2 = copy.copy(n1)
print(id(n2)) # ## 深拷贝 ##
n3 = copy.deepcopy(n1)
print(id(n3))
二,其他数据类型
对于list dict,tuple 浅拷贝只拷贝最外一层,深拷贝除了最后一层(因最后一层是字符串)其余的都拷贝
- 赋值
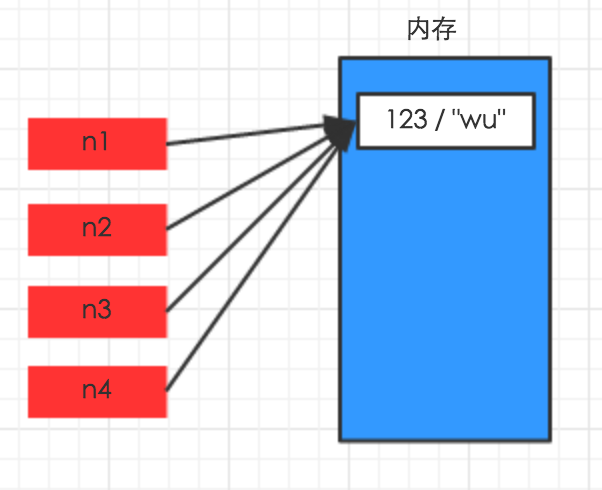
赋值,只是创建一个变量,该变量指向原来内存地址,如
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n2 = n1
解析图如下:
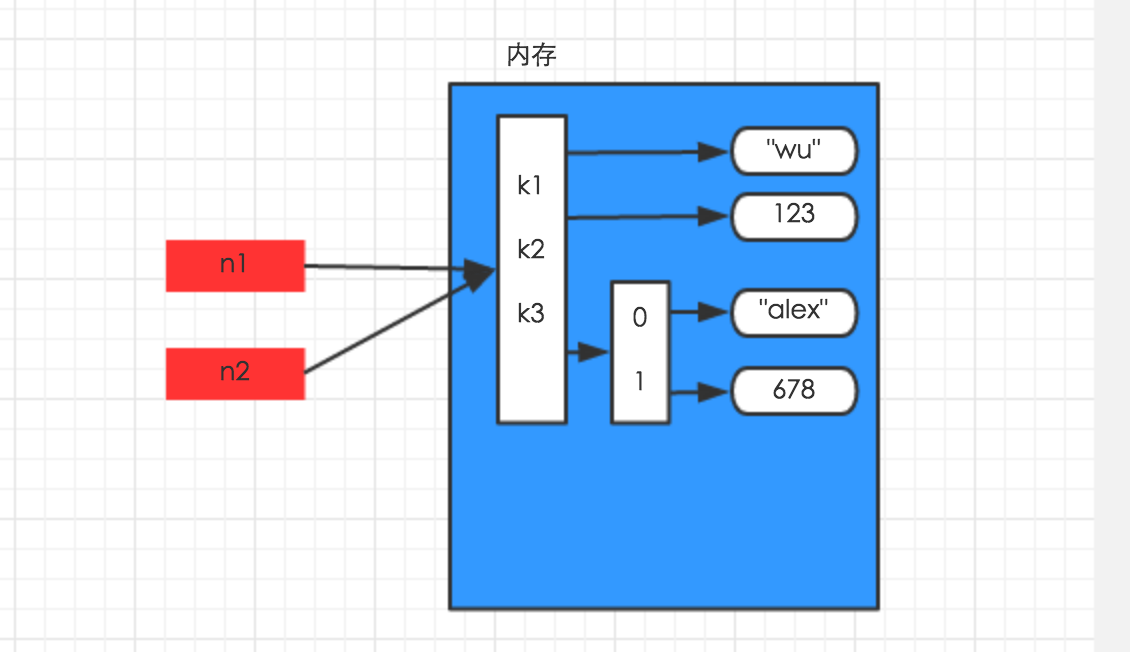
- 浅拷贝
浅拷贝,在内存中只额外创建第一层数据
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n3 = copy.copy(n1)
解析图如下:
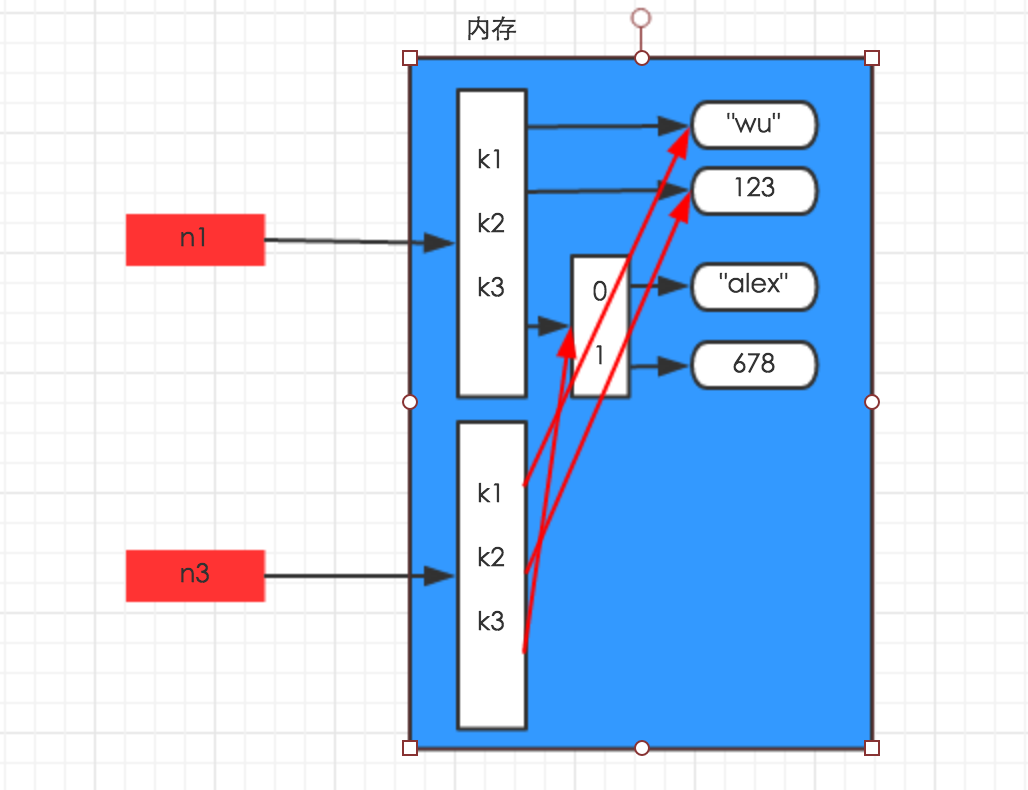
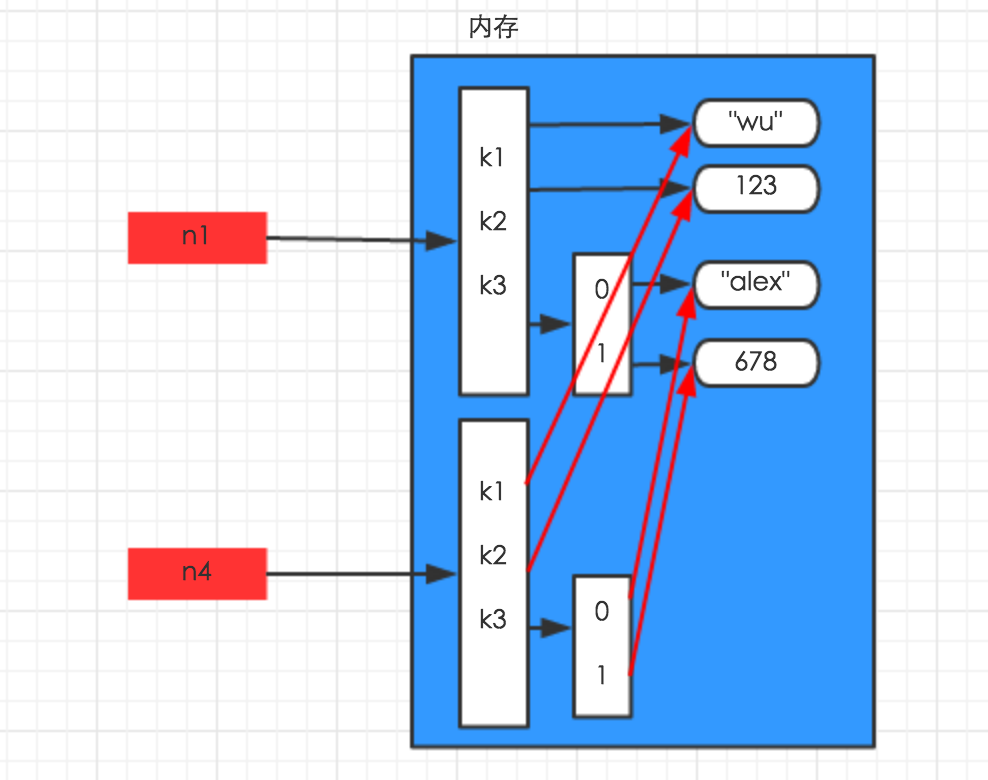
- 深拷贝:
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n4 = copy.deepcopy(n1)
解析图如下:
三.集合作业
1.寻找差异,并将new_dict的值更新到old_dict中
old_dict = {
"#1":11,
"#2":22,
"#3": 100
}
new_dict = {
"#1":33,
"#4":22,
"#7": 100
}
#!/usr/bin/env python
# -*- coding:utf-8 -*- old_dict = {
"#1":11,
"#2":22,
"#3": 100
} new_dict = {
"#1":33,
"#4":22,
"#7": 100
}
old_keys = old_dict.keys()
new_keys = new_dict.keys()
old_set = set(old_keys)
new_set = set(new_keys)
#old存在new不存在,并删除new中不存在,old 中存在的元素
del_set = old_set.difference(new_set)
for i in del_set:
del old_dict[i]
#new存在old不存在
add_set = new_set.difference(old_set)
for a in add_set:
old_dict[a] = new_dict[a]
#更新旧数据表
update_set = old_set.intersection(new_set)
for u in update_set:
old_dict[u] = new_dict[u]
print(old_dict)
python之基本数据类型及深浅拷贝的更多相关文章
- 巨蟒python全栈开发-第7天 基本数据类型补充&深浅拷贝
1.基本数据类型补充 2.深浅拷贝 DAY7-基本数据类型(基本数据类型补充&深浅拷贝) 本节主要内容: 1.补充基础数据类型 (1)join方法 (2)split方法 (3)列表不能在循环时 ...
- python基础(7)--深浅拷贝、函数
1.深浅拷贝 在Python中将一个变量的值传递给另外一个变量通常有三种:赋值.浅拷贝.深拷贝 Python数据类型可氛围基本数据类型包括整型.字符串.布尔及None等,还有一种由基本数据类型作为最基 ...
- Python 全栈开发十一 深浅拷贝
深浅拷贝 深浅拷贝的前提: 相等和相同的关系 深浅拷贝针对的是列表等可变的数据类型. 深浅拷贝在普通的列表没有什么意义,只有在嵌套列表,或其他嵌套数据类型才有意义. a = "aaa&quo ...
- python 学习笔记5(深浅拷贝与集合)
拷贝 我们已经详细了解了变量赋值的过程.对于复杂的数据结构来说,赋值就等于完全共享了资源,一个值的改变会完全被另一个值共享. 然而有的时候,我们偏偏需要将一份数据的原始内容保留一份,再去处理数据,这个 ...
- [Python笔记]第三篇:深浅拷贝、函数
本篇主要内容:深浅拷贝,自定义函数,三目运算,lambda表达式, 深浅拷贝 一.数字和字符串 对于 数字 和 字符串 而言,赋值.浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址. import ...
- python之set集合、深浅拷贝
一.基本数据类型补充 1,关于int和str在之前的学习中已经介绍了80%以上了,现在再补充一个字符串的基本操作: li = ['李嘉诚','何炅','海峰','刘嘉玲'] s = "_&q ...
- python之set集合及深浅拷贝
一.知识点补充 1.1字符串的基本操作 li =["李李嘉诚", "麻花藤", "⻩黄海海峰", "刘嘉玲"] s = ...
- 【python之路15】深浅拷贝及函数
一.集合数据类型(set):无序不重复的集合,交集.并集等功能 二.三元运算符 三.深浅拷贝 1)字符串和数字:深浅内存地址都一样 2)其他:浅拷贝:仅复制最外面第一层 深拷贝:除了最内层其他均拷贝 ...
- day7 基础数据类型&集合&深浅拷贝
基础数据类型汇总: #!/usr/bin/env python # -*- coding:utf-8 -*- ''' str int ''' # str s = ' a' print(s.isspac ...
随机推荐
- Gym 100342I Travel Agency (Tarjan)
题意读懂了就好做了,就是求一下点双连通分量.维护一下一颗子树的结点数,对于一个结点当u是割点的时候, 统计一下u分割的连通分量v,每得到一个连通分量的结点数cnt(v)和之前连通分量结点数sum相乘一 ...
- spring框架的总结
http://www.cnblogs.com/wangzn/p/6138062.html 大家好,相信Java高级工程师对spring框架都很了解吧!那么我以个人的观点总结一下spring,希望大家有 ...
- JS中的事件、事件冒泡和事件捕获、事件委托
https://www.cnblogs.com/diver-blogs/p/5649270.html https://www.cnblogs.com/Chen-XiaoJun/p/6210987.ht ...
- 搭建SSI开发框架原理
Spring2.5.Struts2.Ibatis开发框架搭建(一) ssi, ibatis 一.框架下载 1.1 Struts2框架 Struts2框架发展于WebWork,现在捐献给了Apach ...
- POI转换word doc文件为(html,xml,txt)
在POI中还存在有针对于word doc文件进行格式转换的功能.我们可以将word的内容转换为对应的Html文件,也可以把它转换为底层用来描述doc文档的xml文件,还可以把它转换为底层用来描述doc ...
- ★房贷计算器 APP
一.目的 1. 这是一个蛮有用的小工具 2. 之前看了很多demo,第一次来完全的自己实现一个APP 3. 完成之后提交 App Store 4. 作为Good Coder的提交审核材料 二.排期 周 ...
- 使用 ss 命令查看连接信息
作用:打印主机socket连接信息,netstate可以做的它都可以做,比netstate 更灵活,而且由于ss使用 tcp_diag 内核模块,所以速度更快. 用法: ss [ OPTIONS ] ...
- (5)zabbix配置详解
zabbix配置介绍 zabbix配置内容比较多,我们要分为9大块来讲解.分别如下:1.主机与组不用多数,顾名思义,他是添加主机配置与组配置. 2.监控项需要监控的项目,例如服务器负载可以使一个监控项 ...
- log4j日志输出到文件的配置
1.Maven的dependency 2.log4j.properties的配置 3.Junit的Test类 4.web.xml的配置(非必要) 5.spring的db.config的配置(非必要) ...
- Python-小游戏题目
猜年龄游戏 n = 0 rayn_age = 19 a = {0:'666',1:'777',2:'888'} while n <3: age = input('请输入你的年龄:') age = ...