python之基本数据类型及深浅拷贝
一.数据基本类型之set集合
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key
set集合,是一个无序且不重复的元素集合
1.创建
s = set() #创建空集合
s = {'values1','values2'} #非空集合
2.转换
l = [1,2,5,11]
t = (11,22,12)
#元组转集合
st2 = set(t)
#列表转集合
st = set(l)
print(st)
print(st2)
3.常用支持操作
添加元素-->add(key)
s = set()
s.add()
print(s)
删除元素-->remove(key)
s = set([1,2,3])
s.remove(1)
print(s)
清除元素-->clear()
s = set([1,2,3,4,5])
print(s)
s.clear()
print(s)
比较元素-->difference()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#set1中有而set2中没有的值
ret = set1.difference(set2)
print(ret)
删除两集合中相同的元素-->difference_update()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#从set1中删除和set2中相同的元素
set1.difference_update(set2)
print(set1)
print(set2)
移除元素-->discard(values)
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#移除指定元素,不存在不会报错,remove()不存在会报错,建议discard
set1.discard(44)
print(set1)
取交集值-->intersection()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#取两个set集合的交集值
ret = set1.intersection(set2)
print(ret)
取交集并更新-->intersection_update()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#取交集并更新到set1中
set1.intersection_update(set2)
print(set1)
判断是否交集-->isdisjoint()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#如果两个集合有交集返回false,反之返回true
print(set1.isdisjoint(set2))
子序列-->issubset()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#判断是否是子集,是返回true,反之返回Flase
print(set1.issubset(set2))
父序列-->issuperset()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#是否是父序列,是返回True,反之返回Flase
print(set1.issuperset(set2))
对称交集-->symmetric_difference()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#对称交集,取两个集合中互不存在的元素,生成一个新的集合
ret = set1.symmetric_difference(set2)
print(ret)
对称交集并更新-->symmetric_difference_update()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#对称交集,并更新元素到set1中
set1.symmetric_difference_update(set2)
print(set1)
并集-->union()
set1 = {1,44,87,23,55}
set2 = {1,44,88,23,67}
#并集并更新到新的集合中
ret = set1.union(set2)
print(ret)
二.深浅拷贝
1.数字和字符串
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址
import copy
# ######### 数字、字符串 #########
n1 = 123
# n1 = "i am alex age 10"
print(id(n1))
# ## 赋值 ##
n2 = n1
print(id(n2))
# ## 浅拷贝 ##
n2 = copy.copy(n1)
print(id(n2)) # ## 深拷贝 ##
n3 = copy.deepcopy(n1)
print(id(n3))
二,其他数据类型
对于list dict,tuple 浅拷贝只拷贝最外一层,深拷贝除了最后一层(因最后一层是字符串)其余的都拷贝
- 赋值
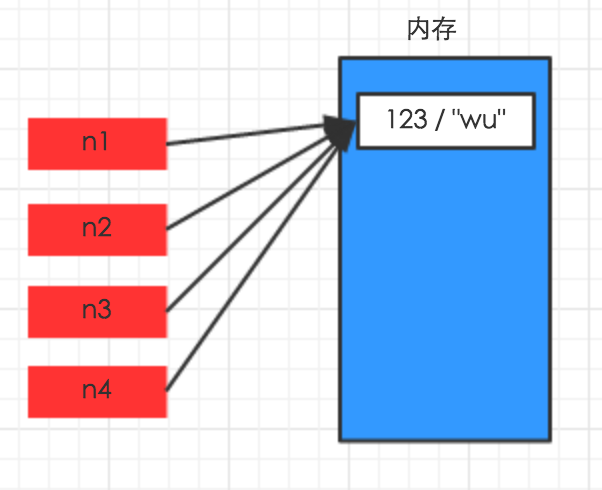
赋值,只是创建一个变量,该变量指向原来内存地址,如
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n2 = n1
解析图如下:
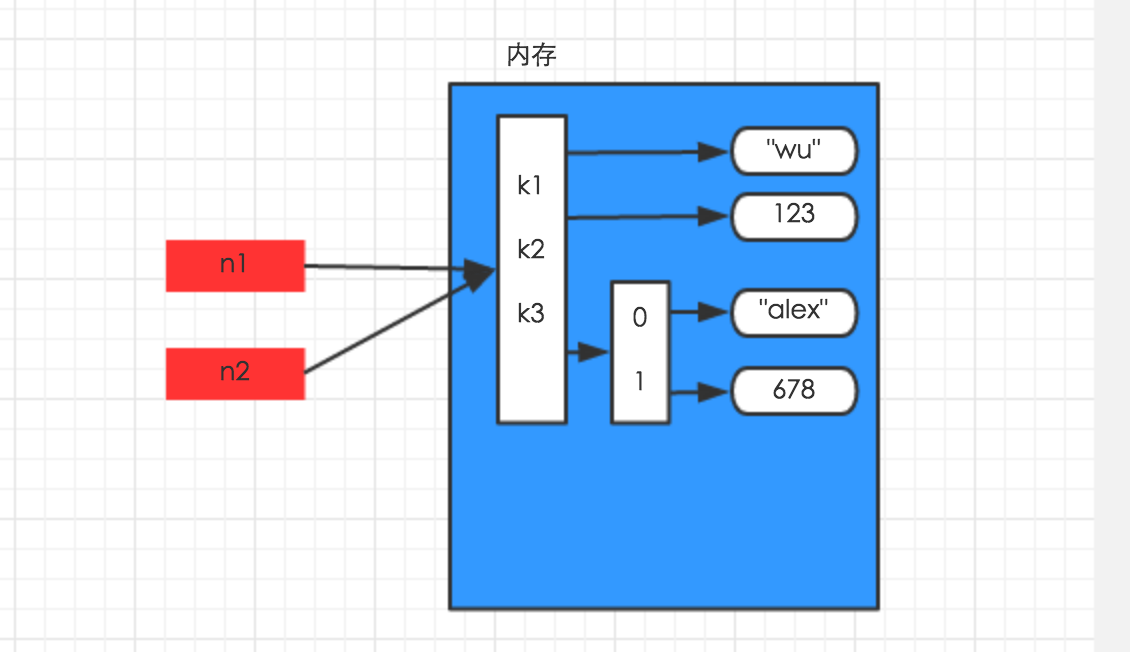
- 浅拷贝
浅拷贝,在内存中只额外创建第一层数据
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n3 = copy.copy(n1)
解析图如下:
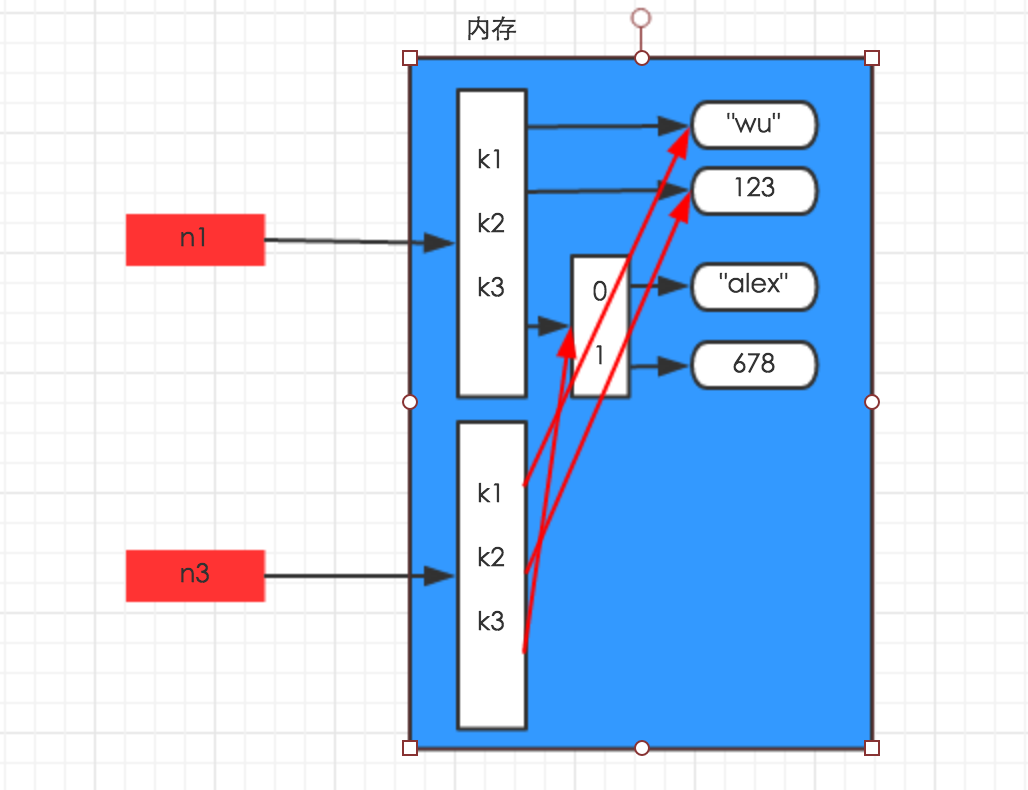
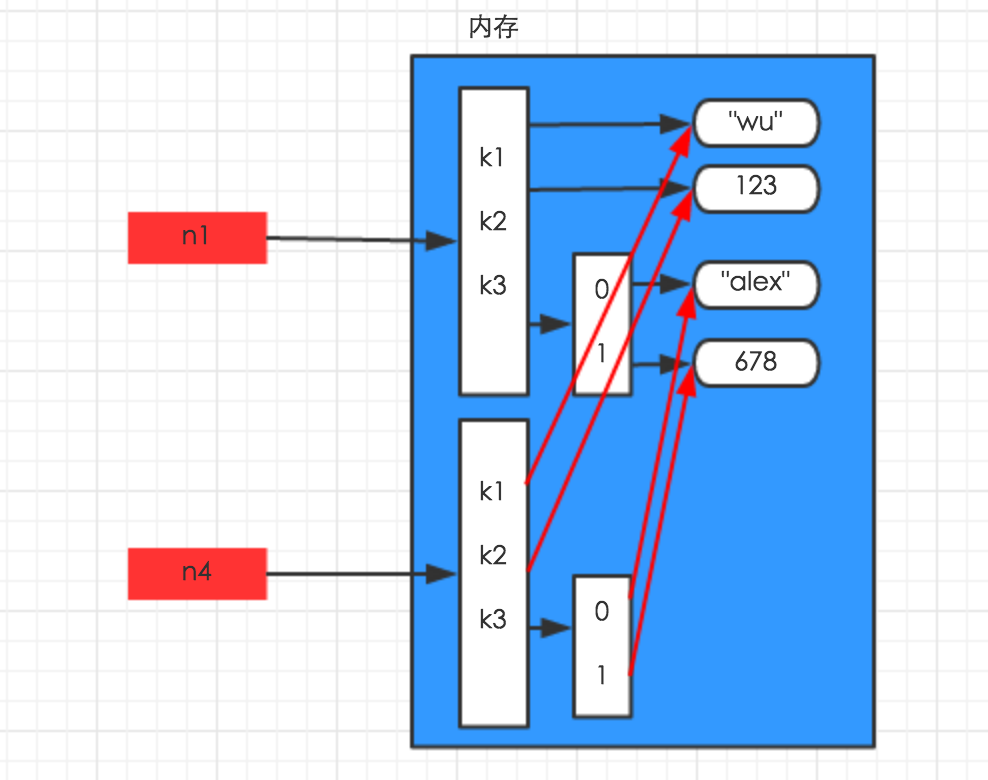
- 深拷贝:
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}
n4 = copy.deepcopy(n1)
解析图如下:
三.集合作业
1.寻找差异,并将new_dict的值更新到old_dict中
old_dict = {
"#1":11,
"#2":22,
"#3": 100
}
new_dict = {
"#1":33,
"#4":22,
"#7": 100
}
#!/usr/bin/env python
# -*- coding:utf-8 -*- old_dict = {
"#1":11,
"#2":22,
"#3": 100
} new_dict = {
"#1":33,
"#4":22,
"#7": 100
}
old_keys = old_dict.keys()
new_keys = new_dict.keys()
old_set = set(old_keys)
new_set = set(new_keys)
#old存在new不存在,并删除new中不存在,old 中存在的元素
del_set = old_set.difference(new_set)
for i in del_set:
del old_dict[i]
#new存在old不存在
add_set = new_set.difference(old_set)
for a in add_set:
old_dict[a] = new_dict[a]
#更新旧数据表
update_set = old_set.intersection(new_set)
for u in update_set:
old_dict[u] = new_dict[u]
print(old_dict)
python之基本数据类型及深浅拷贝的更多相关文章
- 巨蟒python全栈开发-第7天 基本数据类型补充&深浅拷贝
1.基本数据类型补充 2.深浅拷贝 DAY7-基本数据类型(基本数据类型补充&深浅拷贝) 本节主要内容: 1.补充基础数据类型 (1)join方法 (2)split方法 (3)列表不能在循环时 ...
- python基础(7)--深浅拷贝、函数
1.深浅拷贝 在Python中将一个变量的值传递给另外一个变量通常有三种:赋值.浅拷贝.深拷贝 Python数据类型可氛围基本数据类型包括整型.字符串.布尔及None等,还有一种由基本数据类型作为最基 ...
- Python 全栈开发十一 深浅拷贝
深浅拷贝 深浅拷贝的前提: 相等和相同的关系 深浅拷贝针对的是列表等可变的数据类型. 深浅拷贝在普通的列表没有什么意义,只有在嵌套列表,或其他嵌套数据类型才有意义. a = "aaa&quo ...
- python 学习笔记5(深浅拷贝与集合)
拷贝 我们已经详细了解了变量赋值的过程.对于复杂的数据结构来说,赋值就等于完全共享了资源,一个值的改变会完全被另一个值共享. 然而有的时候,我们偏偏需要将一份数据的原始内容保留一份,再去处理数据,这个 ...
- [Python笔记]第三篇:深浅拷贝、函数
本篇主要内容:深浅拷贝,自定义函数,三目运算,lambda表达式, 深浅拷贝 一.数字和字符串 对于 数字 和 字符串 而言,赋值.浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址. import ...
- python之set集合、深浅拷贝
一.基本数据类型补充 1,关于int和str在之前的学习中已经介绍了80%以上了,现在再补充一个字符串的基本操作: li = ['李嘉诚','何炅','海峰','刘嘉玲'] s = "_&q ...
- python之set集合及深浅拷贝
一.知识点补充 1.1字符串的基本操作 li =["李李嘉诚", "麻花藤", "⻩黄海海峰", "刘嘉玲"] s = ...
- 【python之路15】深浅拷贝及函数
一.集合数据类型(set):无序不重复的集合,交集.并集等功能 二.三元运算符 三.深浅拷贝 1)字符串和数字:深浅内存地址都一样 2)其他:浅拷贝:仅复制最外面第一层 深拷贝:除了最内层其他均拷贝 ...
- day7 基础数据类型&集合&深浅拷贝
基础数据类型汇总: #!/usr/bin/env python # -*- coding:utf-8 -*- ''' str int ''' # str s = ' a' print(s.isspac ...
随机推荐
- mybatis 原理研究
1. mybatis 是使用JDBC来实现的, 所以需要我们首先了解JDBC 的查询 ①加载JDBC驱动 ②建立并获取数据库连接 ③设置sql语句的传递参数 ④执行sql语句并获得结果 ⑤对结果进行转 ...
- 产生式模型(生成式模型)与判别式模型<转载>
转自http://dongzipnf.blog.sohu.com/189983746.html 产生式模型与判别式模型 产生式模型(Generative Model)与判别式模型(Discrimiti ...
- roi_pooling层
roi_pooling层先把rpn生成的roi映射到特征提取层最后一层,然后再分成7*7个bin进行池化 下面是roi_pooling层的映射到特征提取层的代码,可以看到用的是round函数,也就是说 ...
- ES6新增Map、Set和iterable
Map需要一个二维数组 var test_map = new Map(["mians",99],["regink",88]) test_map.get(&quo ...
- QT+常用控件_Line Edit
#include "mainwindow.h" #include "ui_mainwindow.h" #include <QDebug> #incl ...
- python基础面试题整理---从零开始 每天十题(04)
一.Q:如何用Python来进行查询和替换一个文本字符串? A:可以使用sub()方法来进行查询和替换,sub方法的格式为:sub(replacement, string[, count=0]) re ...
- iOS 面试集锦
是第一篇: 1.Difference between shallow copy and deep copy? 浅复制和深复制的区别? 答案:浅层复制:只复制指向对象的指针,而不复制引用对象本身. 深层 ...
- Mac电脑怎么显示隐藏文件、xcode清除缓存
1.删除Xcode中多余的证书provisioning profile 手动删除: Xcode6 provisioning profile path: ~/Library/MobileDevice/P ...
- python 连接redis cluster
#!/usr/bin/env python # encoding: utf-8 #@author: 东哥加油! #@file: clear_pool.py #@time: 2018/8/28 17:0 ...
- mysql 导入数据库
1:创建数据库 dos 进入 xxx\MySQL5.7\bin 目录(很多人喜欢把这个路径配置在环境变量path中,这样在dos敲命令时,就直接是mysql......) mysql -uroot - ...