*lucene索引_的删除和更新
【删除】

【恢复删除】

【强制删除】

【优化和合并】

【更新索引】
附:
代码:
IndexUtil.java:
package cn.hk.index; import java.io.File;
import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.StaleReaderException;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.util.Version; public class IndexUtil {
private String[] ids = {"1","2","3","4","5","6"};
private String[] emails = {"aa@hk.arg","bb@hk.org","cc@hk.arg",
"dd@hk.org","ee@hk.org","ff@hk.org"};
private String[] content = {
"welcome to visited the space","hello boy","my name is aa","i like football",
"I like football and I like Basketball too","I like movie and swim"
};
private int[] attachs = {2,3,1,4,5,5};
private String[] names = {"zhangsan","lisi","john","mike","jetty","jake"}; private Directory directory = null; public IndexUtil(){
try {
directory = FSDirectory.open(new File("d://lucene/index02"));
} catch (IOException e) {
e.printStackTrace();
}
} public void update(){
IndexWriter writer =null;
try {
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_35,new StandardAnalyzer(Version.LUCENE_35)));
/*
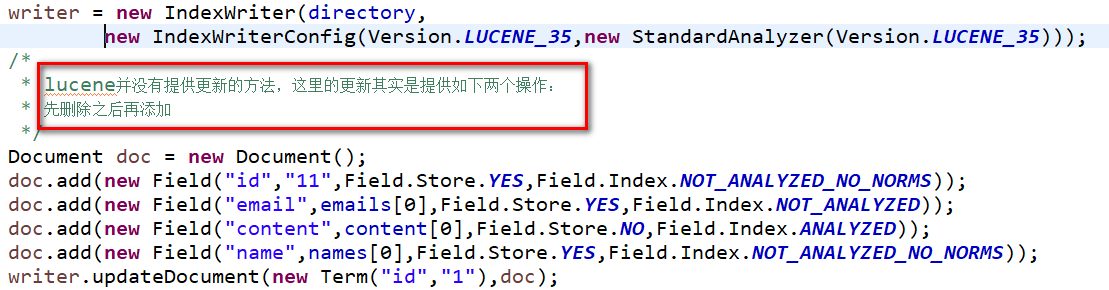
* lucene并没有提供更新的方法,这里的更新其实是提供如下两个操作:
* 先删除之后再添加
*/
Document doc = new Document();
doc.add(new Field("id","11",Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field("email",emails[0],Field.Store.YES,Field.Index.NOT_ANALYZED));
doc.add(new Field("content",content[0],Field.Store.NO,Field.Index.ANALYZED));
doc.add(new Field("name",names[0],Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
writer.updateDocument(new Term("id","1"),doc);
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
if(writer != null)
try {
writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} } public void merge(){
IndexWriter writer = null;
try {
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35)));
//会将索引合并为2段,这两段中的被删除的数据会被清空
//特别注意:此处在lucene3.5后不建议使用,因为会消耗大量的开销,
//lucene会根据情况自动处理的
writer.forceMerge(2);
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
if(writer != null)
try {
writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
} public void forceDelete(){
IndexWriter writer = null;
try {
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_35,new StandardAnalyzer(Version.LUCENE_35)));
writer.forceMergeDeletes();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
if(writer != null)
try {
writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
} public void undelete(){
//使用IndexReader进行恢复
try {
IndexReader reader = IndexReader.open(directory,false);
//回复时,必须把IndexReader的只读(readyonly)设置为FALSE
reader.undeleteAll();
reader.close();
} catch (StaleReaderException e) { e.printStackTrace();
} catch (CorruptIndexException e) { e.printStackTrace();
} catch (LockObtainFailedException e) { e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} public void delete(){
IndexWriter writer = null;
try {
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35)));
//删除ID为1的文档
//参数可以是一个选项,可以是一个Query,也可以是一个Term,Term是一个精确查找的值
//此时删除的文档并不会被完全删除,而是存储在回收站中的,可以恢复
writer.deleteDocuments(new Term("id","1"));
} catch (CorruptIndexException e) { e.printStackTrace();
} catch (LockObtainFailedException e) { e.printStackTrace();
} catch (IOException e) { e.printStackTrace();
}finally{
if(writer != null)
try {
writer.close();
} catch (CorruptIndexException e) { e.printStackTrace();
} catch (IOException e) { e.printStackTrace();
}
}
} public void query(){
try {
IndexReader reader = IndexReader.open(directory);
//通过reader可以获取文档的数量
System.out.println("numDocs:" + reader.numDocs());
System.out.println("maxDocs" + reader.maxDoc());
System.out.println("deleteDocs:" + reader.numDeletedDocs());
reader.close();
} catch (CorruptIndexException e) { e.printStackTrace();
} catch (IOException e) { e.printStackTrace();
}
} public void index(){
IndexWriter writer = null;
try {
writer = new IndexWriter(directory,new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35)));
Document doc = null;
for(int i=0;i<ids.length;i++){
doc = new Document();
doc.add(new Field("id",ids[i],Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field("email",emails[i],Field.Store.YES,Field.Index.NOT_ANALYZED));
doc.add(new Field("content",content[i],Field.Store.NO,Field.Index.ANALYZED));
doc.add(new Field("name",names[i],Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
writer.addDocument(doc);
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
if(writer != null)
try {
writer.close();
} catch (CorruptIndexException e) { e.printStackTrace();
} catch (IOException e) { e.printStackTrace();
} }
} }
TestIndex.java:
package cn.hk.test;
import org.junit.Test;
import cn.hk.index.IndexUtil;
public class TestIndex {
@Test
public void testIndex(){
IndexUtil iu = new IndexUtil();
iu.index();
}
@Test
public void testQuery(){
IndexUtil iu = new IndexUtil();
iu.query();
}
@Test
public void testDelete(){
IndexUtil iu = new IndexUtil();
iu.delete();
}
@Test
public void testUnDelete(){
IndexUtil iu = new IndexUtil();
iu.undelete();
}
@Test
public void testForceDelete(){
IndexUtil iu = new IndexUtil();
iu.forceDelete();
}
public void testMerge(){
IndexUtil iu = new IndexUtil();
iu.merge();
}
@Test
public void testUpdate(){
IndexUtil iu = new IndexUtil();
iu.update();
}
}


*lucene索引_的删除和更新的更多相关文章
- *lucene索引_创建_域选项
[索引建立步骤] [创建Directory] [创建writer] [创建文档并添加索引] 文档和域的概念很重要 文档相当于表中的每一条记录,域相当于表中的每一个字段. [查询索引的基本信息] 使用I ...
- Lucene系列五:Lucene索引详解(IndexWriter详解、Document详解、索引更新)
一.IndexWriter详解 问题1:索引创建过程完成什么事? 分词.存储到反向索引中 1. 回顾Lucene架构图: 介绍我们编写的应用程序要完成数据的收集,再将数据以document的形式用lu ...
- Lucene——索引的创建、删除、修改
package cn.tz.lucene; import java.io.File; import java.util.ArrayList; import java.util.List; import ...
- Lucene索引维护(添加、修改、删除)
1. Field域属性分类 添加文档的时候,我们文档当中包含多个域,那么域的类型是我们自定义的,上个案例使用的TextField域,那么这个域他会自动分词,然后存储 我们要根据数 ...
- Lucene——索引过程分析Index
Lucene索引过程分为3个主要操作步骤:将原始文档转换成文本.分析文本.将分析好的文本保存至索引中 一.提取文本和创建文档 从 pdf.word等非纯文本格式文件中,提取文本格式信息.建立起对应的, ...
- 【手把手教你全文检索】Lucene索引的【增、删、改、查】
前言 搞检索的,应该多少都会了解Lucene一些,它开源而且简单上手,官方API足够编写些小DEMO.并且根据倒排索引,实现快速检索.本文就简单的实现增量添加索引,删除索引,通过关键字查询,以及更新索 ...
- 理解Lucene索引与搜索过程中的核心类
理解索引过程中的核心类 执行简单索引的时候需要用的类有: IndexWriter.Directory.Analyzer.Document.Field 1.IndexWriter IndexWr ...
- lucene索引
一.lucene索引 1.文档层次结构 索引(Index):一个索引放在一个文件夹中: 段(Segment):一个索引中可以有很多段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一 ...
- Lucene 索引功能
Lucene 数据建模 基本概念 文档(doc): 文档是 Lucene 索引和搜索的原子单元,文档是一个包含多个域的容器. 域(field): 域包含“真正的”被搜索的内容,每一个域都有一个标识名称 ...
随机推荐
- 数论/暴力 Codeforces Round #305 (Div. 2) C. Mike and Frog
题目传送门 /* 数论/暴力:找出第一次到a1,a2的次数,再找到完整周期p1,p2,然后以2*m为范围 t1,t2为各自起点开始“赛跑”,谁落后谁加一个周期,等到t1 == t2结束 详细解释:ht ...
- 用IARIdePm新建STM8工程步骤
IARdePm 如何新建工程及其调用库函数1.新建文件夹,例如,新建文件夹名字(不能为中文)为:Lib_test_GPIO_OUT2.新建工程,Create New Project...,选择Empt ...
- Oozie的架构
Oozie的架构图,如下: 从oozie的架构图中,可以看到所有的任务都是通过oozie生成相应的任务客户端,并通过任务客户端来提交相应的任务. 继续...
- nginx 80端口重定向到443端口
server { listen ; server_name www.域名.com; rewrite ^(.*)$ https://${server_name}$1 permanent; } serve ...
- AJPFX关于读取properties 配置文件 返回属性值
:Properties的概述 * Properties 类表示了一个持久的属性集. * Properties 可保存在流中或从流中加载. * 属性列表中每个键 ...
- Cocos工作两周感受
我是一个专注搞Unity开发的程序猿哈哈,但是最近的项目要采用Cocos引擎开发.在迷茫和学习成长中已经不知不觉过了两周.我就简单谈谈我这两周学习Cocos的一个感受. 具体说公司是采用js语言来开发 ...
- 边框圆角值的问题、white-space、word-wrap、margin对布局的影响
1.边框圆角(border-radius)值的问题 border-radius : 7px 7px 7px 0; 四个值的顺序是左上.右上.右下.左下 2.white-space 规定段落中的文本不换 ...
- MongoDB部署、使用、监控及调优
MongoDB部署 系统环境:CentOS7 下载地址:http://mirrors.163.com/centos/7.6.1810/isos/x86_64/CentOS-7-x86_64-DVD ...
- (转)关于IC设计的想法 Author :Fengzhepianzhou
一.工具的使用 工欲善其事,必先利其器.我们做IC设计的需要掌握的工具:仿真(vcs.modelsim),综合工具(dc.QS.ISE),时序分析(pt.其他的).以及后端的一些工具,比如astro. ...
- C#创建任务计划
因写的调用DiskPart程序是要用管理员身份运行的,这样每次开机检查都弹个框出来确认肯定不行.搜了下,似乎也只是使用任务计划程序运行来绕过UAC提升权限比较靠谱,网上的都是添加到计算机启动的,不是指 ...