后缀数组 (Suffix Array) 学习笔记
\(\\\)
定义
介绍一些写法和数组的含义,首先要知道 字典序 。
\(len\):字符串长度
\(s\):字符串数组,我们的字符串存储在 \(s[0]...s[len-1]\) 中。
\(suffix(i) ,i\in[0,len-1]\): 表示子串 \(s[i]...s[len-1]\),即从 \(i\) 开始的后缀 。
加入我们提取出了 \(suffix(1)...suffix(len-1)\) ,将他们按照字典序从小到达排序。
- \(sa[i]\) :排名为 \(i\) 的后缀的第一个字符在原串里的位置 。
- \(rank[i]\) :\(suffix(i)\) 的排名。
显然这两个数组可以在 \(O(N)\) 的时间内互相推出。
\(\\\)
Doubling Algorithm
由于博主太蒟并不会DC3,想看DC3的同志们可以溜了
\(\\\)
倍增构造法。
从小到大枚举 \(k\) ,每次按照字典序排序,每一个后缀的长度为 \(2^k\) 的前缀,直到没有相同排名的为止。
若有的后缀不够长就在后面补上:比当前串全字符集最小字符还要小的字符,结果显然符合字典序的定义。
\(\\\)
如何确定长度为 \(2^k\) 的每一个后缀对应前缀的排名?
倍增。有点像数学归纳法的感觉。
首先我们显然可以直接求出来 \(k=0\) 的答案。
然后对于一个 \(k\) ,我们显然已经完成了 \(k-1\) 部分的工作。
所以对于一个长度为 \(2^k\) 的前缀,它显然可以由两个长度为 \(2^{k-1}\) 的前缀拼成。
也就是说,我们可以把长度为 \(2^k\) 的前缀,写成两个长度为 \(2^{k-1}\) 的前缀的有序二元组。
有一个显然的结论,因为长度 \(2^{k-1}\) 的所有前缀有序,所以我们对这些二元组排序法则可以写成:
以前一个长度为 \(2^{k-1}\) 的前缀的 \(rank\) 为第一关键字,以后一个长度为 \(2^{k-1}\) 的前缀的 \(rank\) 为第二关键字排序。
对于此方法得到的顺序,与将整个长度为 \(2^k\) 的前缀字典序排序得到的顺序,想一想发现是相同的,因为它符合字典序定义。
\(\\\)
比较到什么时候为止?显然是求到一个 \(k\),使得每一个后缀 \(rank\) 不同时。
\(\\\)
附上 \(2009\) 年国家集训队论文中的排序图片,可以加深体会一下整个排序的思想。
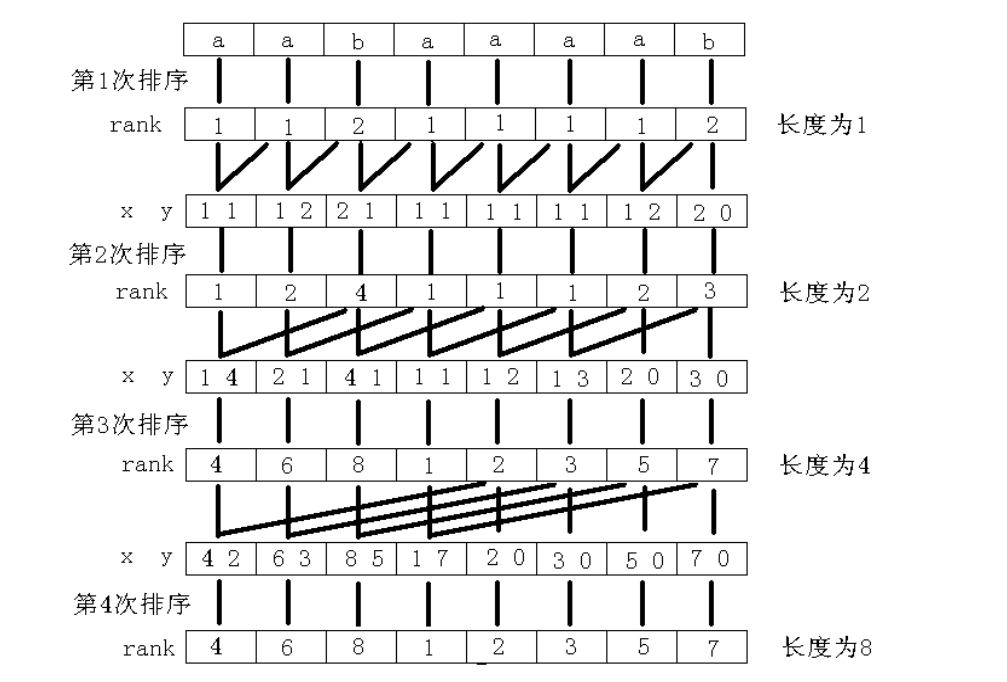
\(\\\)
代码实现
下面重点说一下代码实现,算法的精华也就体现在这里。附上一个写的不错的博客 。
\(\\\)
再次声明一些数组的定义:
\(sa[i]\) :排名为 \(i\) 的后缀第一个字符在字符串内的位置,注意字符串数组是从 \(0\) 开始存储的。
需要注意的是,在倍增过程中 \(sa[i]\) 只表示对每一个后缀的长度为 \(2^k\) 的前缀排序的结果。
同时需要注意的是,在 \(rank\) 相同时我们按照第一个字符在字符串出现的位置从小到大排序。
\(x[i]\) :上面的 \(rank[i]\) 我们在这里写作 \(x[i]\) ,含义还是 \(suffix(i)\) 的排名。
同理,在倍增过程中,\(x[i]\) 只表示每一个后缀的长度为 \(2^k\) 的前缀的排名,两个位置的 \(x\) 可以相同。
\(y[i]\) :排序时的辅助数组,代表二元组的第二个元素排序的结果。
其中 \(y[i]\) 表示 排名为 \(i\) 的第二个长度为 \(2^{k-1}\) 的前缀,对应整个前缀的开头位置 。
注意,此时下标表示名次,值代表第二关键字的首字符位置,与 \(x\) 数组的定义为逆运算。
\(cnt[i]\) :计数器数组,用于基数排序。
\(\\\)
第一步,将长度为 \(1\) 的每一个字符排序。
这个过程就是基数排序。过程中的 \(n\) 表示数组长度,\(m\) 表示原串字符集范围为 \([1,m-1]\) 。
注意体会最后一行的倒序循环,此时体现了 \(rank\) 相同时按照第一个字符在字符串出现的位置排序的原则。
for(R int i=0;i<n;++i) ++cnt[x[i]=s[i]];
for(R int i=1;i<m;++i) cnt[i]+=cnt[i-1];
for(R int i=n-1;~i;--i) sa[--cnt[x[i]]]=i;
\(\\\)
然后我们就要开始倍增构造,设 \(k\) 直接表示当前考虑的前缀长度。
for(R int k=1,p=0;k<=n;k<<=1)
\(\\\)
首先看本次排序构造的 \(y[i]\) 。
由于 \(sa\) 数组是有序的,所以我们没必要对 \(y[i]\) 数组进行一次基数排序。
p=0;
for(R int i=n-k;i<n;++i) y[p++]=i;
for(R int i=0;i<n;++i) if(sa[i]>=k) y[p++]=sa[i]-k;
第二行的含义是,因为字符串的后 \(k\) 个后缀一定不能再找到长度为 \(k\) 的后缀继续拼接了。
根据字典序的定义,空串字典序优于任何一个字符串,所以他们的 \(y\) 应该最靠前。
同时因为 \(rank\) 相同时按照第一个字符在字符串出现的位置排序的原则,循环是正序。
第三行的含义是,如果一个长度为 \(k\) 的前缀起始位置 \(\le k\) ,那它必然作为一个后一段接在前面的某一个位置上。
可以注意到的是, \(sa\) 数组和 \(y\) 数组的定义形式是一致的,也就是说, 我们按照 \(sa\) 的顺序构造 \(y\) 没有问题。
\(\\\)
然后就要构造 \(sa[i]\) 。这也是构造过程中最精华的一部分。
for(R int i=0;i<m;++i) cnt[i]=0;
for(R int i=0;i<n;++i) ++cnt[x[y[i]]];
for(R int i=1;i<m;++i) cnt[i]+=cnt[i-1];
for(R int i=n-1;~i;--i) sa[--cnt[x[y[i]]]]=y[i];
这其实是一个双关键字基数排序的过程。
双关键字基数排序时,我们需要先将第二关键字直接排序,然后再使用上面的代码。
现在 \(y[i]\) 显然已经是有序的了。
这个过程的理解可以参考最开始的单关键字基数排序。
为什么那时我们做到了在 \(rank\) 相同时我们按照第一个字符在字符串出现的位置从小到大排序的要求?
因为我们是倒着扫描的。
同理,为了让 \(x\) 相同的 \(y\) 越劣的越靠后,我们直接倒着扫描 \(y\) 不就可以了吗!
此时我们成功在 \(sa\) 数组内完成了第一第二关键字合并后的排序。
\(\\\)
然后要做的就是还原 \(rank\) 数组了。
注意 \(rank\) 数组的定义中可以有相同的排名,所以第一第二关键字 \(rank\) 相同的注意要特殊对待。
inline bool cmp(int *a,int x,int y,int k){return a[x]==a[y]&&a[x+k]==a[y+k];}
swap(x,y); p=1; x[sa[0]]=0;
for(R int i=1;i<n;++i) x[sa[i]]=cmp(y,sa[i-1],sa[i],k)?p-1:p++;
注意这个指针交换的过程,它优化掉了 \(swap\) 两个数组的复杂度。
因为 \(x\) 数组是上一个 \(k\) 的 \(rank\) 结果,所以可以直接比对新的即将拼合的两段是否相同。
\(\\\)
最后还有一个小优化。
if(p>=n) break;
m=p;
就是 \(p=n\) 时,可以发现当前长度的前缀已经具有了区分每一个后缀的作用,所以我们没必要继续比下去了。
同时,上一次不同 \(rank\) 的个数显然是下一次基数排序的字符集大小。
\(\\\)
最后再多说一句,值得注意的是,不管是哪种实现方式,除了空字符外 \(rank\) 必须从 1 开始,否则会造成最小字符与空字符运行时混淆。
\(\\\)
一道例题
给出一个字符串,写出其所有循环同构串,将其按字典序从小大排序,输出排序后每一个串的尾字符。
\(\\\)
环的问题一般可以破环成链去搞。
拆开之后复制一倍接在后面,直接跑后缀数组,按 \(sa\) 顺序输出所有长度大于 \(len\) 的后缀对应答案。
\(\\\)
#include<cmath>
#include<cstdio>
#include<cctype>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
#define N 200005
#define R register
using namespace std;
char ss[N];
int s[N],sa[N],cnt[N],t1[N],t2[N];
void da(int n,int m){
int *x=t1,*y=t2;
s[n++]=0;
for(R int i=0;i<n;++i) ++cnt[x[i]=s[i]];
for(R int i=1;i<m;++i) cnt[i]+=cnt[i-1];
for(R int i=n-1;~i;--i) sa[--cnt[x[i]]]=i;
for(R int k=1,p=0;k<n&&p<n;k<<=1,m=p,p=0){
for(R int i=n-k;i<n;++i) y[p++]=i;
for(R int i=0;i<n;++i) if(sa[i]>=k) y[p++]=sa[i]-k;
for(R int i=0;i<m;++i) cnt[i]=0;
for(R int i=0;i<n;++i) ++cnt[x[y[i]]];
for(R int i=1;i<m;++i) cnt[i]+=cnt[i-1];
for(R int i=n-1;~i;--i) sa[--cnt[x[y[i]]]]=y[i];
swap(x,y); p=1; x[sa[0]]=0;
for(R int i=1;i<n;++i)
if(y[sa[i-1]]==y[sa[i]]&&y[sa[i-1]+k]==y[sa[i]+k]) x[sa[i]]=p-1;
else x[sa[i]]=p++;
}
--n;
for(R int i=0;i<n;++i) sa[i]=sa[i+1];
}
int main(){
scanf("%s",ss);
int n=strlen(ss);
for(R int i=0;i<n;++i) s[i]=ss[i];
for(R int i=0;i<n-1;++i) s[n+i]=s[i];
da((n<<1)-1,256);
for(R int i=0;i<(n<<1)-1;++i) if(sa[i]<n) putchar(s[sa[i]+n-1]);
return 0;
}
后缀数组 (Suffix Array) 学习笔记的更多相关文章
- 后缀数组(suffix array)
参考: Suffix array - Wiki 后缀数组(suffix array)详解 6.3 Suffix Arrays - 算法红宝书 Suffix Array 后缀数组 基本概念 应用:字 ...
- 后缀数组(suffix array)详解
写在前面 在字符串处理当中,后缀树和后缀数组都是非常有力的工具. 其中后缀树大家了解得比较多,关于后缀数组则很少见于国内的资料. 其实后缀数组是后缀树的一个非常精巧的替代品,它比后缀树容易编程实现, ...
- 利用后缀数组(suffix array)求最长公共子串(longest common substring)
摘要:本文讨论了最长公共子串的的相关算法的时间复杂度,然后在后缀数组的基础上提出了一个时间复杂度为o(n^2*logn),空间复杂度为o(n)的算法.该算法虽然不及动态规划和后缀树算法的复杂度低,但其 ...
- 数据结构之后缀数组suffix array
在字符串处理当中,后缀树和后缀数组都是非常有力的工具,其中后缀树大家了解得比较多,关于后缀数组则很少见于国内的资料.其实后缀是后缀树的一个非常精巧的替代品,它比后缀树容易编程实现,能够实现后缀树的很多 ...
- 后缀数组suffix array
倍增算法,时间复杂度O(nlogn) sa从小到大保存相对大小的下标 理解LSD,x数组,sa数组 char s[maxn]; int sa[maxn],t[maxn],t2[maxn],c[maxn ...
- 【模板】BZOJ 1692:队列变换—后缀数组 Suffix Array
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=1692 题意: 给出一个长度为N的字符串,每次可以从串头或串尾取一个字符,添加到新串中,使新串 ...
- No1_3.数组初始化_Java学习笔记
public class HelloArray { public static void main(String[] args) { // TODO Auto-generated method stu ...
- JavaScript数组的方法 | 学习笔记分享
数组 数组的四个常用方法 push() 该方法可以向数组的末尾添加一个或多个元素,并返回数组的新长度 可以将要添加的元素作为方法的参数传递,这些元素将会自动添加到数组的末尾 pop() 该方法可以删除 ...
- Numpy array学习笔记
随机推荐
- IPython与Jupyter notebook 安装与配置,插件扩展,主题,PDF输出
基于 python2.7.13 32-bit版本安装 1.安装pyreadline https://pypi.python.org/pypi/pyreadline 下载对应的32位版本 安装Micro ...
- Django项目开发-小技巧
当你开发完一个Django项目之后肯定要吧他丢到服务器让跑起来,但是你在自己的环境下安装了好多的包,是不是在服务器中也要一个个的安装了, pip freeze > read.txt #这条命令会 ...
- Axure安装fontawesome字体
http://www.fontawesome.com.cn/ 下载后,双击安装字体提示 不是有效的字体,百度 ..解决方法: 任务管理器--服务-- MpsSvc-Windows Firewall ...
- 分页语句-取出sql表中第31到40的记录(以自动增长ID为主键)
sql server方案1: id from t order by id ) orde by id sql server方案2: id from t order by id) order by id ...
- 借助ltp语义分析提取特征,之后,文本生成
"""地点-哪里有做-业务-的(正规|靠谱)-公司?地点-做-业务-的(正规|靠谱)-公司(有哪些?|的联系方式是什么?|哪家口碑好值得信赖?)地点-做-业务-(怎么能省 ...
- Windows 异步IO操作
Windows提供了4种不同的方法来接收I/O请求已经完成的通知:触发设备内核对象.触发事件内核对象.可提醒I/O和I/O完成端口. Windows的异步I/O 当线程向设备发起一个I/O异步 ...
- KMP算法在字符串中的应用
KMP算法是处理字符串匹配的一种高效算法 它首先用O(m)的时间对模板进行预处理,然后用O(n)的时间完成匹配.从渐进的意义上说,这样时间复杂度已经是最好的了,需要O(m+n)时间.对KMP的学习可以 ...
- JAVA JVM 流程一
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的.Java虚拟机 ...
- 11_传智播客iOS视频教程_NS前缀和@符号
NS前缀的有NSLog和NSString Cocoa就是用来开发带界面的应用程序. Foundation框架之中的类.函数绝大多数都是从NextStep来的.看到NS前缀就知道这个类是从哪里来的.是很 ...
- log4j的1.2.15版本,在pom.xml中的顶层project报错错误: Failure to transfer javax.jms:jms:jar:1.1 from https://maven-repository.dev.java.net/nonav/repository......
在动态网站工程中,添加了Pom依赖,当添加log4j的1.2.15版本依赖时,在pom.xml中的顶层project报错错误: Failure to transfer javax.jms:jms:ja ...