腾讯数据库tdsql部署与验证
环境准备
| 主机 | IP | 配置(最低要求配置) |
| :----- | ------------- | ------------------ |
| node-1 | 192.168.1.81 | 8核16G |
| node-2 | 192.168.1.160 | 8核16G |
| node-3 | 192.168.1.202 | 8核16G |
自己整理的文档[7天有效期]:
链接:https://pan.baidu.com/s/1MS1YMx2IobyJYkghVqcHrQ
提取码:4osl
复制这段内容后打开百度网盘手机App,操作更方便哦--来自百度网盘超级会员V5的分享
物料包准备
tdsql_full_install_ansible_10.3.14.1.0_D002.zip
TDSQL私有云部署手册 151.doc
每个服务器准备2块额外磁盘用于HDFS
下载地址:
配置要求:
测试环境:
至少需要3台机器来搭建一个最小的TDSQL集群(2台物理机用于DB、1台虚拟机用于调度和运营体系部署)
| 组件 | 机器数 | 机器配置(CPU/内存/磁盘) | 备注 |
|---|---|---|---|
| zookeeper | 1台 | 虚拟机 2C/4G/100G | |
| keeper | 0台 | 虚拟机 2C/4G/100G | 可以与zookeeper同机部署 |
| oss | 0台 | 虚拟机 2C/4G/100G | 可以与zookeeper同机部署 |
| DB | 2台 | 物理机 8C/16G/500GSSD | |
| Proxy | 0台 | 物理机 2C/4G/100G | 可以与db机器同机部署 |
| monitor | 0台 | 虚拟机 2C/4G/100G | 可以与zookeeper同机部署 |
| chitu | 0台 | 虚拟机 2C/4G/100G | 可以与zookeeper同机部署 |
| hdfs(可选) | 1台 | 物理机 4C/4G/1T | 可选,磁盘容量看具体需求 |
| LVS(可选) | 2台 | 物理机2C/4G/100G | 可选 |
| es | 1台 | 虚拟机 2C/4G/100G | |
| kafka | 3台 | 虚拟机 2C/4G/100G | 加载java虚拟机的时候会吃掉3个g |
正式环境:
| 组件 | 机器数 | 机器配置(CPU/内存/磁盘) | 备注 |
|---|---|---|---|
| zookeeper | 3台/5台 | 虚拟机8C/16G/500G | |
| keeper | 0台 | 虚拟机8C/16G/500G | 可以与oss同机部署 |
| oss | 2台 | 虚拟机8C/16G/500G | |
| DB | 3*n台 | 物理机 32C/64G/1T SSD | 一主两备,机器配置看具体需求 |
| Proxy | 3台 | 物理机8C/16G/500G | 可以与DB机器同机部署,机器配置看具体需求 |
| monitor | 3台 | 虚拟机 8C/16G/500G | 可以与zookeeper同机部署 |
| chitu | 2台 | 虚拟机 8C/16G/500G | 可以与zookeeper同机部署 |
| hdfs(可选) | 3台 | 物理机8C/8G/12T | 可选,磁盘容量看具体需求 |
| LVS(可选) | 2台 | 物理机8C/16G/500G | 可选 |
| kafka(可选) | 3台 | 物理机8C/16G/2T | 多源同步组件,万兆网卡 |
| consumer(可选) | 1台 | 物理机8C/16G/500G | 多源同步组件,可与kafka混部 |
| es | 1台 | 物理机8C/16G/500G |
当前环境规划:
| 模块 | 192.168.1.81 | 192.168.1.160 | 192.168.1.202 |
|---|---|---|---|
| zk | Y | Y | Y |
| scheduler | Y | Y | |
| oss | Y | Y | |
| chitu | Y | Y | |
| monitor(采集监控) | Y | Y | |
| db | Y | Y | |
| proxy | Y | Y | |
| hdfs | Y |
TDSQL部署
免密配置
ssh-keygen -f ~/.ssh/id_rsa -N ''
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.81
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.160
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.202
解包
#解包
unzip tdsql_full_install_ansible_10.3.14.1.0_D002.zip
#执行pythin脚本安装ansible
cd tdsql_full_install_ansible
python settings/install_ansible.py
#格式化数据盘,新建data1目录[所有机器]
mkfs.xfs -f /dev/sdb
mkdir -p /data1
mount /dev/sdb /data1
修改配置:
#vim group_vars/all (修改网卡名和数据库密码)
sed -i 's/netif_name: .*$/netif_name: eth0/' group_vars/all
sed -i 's/tdsql_pass: .*$/tdsql_pass: a+complex+123456/' group_vars/all
sh -x encrypt.sh
修改tdhost文件:
[root@node-1 tdsql_full_install_ansible]# pwd
/root/tdsql_full_install_ansible
cat tdsql_hosts
#-------------------------------------------------------------#
[envcheck]
mac1 ansible_ssh_host=192.168.1.81
mac2 ansible_ssh_host=192.168.1.160
mac3 ansible_ssh_host=192.168.1.202
[zk]
zk1 ansible_ssh_host=192.168.1.81
zk2 ansible_ssh_host=192.168.1.202
zk3 ansible_ssh_host=192.168.1.160
[scheduler]
scheduler1 ansible_ssh_host=192.168.1.202
scheduler2 ansible_ssh_host=192.168.1.160
[oss]
oss1 ansible_ssh_host=192.168.1.202
oss2 ansible_ssh_host=192.168.1.160
[chitu]
chitu1 ansible_ssh_host=192.168.1.202
chitu2 ansible_ssh_host=192.168.1.160
[monitor]
monitor1 ansible_ssh_host=192.168.1.202
monitor2 ansible_ssh_host=192.168.1.160
[db]
db1 ansible_ssh_host=192.168.1.202
db2 ansible_ssh_host=192.168.1.160
[proxy]
proxy1 ansible_ssh_host=192.168.1.202
proxy2 ansible_ssh_host=192.168.1.160
[hdfs]
hdfs1 ansible_ssh_host=192.168.1.160
[es]
es1 ansible_ssh_host=192.168.1.81
[newdb]
newdb1 ansible_ssh_host=1.1.1.1
newdb2 ansible_ssh_host=2.2.2.2
newdb3 ansible_ssh_host=3.3.3.3
#-------------------------------------------------------------#
设置tdsql明文密码
#假定我们给tdsql账号设置的明文密码为:a+complex+123456
cat group_vars/all
---
zk_num: 3 #<---填入zk集群的数量,1、3或者5
netif_name: eth0 #<---填入scheduler(ifconfig看到的)网卡的名称
tdsql_pass: a+complex+123456 #<---填入tdsql账号的明文密码
zk_rootdir: /tdsqlzk2 #<---填入tdsql系统在zk上的根路径(一般不改)
metadb_ip: 1.1.1.1 #<-----暂时不改动
metadb_port: 15001 #<-----暂时不改动
metadb_ip_bak: 2.2.2.2 #<-----暂时不改动
metadb_port_bak: 15001 #<-----暂时不改动
metadb_user: tdsql_hanlon #<-----暂时不改动
metadb_password: 123456 #<-----暂时不改动
ssh_port: 22 #<-----暂时不改动
hdfs_datadir: /data1/hdfs #<-----暂时不改动
kafka_logdir: /data1/kafka #<-----暂时不改动
es_mem: 8 #<-----暂时不改动
es_log_days: 7 #<-----暂时不改动
es_base_path: /data/application/es-install/es #<-----暂时不改动
tdsql_secret_pass: K2JatUv5llBbMrske/k2YbqC #<-------密文密码,自动更新,切勿手动更改
oc_secret_pass: LGhVs0v5nVxcOLQie/k9bb2I #<-------密文密码,自动更新,切勿手动更改
clouddba_metadb_pass: h5Wyg2Xy #<-------密文密码,自动更新,切勿手动更改
---
zk_num: 3
netif_name: eth0
tdsql_pass: a+complex+123456
zk_rootdir: /tdsqlzk2
metadb_ip: 1.1.1.1
metadb_port: 15001
metadb_ip_bak: 2.2.2.2
metadb_port_bak: 15001
metadb_user: tdsql_hanlon
metadb_password: 123456
ssh_port: 22
hdfs_datadir: /data1/hdfs
kafka_logdir: /data1/kafka
es_mem: 8
es_log_days: 7
es_base_path: /data/application/es-install/es
tdsql_secret_pass: K2JatUv5llBbMrske/k2YbqC
oc_secret_pass: LGhVs0v5nVxcOLQie/k9bb2I
clouddba_metadb_pass: h5Wyg2Xy
部署
#vim group_vars/all (修改网卡名和数据库密码)
sed -i "s/netif_name:.*/netif_name: eth0/" group_vars/all
sed -i "s/tdsql_pass:.*/tdsql_pass: a+complex+123456/" group_vars/all
#安装zk:
#使用tdsql安装的zk
sh -x encrypt.sh
ansible-playbook -i tdsql_hosts part1_site.yml
#访问任意节点:
[root@node-1 tdsql_full_install_ansible]# grep chitu tdsql_hosts
[chitu]
chitu1 ansible_ssh_host=192.168.1.202
chitu2 ansible_ssh_host=192.168.1.160
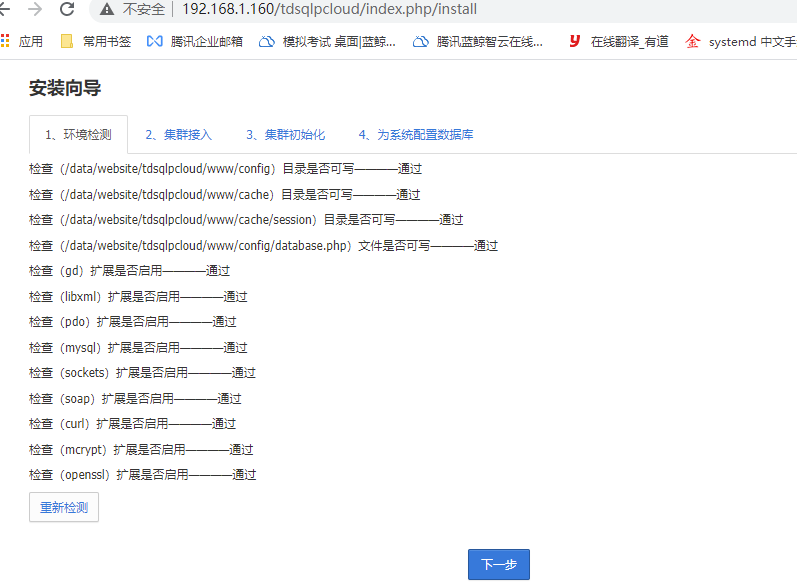
集群配置
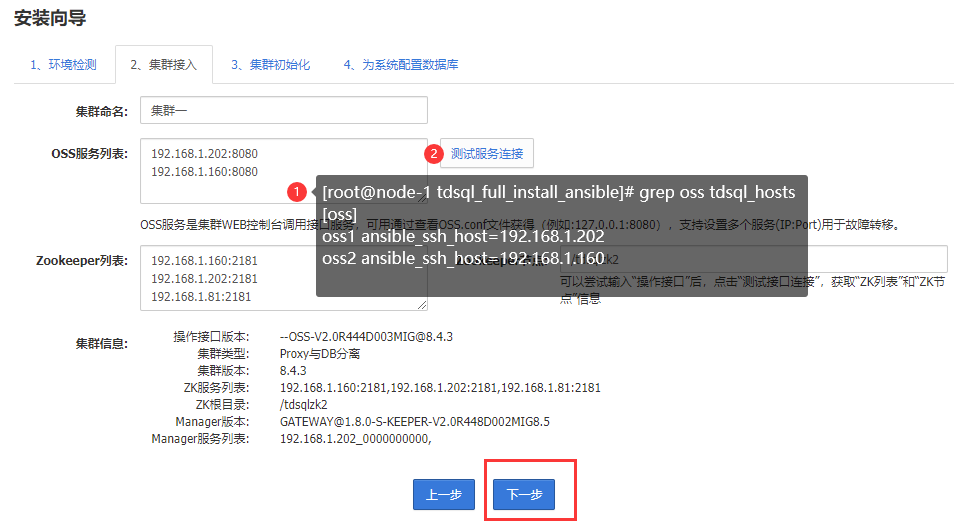
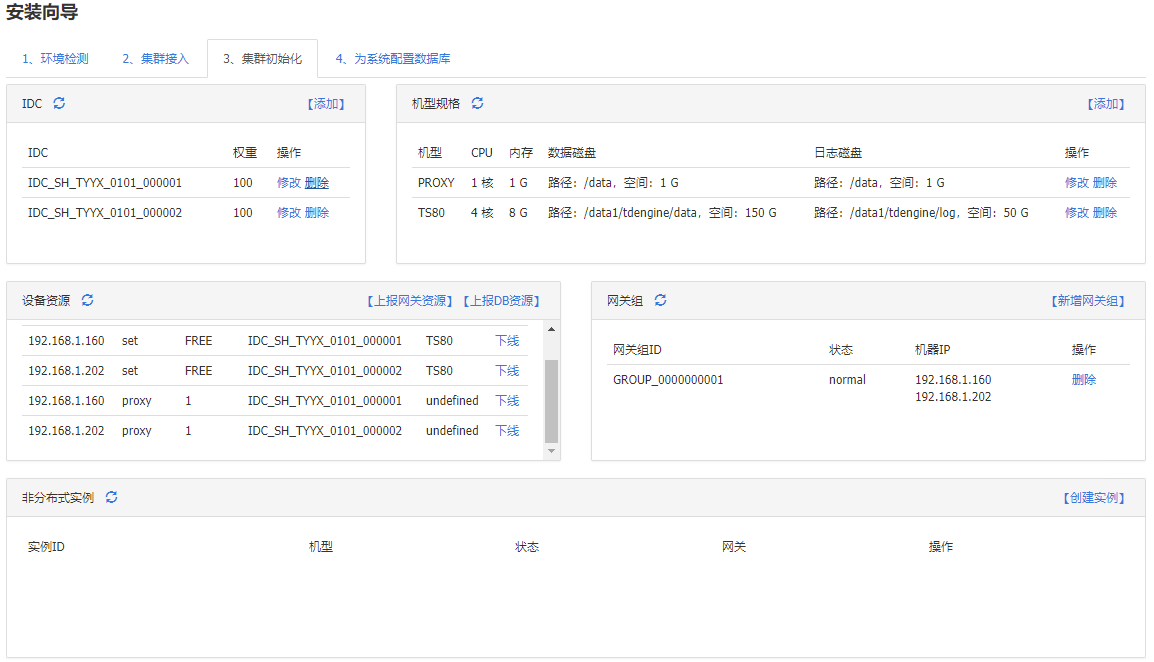
集群初始化
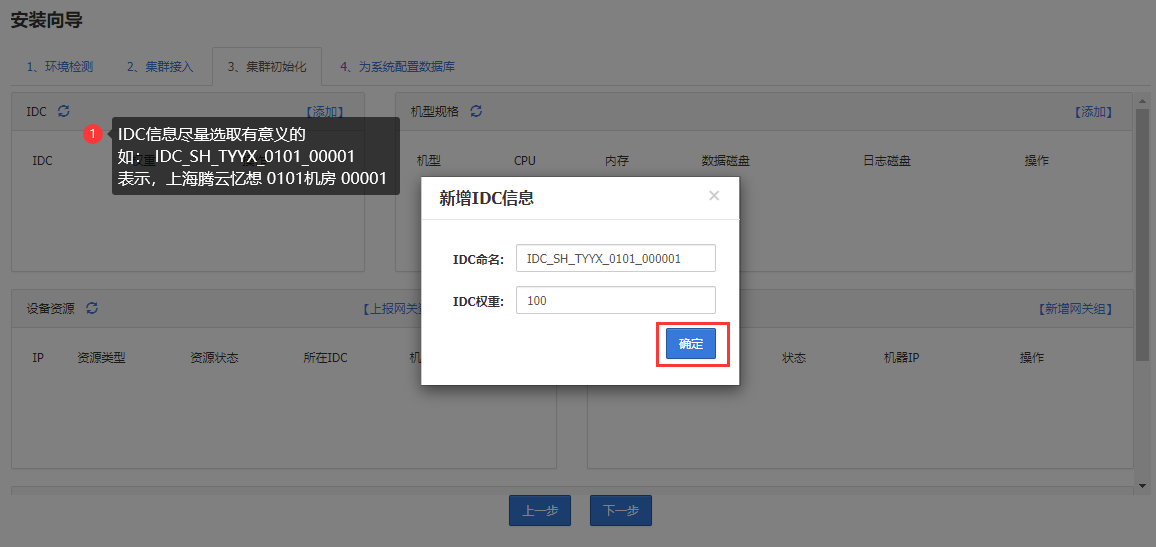
添加机房
添加机型规格
proxy机型并非实际用到的 这里随便怎么写都行
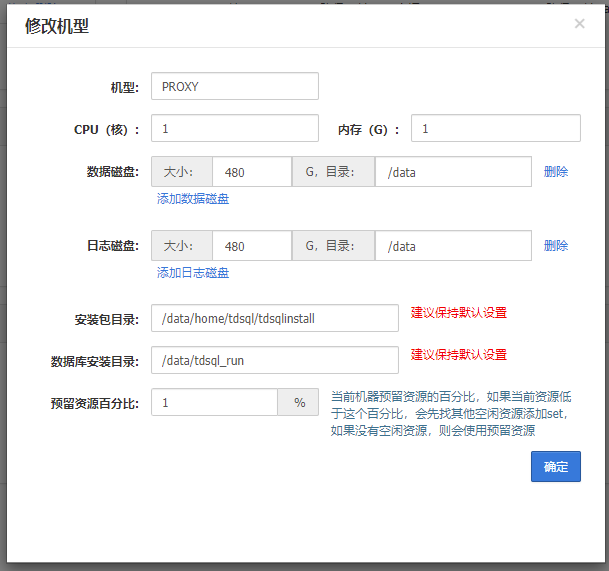
添加TS80机型为后续数据库使用的机型,配置如下
mkfs.xfs /dev/sdb
mkdir /data1
mount /dev/sdb /data1
TS80机型配置:
数据磁盘目录:
建议是: /data1/tdengine/data
日志磁盘目录:
建议是: /data1/tdengine/log
安装包目录:
/data/home/tdsql/tdsqlinstall,固定不变
数据库安装目录:
/data/tdsql_run,固定不变
数据磁盘与日志磁盘大小比例为 3:1
设备资源添加
上报网关资源
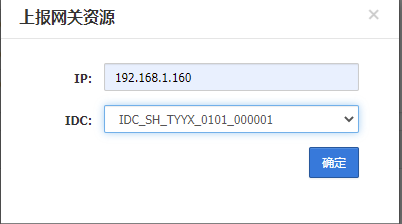
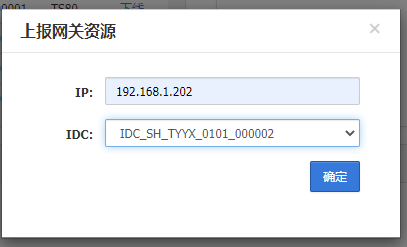
这里添加了3个网关资源并且对应了2个IDC,在组成网关组的时候可以选择2个IDC取3个服务器
上传DB资源:
192.168.1.81 192.168.1.160 划分到机房1 192.168.1.202划分到机房2 用于组成集群,并设置了3个网关
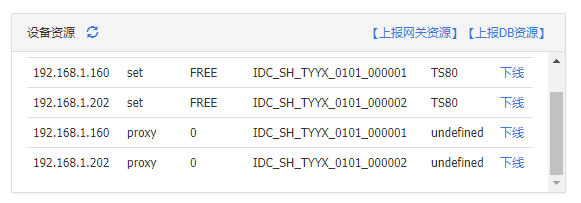
因为目前两个机房有3台服务器,上报资源时上报了2个DB服务器所以可以从2个机房取2台服务器


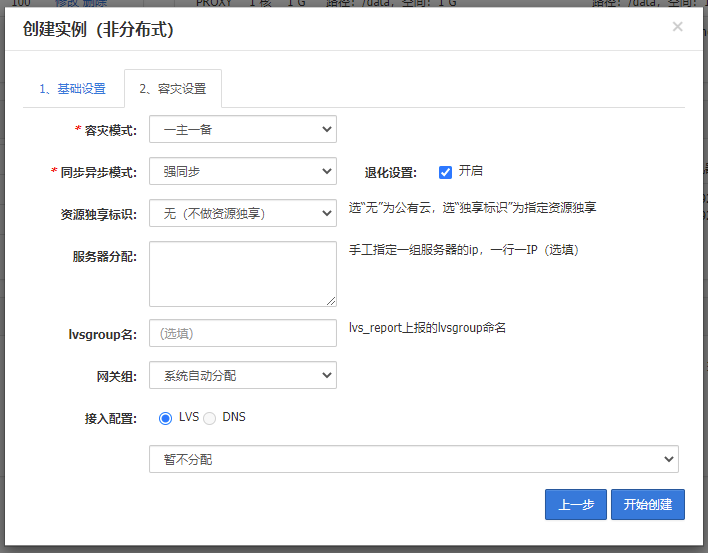
开始创建:
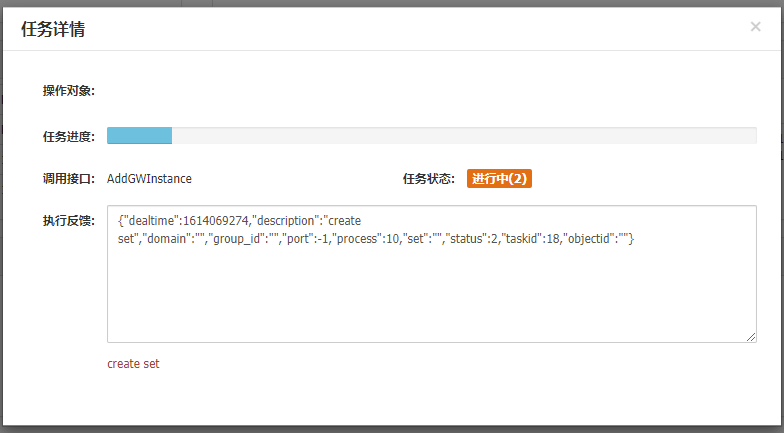


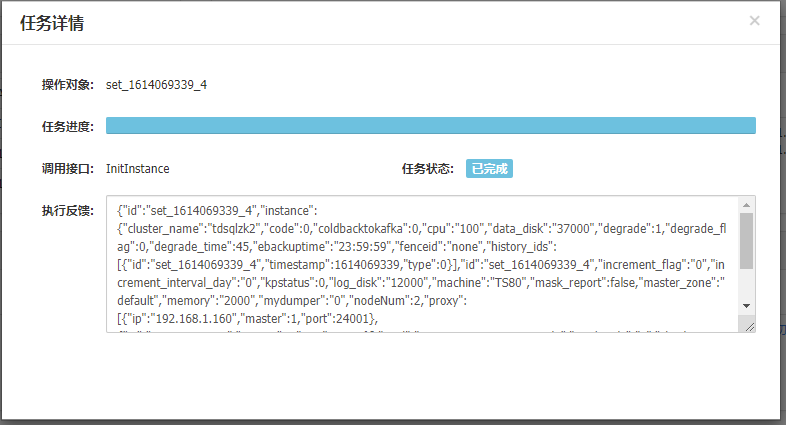
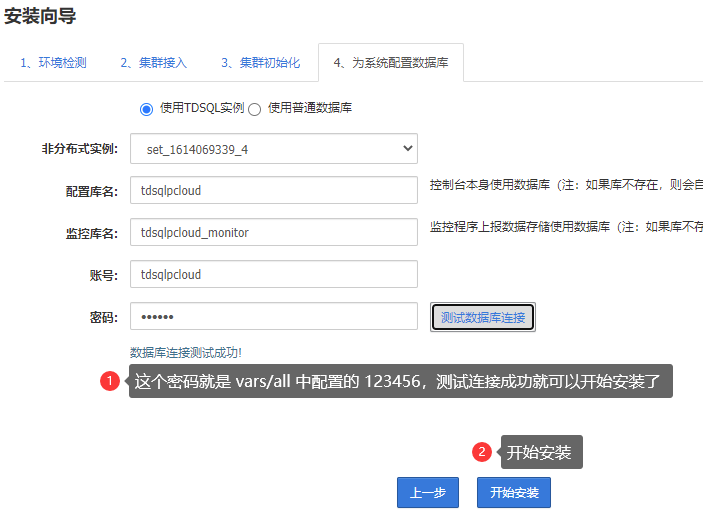
初始化完成后直接下一步:
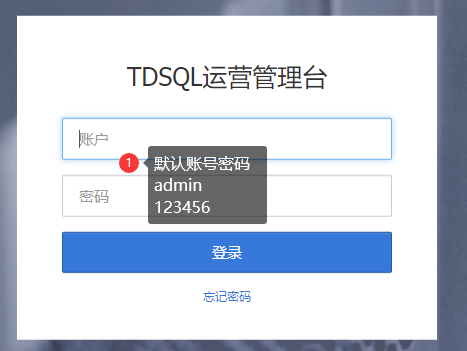
安装完成会直接跳转到登录页面:
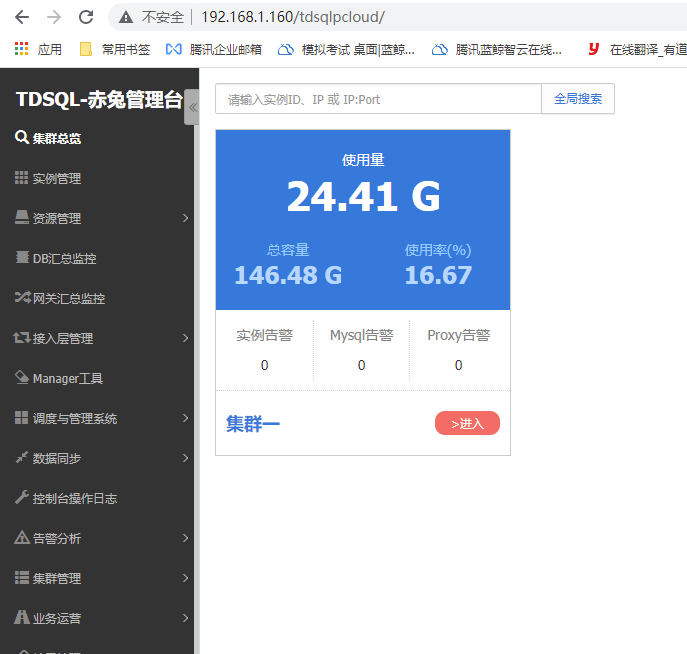
http://192.168.1.160/tdsqlpcloud
测试tdsql连接
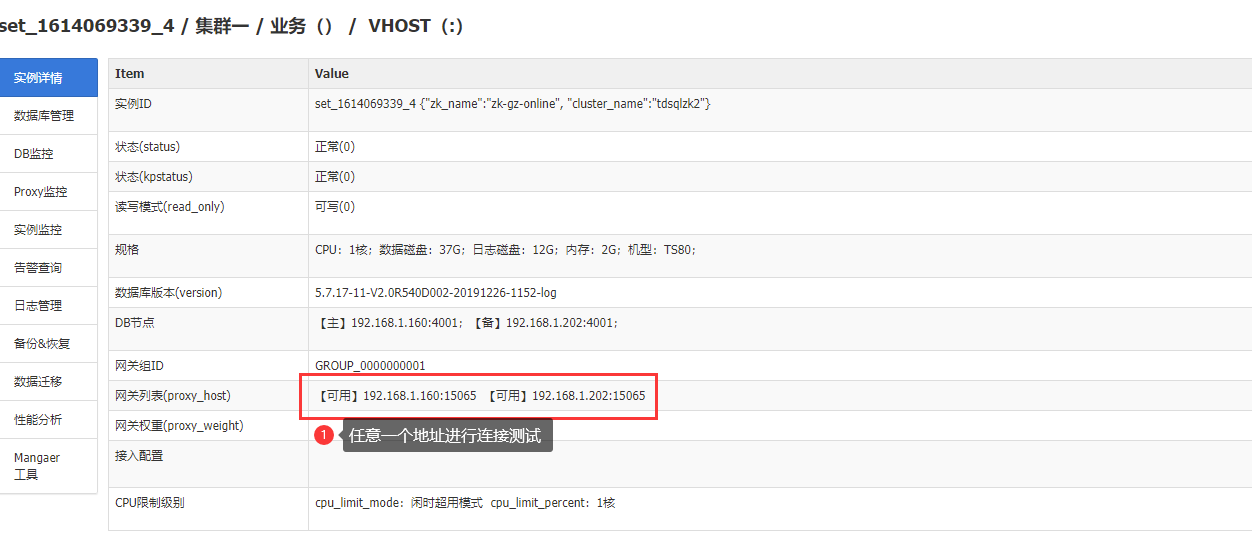
mysql -utdsqlpcloud -h192.168.1.160 -P15065 -p'123456'
[root@node-1 tdsql_full_install_ansible]# mysql -utdsqlpcloud -h192.168.1.160 -P15065 -p'123456'
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 3648
Server version: 5.7.17-11-V2.0R540D002-20191226-1152-log Source distribution
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]>
测试mysql连接无误,将连接账号密码写入到 group_vars/all 文件中
---
zk_num: 3
netif_name: eth0
tdsql_pass: a+complex+123456
zk_rootdir: /tdsqlzk2
metadb_ip: 192.168.1.160 #主库IP
metadb_port: 15065 #主库端口
metadb_ip_bak: 192.168.1.202 #从库IP
metadb_port_bak: 15065 #从库端口
metadb_user: tdsqlpcloud #数据库连接账号
metadb_password: 123456 #数据库连接密码
ssh_port: 36000
hdfs_datadir: /data2/hdfs,/data3/hdfs,/data4/hdfs
kafka_logdir: /data2/kafka,/data3/kafka,/data4/kafka
es_mem: 8
es_log_days: 7
es_base_path: /data/application/es-install/es
tdsql_secret_pass: S8dfgSoMUjGaUn+EHkm3pA==
oc_secret_pass: TM1QhyoMWT2dWHCCHkm8qA==
clouddba_metadb_pass: h5Wyg2Xy
执行安装part2_site.yml
#安装大约4分钟左右,日志路径/var/log/ansible.log,最终显示failed任务数为0表示安装成功。
sh -x encrypt.sh <---------必须执行,更新密文密码
ansible-playbook -i tdsql_hosts part2_site.yml
#找到安装了 scheduler 的服务器并执行:
[root@node-1 tdsql_full_install_ansible]# grep scheduler tdsql_hosts
[scheduler]
scheduler1 ansible_ssh_host=192.168.1.202
scheduler2 ansible_ssh_host=192.168.1.160
# ssh 192.168.1.202
cd /data/application/scheduler/bin
./agent_config --mode modify --option="ocagent_port" --value="8966"
./agent_config --mode modify --option="hadoop_dir" --value=" /data/home/tdsql/hadoop-3.2.1/bin"
#执行结果:
[root@node-1 tdsql_full_install_ansible]# ssh 192.168.1.202
Last login: Tue Feb 23 16:57:56 2021 from 192.168.1.81
[root@localhost ~]# cd /data/application/scheduler/bin
[root@localhost bin]# ./agent_config --mode modify --option="ocagent_port" --value="8966"
zookeeper timeout:10000 msec,msg timeout 30000 msec
zookeeper path:/tdsqlzk2/configs/agent@global
zookeeper value:{
"hadoop_dir" : "/data/home/tdsql/hadoop-3.2.1/bin",
"ocagent_port" : "8966"
}
operation success!
[root@localhost bin]# ./agent_config --mode modify --option="hadoop_dir" --value=" /data/home/tdsql/hadoop-3.2.1/bin"
zookeeper timeout:10000 msec,msg timeout 30000 msec
zookeeper path:/tdsqlzk2/configs/agent@global
zookeeper value:{
"hadoop_dir" : " /data/home/tdsql/hadoop-3.2.1/bin",
"ocagent_port" : "8966"
}
operation success!
安装备用赤兔:
将已初始化的chitu机器上拷贝2个文件到未初始化的chitu机器上,并删除未初始化chitu机器上的crontab,如下:
192.168.1.202 已初始化chitu
192.168.1.160 未初始化chitu
(1)在202机器上,拷贝文件到160机器上
scp -p /data/website/tdsqlpcloud/www/config/database.php 192.168.1.160:/data/website/tdsqlpcloud/www/config/
scp -p /data/website/tdsqlpcloud/www/config/install.lock 192.168.1.160:/data/website/tdsqlpcloud/www/config/
(2)删除160机器上nginx用户的crontab
[root@localhost bin]# ssh 192.168.1.160
[root@localhost ~]# cp -a /var/spool/cron/nginx /data/tools/nginx_cron_bak
[root@localhost ~]# rm -f /var/spool/cron/nginx
(3)测试,登录205的chitu
http://192.168.1.160/tdsqlpcloud
安装HDFS服务
由于磁盘前面已经添加并格式化过,这里不用操作了
#需要安装hdfs的服务器修改主机名[必须修改,因为我们的主机名存在 - 线 需要改成没有特殊符号的]
#修改 tdsql_hosts 文件,将需要安装hdfs服务的服务器添加上去,这里就添加3台hdfs
vim tdsql_hosts 新增hdfs配置:
[hdfs]
hdfs1 ansible_ssh_host=192.168.1.81
hdfs2 ansible_ssh_host=192.168.1.160
hdfs3 ansible_ssh_host=192.168.1.202
#安装hdfs单点[适用于低配服务器]:
#执行安装
ansible-playbook -i tdsql_hosts hdfs_single.yml
#切换到tdsql用户
su - tdsql
#用tdsql用户在hdfs1机器上,格式化namenode
hdfs namenode -format
#用tdsql用户在hdfs1机器上,启动namenode和datanode
hdfs --daemon start namenode
hdfs --daemon start datanode
#附:用tdsql用户关闭hdfs进程
hdfs --daemon stop datanode
hdfs --daemon stop namenode
#安装hdfs高可用安装启动
#在安装时需要保证主机名修改了
#[本文用多点,配置不高就用单点如果hdfs多点,那么zk服务也需要是多点,因为之前配置的zk就是多点,这里就可以继续安装多点hdfs,否则安装单点]:
#每台服务器需要主机名不同 设置方法: hostnamectl set-hostname node1
ansible-playbook -i tdsql_hosts hdfs.yml
#初始化HDFS:
#用tdsql用户在hdfs1机器,格式化zk
hdfs zkfc -formatZK
#用tdsql用户在所有机器,启动journalnode
hdfs --daemon start journalnode
#用tdsql用户在hdfs1机器,格式化并启动namenode
hdfs namenode -format
hdfs --daemon start namenode
#用tdsql用户在hdfs2机器,格式化namenode
hdfs namenode -bootstrapStandby
#------------------------------启动hdfs集群------------------------------#
#用tdsql用户在hdfs1机器,格式化并启动 zk
su - tdsql
hdfs zkfc -formatZK #格式化只能一次
#所有机器启动 journalnode
hdfs --daemon start journalnode
#在hdfs1和hdfs2上启动namenode
hdfs --daemon start namenode
#在hdfs1和hdfs2上启动zkfc
hdfs --daemon start zkfc
#在所有hdfs机器上启动datanode
hdfs --daemon start datanode
#------------------------------启动hdfs集群------------------------------#
#------------------------------停止hdfs集群------------------------------#
在所有hdfs机器上关闭datanode
hdfs --daemon stop datanode
在hdfs1和hdfs2上关闭zkfc
hdfs --daemon stop zkfc
在hdfs1和hdfs2上关闭namenode
hdfs --daemon stop namenode
在所有hdfs机器上关闭journalnode
hdfs --daemon stop journalnode
#------------------------------停止hdfs集群------------------------------#
# hdfs haadmin -getAllServiceState 命令执行失败尝试:
hdfs --daemon stop namenode
hdfs --daemon stop journalnode
hdfs --daemon start namenode
hdfs --daemon start journalnode
hdfs dfsadmin -report
hdfs haadmin -getAllServiceState
在hdfs集群下查看/tdsqlbackup路径
(7)在hdfs集群下查看/tdsqlbackup路径
用tdsql用户执行以下命令
su - tdsql
#查看/tdsqlbackup目录是否已经被自动创建,权限是否是:tdsql supergroup
hadoop fs -ls /
drwxr-xr-x - tdsql supergroup 0 2019-01-02 17:52 /tdsqlbackup
#如果目录不在或者权限不对,用下面命令修改:
hadoop fs -mkdir /tdsqlbackup
hadoop fs -chown tdsql.supergroup /tdsqlbackup
检查HDFS端口并补充到 group_vars/all 文件中
如果是3节点的hdfs架构,如上图所示填写namenode节点(一般2个)的50070端口
/data2/hdfs /data3/hdfs /data4/hdfs
将这些信息填写到all文件中
hdfs_datadir: /data2/hdfs,/data3/hdfs,/data4/hdfs
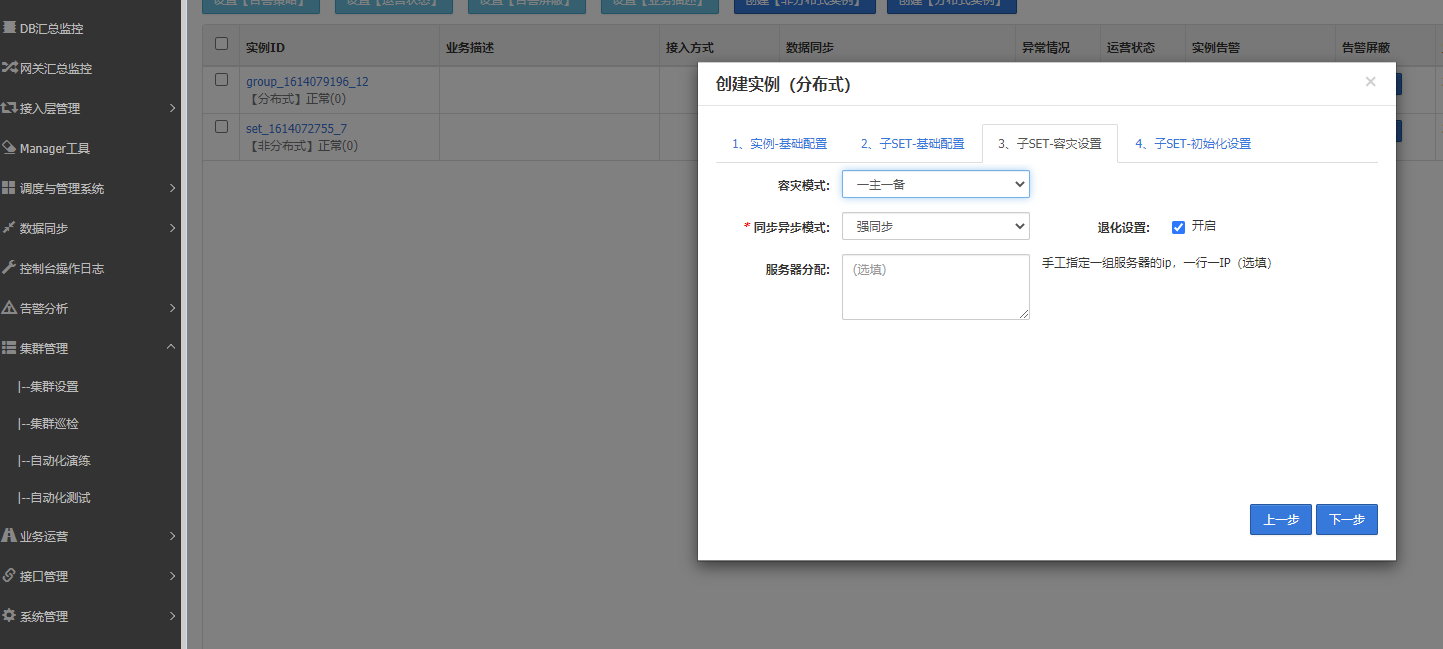
自动化演练

创建一个分布式实例:

腾讯数据库tdsql部署与验证的更多相关文章
- 286万QPS!腾讯云TDSQL打造数据库领域的“超音速战机”
Bloodhound SSC超音速汽车将陆地极限速度提升到1678公里/小时,号称陆地“超音速战斗机”.无独有偶,同样也在2017年,在英特尔®.腾讯金融云团队的共同见证下,腾讯云数据库TDSQL采用 ...
- 腾讯云分布式数据库TDSQL在银行传统核心系统中的应用实践
本文是腾讯云TDSQL首席架构师张文在腾讯云Techo开发者大会现场的演讲实录,演讲主题是<TDSQL在银行传统核心系统中的应用实践>. 我是TDSQL架构师张文,同时也是TDSQL的开发 ...
- 强强联袂!腾讯云TDSQL与国双战略签约,锚定国产数据库巨大市场
日前,腾讯云计算(北京)有限责任公司与北京国双科技有限公司签署了<国产数据库产品战略合作协议>,双方将在数据库技术方面展开深度合作,通过分布式交易型数据库的联合研发.产品服务体系建设.品牌 ...
- 怎样将本地web数据库项目部署到腾讯云服务器上?
怎样将本地web数据库项目 部署到腾讯云服务器上? 1.本地计算机的工作: 1.1用eclipse或者myeclipse做好一个web项目,可以只做一个数据库的增删改查,本地部署到Tomcat服务器, ...
- Greenplum 数据库安装部署(生产环境)
Greenplum 数据库安装部署(生产环境) 硬件配置: 16 台 IBM X3650, 节点配置:CPU 2 * 8core,内存 128GB,硬盘 16 * 900GB,万兆网卡. 万兆交换机. ...
- 腾讯云TDSQL审计原理揭秘
版权声明:本文由孙勇福原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/244 来源:腾云阁 https://www.qclo ...
- 转_Greenplum 数据库安装部署(生产环境)
Greenplum 数据库安装部署(生产环境) 硬件配置: 16 台 IBM X3650, 节点配置:CPU 2 * 8core,内存 128GB,硬盘 16 * 900GB,万兆网卡. 万兆交换机. ...
- SQL Server 2008 数据库镜像部署实例之三 配置见证服务器
SQL Server 2008 数据库镜像部署实例之三 配置见证服务器 前面已经完成了镜像数据库的配置,并进行那个了故障转移测试.接下来将部署见证服务器,实现自动故障转移. 一.关于见证服务器 1.若 ...
- SQL Server 2008 数据库镜像部署实例之二 配置镜像,实施手动故障转移
SQL Server 2008 数据库镜像部署实例之二 配置镜像,实施手动故障转移 上一篇文章已经为配置镜像数据库做好了准备,接下来就要进入真正的配置阶段 一.在镜像数据库服务器上设置安全性并启动数据 ...
随机推荐
- Spring Boot自定义starter必知必会条件
前言 在目前的Spring Boot框架中,不管是Spring Boot官方还是非官方,都提供了非常多的starter系列组件,助力开发者在企业应用中的开发,提升研发人员的工作效率,Spring Bo ...
- UI中的事件系统EventSystem
一.EventSystem简介 用于处理事件的分发和相应的系统,创建画布的同时会创建事件系统 二.UGUI实现事件系统的3种方式 1.使用组件eventTrigger(不推荐),拖动赋值 2.代码添加 ...
- [CF套题] CF-1201
CF-1201 传送门 # = * A 500 B 1000 C 1500 D 2000 E1 2000 E2 1000 1 (2217) 1672 482 00:09 400 01:40 790 0 ...
- 1152 Google Recruitment
题干前半略. Input Specification: Each input file contains one test case. Each case first gives in a line ...
- Codeforces Round #627 (Div. 3) F - Maximum White Subtree(深度优先搜索)
题意: n 个点 n - 1 条边的树,问每个点所在所有子树中白黑点数目的最大差. 思路: 白点先由下至上汇集,后由上至下分并. #include <bits/stdc++.h> usin ...
- POJ - 2406 Power Strings (后缀数组DC3版)
题意:求最小循环节循环的次数. 题解:这个题其实可以直接用kmp去求最小循环节,然后在用总长度除以循环节.但是因为在练后缀数组,所以写的后缀数组版本.用倍增法会超时!!所以改用DC3法.对后缀数组还不 ...
- Codeforces Round #498 (Div. 3) E. Military Problem (DFS)
题意:建一颗以\(1\)为根结点的树,询问\(q\)次,每次询问一个结点,问该结点的第\(k\)个子结点,如果不存在则输出\(-1\). 题解:该题数据范围较大,需要采用dfs预处理的方法,我们从结点 ...
- python代理池的构建5——对mongodb数据库里面代理ip检查
上一篇博客地址:python代理池的构建4--mongdb数据库的增删改查 一.对数据库里面代理ip检查(proxy_test.py) #-*-coding:utf-8-*- ''' 目的:检查代理I ...
- windows server 2016 安装有线网卡驱动
为自己的本本安装了server 2016系统,但是官网下载的有线网卡驱动一直安不上,解决方法如下: 1.到Intel官网下载一个叫PROWinx64的驱动程序,解压到任意文件夹.依次进入PRO1000 ...
- Win7下安装IIS
安装IIS 1.控制面板 --> 程序 --> 卸载程序,进入"程序与功能". 2.进入"打开或关闭Window功能". 3.找到"Int ...