分类模型的F1-score、Precision和Recall 计算过程
分类模型的F1分值、Precision和Recall 计算过程
引入
通常,我们在评价classifier的性能时使用的是accuracy
考虑在多类分类的背景下
accuracy = (分类正确的样本个数) / (分类的所有样本个数)
这样做其实看上去也挺不错的,不过可能会出现一个很严重的问题:例如某一个不透明的袋子里面装了1000台手机,其中有600台iphone6, 300台galaxy s6, 50台华为mate7,50台mx4(当然,这些信息分类器是不知道的。。。)。如果分类器只是简单的把所有的手机都预测为iphone6, 那么通过上面的公式计算的准确率accuracy为0.6,看起来还不错;可是三星,华为和小米的全部预测错了。如果再给一个袋子,里面装着600台galaxy s6, 300台mx4, 50台华为mate7,50台iphone,那这个分类器立马就爆炸了,连回家带孩子的要求都达不到
所以,仅仅用accuracy来衡量一个分类器的性能是很不科学的。因此要引入其他的衡量标准。
二分类
是不是经常看见如下类似的图?这是二分类的图,假设只有正类和负类,True和False分别表示对和错;Positive和Negative分别表示预测为正类和负类。

那么
- TP:预测为Positive并且对了(样本为正类且预测为正类)
- TN:预测为Negative并且对了(样本为负类且预测为负类)
- FP:预测为Positive但错了(样本为负类但预测为正类)
- FN:预测为Negative但错了(样本为正类但预测为负类)
- TP+FP:预测为Positive并且对了+预测为Positive但错了=预测为Positive的样本总数
- TP+FN:预测为Positive并且对了+预测为Negative但错了=实际为Positive的样本总数
所以precision就表示:被正确预测的Positive样本 / 被预测为Positive的样本总数
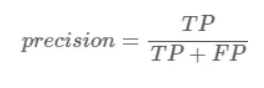
同理,recall就表示:被正确预测的Positive样本 / 实际为Positive的样本总数
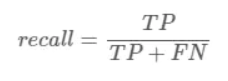
F1是调和平均值,精准率和召回率只要有一个比较小的话,F1的值也会被拉下来:

多分类情况
其实和二分类情况很类似,例子如下 这个是Micro , 和二分类类似 (将例子中的precision和recall代入到F1公式中,得到的就是Micro下的F1值)

而Macro情况下计算F1需要先计算出每个类别的F1值,然后求平均值。如下

Macro情况下上述例子的计算

sklearn计算程序(macro)
下面是使用sklearn直接计算多类别F1/P/R的程序,将接口中的average参数配置为’macro’即可。
from sklearn.metrics import f1_score, precision_score, recall_score
y_true=[1,2,3]
y_pred=[1,1,3]
f1 = f1_score( y_true, y_pred, average='macro' )
p = precision_score(y_true, y_pred, average='macro')
r = recall_score(y_true, y_pred, average='macro')
print(f1, p, r)
# output: 0.555555555556 0.5 0.666666666667
参考链接:
https://blog.csdn.net/ybdesire/article/details/96507733
https://www.jianshu.com/p/14b26f59040b
分类模型的F1-score、Precision和Recall 计算过程的更多相关文章
- 机器学习:评价分类结果(F1 Score)
一.基础 疑问1:具体使用算法时,怎么通过精准率和召回率判断算法优劣? 根据具体使用场景而定: 例1:股票预测,未来该股票是升还是降?业务要求更精准的找到能够上升的股票:此情况下,模型精准率越高越优. ...
- 【tf.keras】实现 F1 score、precision、recall 等 metric
tf.keras.metric 里面竟然没有实现 F1 score.recall.precision 等指标,一开始觉得真不可思议.但这是有原因的,这些指标在 batch-wise 上计算都没有意义, ...
- 机器学习--如何理解Accuracy, Precision, Recall, F1 score
当我们在谈论一个模型好坏的时候,我们常常会听到准确率(Accuracy)这个词,我们也会听到"如何才能使模型的Accurcy更高".那么是不是准确率最高的模型就一定是最好的模型? 这篇博文会向大家解释 ...
- 【笔记】F1 score
F1 score 关于精准率和召回率 精准率和召回率可以很好的评价对于数据极度偏斜的二分类问题的算法,有个问题,毕竟是两个指标,有的时候这两个指标也会产生差异,对于不同的算法,精准率可能高一些,召回率 ...
- 机器学习中的 precision、recall、accuracy、F1 Score
1. 四个概念定义:TP.FP.TN.FN 先看四个概念定义: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False ...
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 分类问题的几个评价指标(Precision、Recall、F1-Score、Micro-F1、Macro-F1
轉自 https://blog.csdn.net/sinat_28576553/article/details/80258619 四个基本概念TP.True Positive 真阳性:预测为正,实 ...
- ROC,AUC,Precision,Recall,F1的介绍与计算(转)
1. 基本概念 1.1 ROC与AUC ROC曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣,ROC曲线称为受试者工作特征曲线 (receiver operatin ...
- ROC,AUC,Precision,Recall,F1的介绍与计算
1. 基本概念 1.1 ROC与AUC ROC曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣,ROC曲线称为受试者工作特征曲线 (receiver operatin ...
随机推荐
- UDP/TCP 流程与总结
1 UDP流程 前序:可以借助网络调试助手工具进行使用 1 UDP 发送方 1 创建UDP套接字 2 准备目标(发送方) IP和端口 3 需要发送的数据内容 4 关闭套接字 from socket i ...
- Disruptor 高性能并发框架二次封装
Disruptor是一款java高性能无锁并发处理框架.和JDK中的BlockingQueue有相似处,但是它的处理速度非常快!!!号称“一个线程一秒钟可以处理600W个订单”(反正渣渣电脑是没体会到 ...
- 谈谈你对this的理解
this的指向不是在编写时确定的,而是在执行时确定的,同时,this不同的指向在于遵循了一定的规则. 1.默认情况下,指向全局,浏览器的话就是指向window 2.如果函数被调用的位置存在上下文,那么 ...
- Scrapy(五):CrawlSpider的使用
Scrapy(五):CrawlSpider的使用 说明 :CrawlSpider,就是一个类,是Spider的一个子类,也是一个官方类,因为是子类,所以功能更加的强大,多了一项功能:去指定的页面中来抓 ...
- sublime text 3+java只编译不输出结果 solution
文章摘自:https://blog.csdn.net/VincentLuo91/article/details/53007135 版权声明:本文为CSDN博主「vincentluo91」的原创文章,遵 ...
- python 并发专题(十):基础部分补充(二)线程
什么是线程 标准描述开启一个进程:开启一个进程:进程会在内存中开辟一个进程空间,将主进程的资料数据全部复制一份,线程会执行里面的代码. ***进程是资源单位, 线程是执行单位:是操作系统调度的最小单元 ...
- Django框架09 /ajax、crsf、settings导入
Django框架09 /ajax.crsf.settings导入 目录 Django框架09 /ajax.crsf.settings导入 1. ajax概述 2. ajax应用 3. ajax上传文件 ...
- js 中 attachEvent 简示例
attachEvent绑定事件,函数的默认this指向为window,要解决问题可以通过call改变方法的指向! var div = document.getElementsByTagName('di ...
- js自定义获取浏览器宽高
/** * @description js自定义获取浏览器宽高 * * IE8 和 IE8 以下的浏览器不兼容 * window.innerWidth * window.innerHeight * * ...
- 【Python学习笔记五】re.findall()方法中,正则的"()"效果
在笔记四中,使用正则去筛选数据时,使用了findall()这个方法,在使用时正则表达式中使用了到了"()",最初以为只是强调执行优先级,后来发现正则表达式中的每一个(),在find ...