Scrapy 5+1 ——五大坑附送一个小技巧
笔者最近对scrapy的学习可谓如火如荼,虽然但是,即使是一整天地学习下来也会有中间两三个小时的“无效学习”,不是笔者开小差,而是掉进了深坑出不来。
在此,给各位分享一下作为一名Scrapy框架的初学者,笔者在学习过程中遇到的各个大坑和小技巧吧。
1. user_agent
这个,在某些网站看来这无关要紧(比如笔者的网站—— 代码的边城 ),但对某些设定了反爬机制的网站来说,这是你的蜘蛛开门遇到的拦路虎。如果没有提前设定好这个参数,那你的蜘蛛连网站都进不去。
不仅网站进不去,而且它还不报错。试问,一个满心壮志,准备在互联网上靠他的蜘蛛大展宏图的人,如果遇到了这样的事,那将是多么的心灰意冷。所以,笔者在这里分享之前的文章,有对此的解决方案,欢迎浏览 点此跳转
2. ROBOTSTXT_OBEY
跟上面的user_agent一样,这也是一个在settings.py里面设定好的参数值。我们通过scrapy固定语句新建项目后就会发现,settings.py里面这条被点亮的,且默认值为True的语句。

这意味着我们的Spider会遵守robots.txt的规则。 简单来说,robots.txt 是遵循 Robot 协议的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望你进行爬取收录。在Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
但我们的爬虫一般来说都没什么节操,也知道不会怎么遵守这条语句,所以在新建好项目的时候,我们就直接把这个配置,设置为False!直接在遇到问题前解决问题!
3. allowed_domains
在我们新建好项目之后,会在你的爬虫文件里出现这条语句
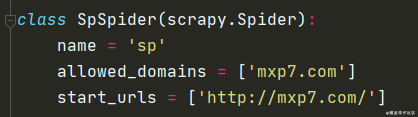
start_urls 一般指的是你的Spider的初始链接,是蜘蛛帝国最开始的基石,allowed_domains就是你蜘蛛帝国最外面的围栏。有一种说法是,scrapy的spider爬取速度特别快,所以为了防止它乱爬到其他界面,我们会在这里设置allowed_domains。设置好后,不属于此范围的域名就会被过滤,我们的蜘蛛也会被好好关在设置好的域名里。
但一个弊端是,这条语句的存在感不强。有时候,我们在写多界面爬虫的时候特别起劲,往往会忘了最开始设定好的域名范围,而我们在进行多页面的数据提取时,很有可能会需要跳出你原来设定好的这个域名,进入其他的域名里提取数据。这时候,这个allowed_domains就成为了我们的绊脚石,如果你忘了它的存在,你会很绝望地发现,你新写的parse函数竟然无法调用下一个界面的数据,而且它还 不!报!错!
解决方法:就是在allowed_domains里添加新的域名,共同作为爬虫爬取的范围

4. tbody 和 font
在笔者写到跟tbody有关的xpath之前,笔者已经知道这个坑了,于是完美避过。如果你还不清楚,可以听笔者细细分析。
我们写xpath路径时,往往都是先找到一个css选择器,然后描写他的路径
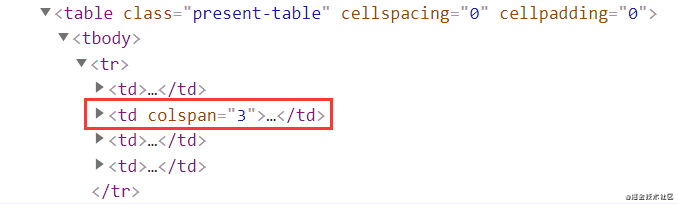
比如我们要在浏览器调试界面获取选中的这个td:
xpath = "//table[@class = 'present-table']/tr[1]/td[2]/text()"
复制代码
以上是笔者分享的正确的写法之一,我们在浏览器的response里面就可以找到相同的xpath与此对应

你看,是没有 这个标签的,我们的xpath按照response的写法才是正确的,只是一般来是打开浏览器调试界面过去xpath最方便而已。对此,笔者去搜录了一下原因。
并不是全部的 都无法解析,如果在源码里面写入了 那我们原来的方法还是可行的。但源码没有写入的话,浏览器为了规范化,会自动在添加这个标签,我们写xpath的时候就要跳过这个标签。
目前笔者了解到,还有这一特性的标签还有 ,也需要注意。
5. 图片网址@src必须是列表格式
这又是笔者早早避过的坑,特此分享避坑经验。
这是大家约定俗称的一种写法,笔者也讲不出具体原理。对于@src的写法,笔者这里主要分享两种写法
# 第一种
src = response.xpath('//img/@src').extract()
# 第二种
src = [response.xpath('//img/@src').extract_first()]
复制代码
以上运用了extract()和extract_first()本身的特性
extract():这个方法返回的是一个数组list,里面包含了多个string,如果只有一个string,则返回['ABC']这样的形式。
extract_first():这个方法返回的是一个string字符串,是list数组里面的第一个字符串。
笔者自身倾向于第一种写法,写法简洁,同时能应对多个img的情况
* 小技巧——多界面数据如何传输
有时候我们爬虫里面的item,他的同类数据分布在各个网页之中,那么我们就需要 request.meta 来储存上一个parse中的item数据
我们从当前页面调用下一个页面时,使用如下的语句
yield scrapy.Request(the_href,callback=self.another_parse,meta={"item":item})
复制代码
就能成功的把我们的 item 传送到 another_parse 中去,以response.meta的形式存在,然后在这里重新定义一个 item 将此赋值给它就能完成传输了

Scrapy 5+1 ——五大坑附送一个小技巧的更多相关文章
- 快速掌握iOS API的一个小技巧
快速掌握iOS API的一个小技巧 周银辉 iOS SDK和Developer Library中提供了各个类以及函数的帮助文档,这很棒,但要想了解整个库的大体结构(比如UIKit下有哪些类,他们的继承 ...
- 【flash】关于flash的制作透明gif的一个小技巧
关于flash的制作透明gif的一个小技巧 或者说是一个需要注意的地方 1.导出影片|gif,得到的肯定是不透明的.2.想要透明背景,必须通过发布.3.flash中想要发布gif动画的话,不能有文字, ...
- POJ-3262 贪心的一个小技巧
Protecting the Flowers Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 3204 Accepted: ...
- 【每日一个小技巧】Python | input的提示信息换行输出,提示信息用变量表示
[每日一个小技巧]Python | input的提示信息换行输出,提示信息用变量表示 在书写代码的途中,经常会实现这样功能: 请输入下列选项前的序号: 1.选择1 2.选择2 3.选择3 在pytho ...
- 针对ACM输出格式的一个小技巧(对格式错误说不!)
printf("%d%c",bmax," \n"[i==n]); 上文中bmax为题目中需要输出的整形变量,可以脑补很多ans,max之类的,重点在于%c和后面 ...
- python笔记_查看函数调用栈的一个小技巧
一.背景 最近在看一个开源框架的源码,涉及到的内容非常杂乱,有的函数不知道是在什么时候被谁给调用了?调用的时候传入了什么参数?为了解决这个问题,写了一个小的装饰器. 二.实现 这个装饰器函数主要参考了 ...
- 从零开始学习html(十五)css样式设置小技巧——上
一.水平居中设置-行内元素 <!DOCTYPE HTML> <html> <head> <meta charset="utf-8"> ...
- C++模板类继承的一个小技巧
先说一下background前段时间想实现一个Sqlite localstorage的功能,对应不同的Model 实体有不同的table, 每一次sql操作的函数签名中会有model实体中的struc ...
- 使用dwr时动态生成table的一个小技巧
这篇随笔是我在07年写的,因为当时用了自己建设的blog,后来停止使用了,今天看到备份数据库还在,恢复出来放到这里.留着记录用. 我在使用DWR时,试了很多次都无法在动态生成的table中的一个或多个 ...
随机推荐
- Dart: 解析html字符串
安装html包 import 'package:http/http.dart' as http; import 'package:html/parser.dart' show parse; impor ...
- PAA房产,一家有温度的房产公司
PAUL ADAMS ARCHITECT房产(以下简称PAA,公司编号:07635831)对每一个客户从心出,为他们选择优质房源,为他们缔造家的温暖.PAA房产,是一家有温度的房产公司. PAA房产( ...
- 揭秘高倍矿币 Baccarat BGV,为何NGK DeFi的财富效应如此神奇?
作为区块链4.0代表的NGK公链,这次也将借助它自己的DeFi版块NGK Baccarat,开启属于它自己的千倍财富之旅. 如果说,比特币能让没有银行账户的人,可以在全球任何时间.地点都能自由进行交易 ...
- uniapp 滑动切换
说明:本案例的样式基于colorui组件库 感兴趣的小伙伴可以看下教程 colorui组件库开发文档或者csdn的文档,顺便再分享下 colorui的群资源 最近项目中需要用到滑动切换的效果,自己懒得 ...
- 全球首发—鸿蒙开源平台OpenGL
目录: 前言 背景 鸿蒙OpenGL-ISRC的结构 OpenGL-ISRC和鸿蒙SDK OpenGL的区别 OpenGL-ISRC的使用 前言 基于安卓平台的OpenGL(androidxref.c ...
- [Python学习笔记]文件的读取写入
文件与文件路径 路径合成 os.path.join() 在Windows上,路径中以倒斜杠作为文件夹之间的分隔符,Linux或OS X中则是正斜杠.如果想要程序正确运行于所有操作系统上,就必须要处理这 ...
- 一文读懂网管协议 - SNMP,NETCONF,RESTCONF
本文篇幅较长,主要涉及以下内容: 介绍传统 CLI 配置网络设备存在的挑战,网管协议出现的背景 SNMP 原理,交互过程,以及 trade-off NETCONF 架构,交互过程 RESTCONF 架 ...
- 使用 Tye 辅助开发 k8s 应用竟如此简单(五)
续上篇,这篇我们来进一步探索 Tye 更多的使用方法.本篇我们来了解一下如何在 Tye 中实现对分布式链路追踪. Newbe.Claptrap 是一个用于轻松应对并发问题的分布式开发框架.如果您是首次 ...
- 使用OkHttp和OkHttpGo获取OneNET云平台数据
图1是OneNET官网关于NB-IoT文档关于批量查询设备最新数据的介绍,可以看到GET方法的URL地址和两个头部信息(图2是Htto请求消息结构).所以在写url时,还要添加两行头部字段名,不然获取 ...
- ctf.show_web13(文件上传之.user.ini)
这是一道文件上传题,先二话不说丢个图片码,显示为 先考虑文件太小,用burp抓包,添加了一堆无用的东西后显示仍然是error file zise,直到上传正常图片依旧如此,考虑文件太大.将一句话木马修 ...