hash相关
转译☞:https://www.cs.rice.edu/~as143/COMP441_Spring17/scribe/lect4.pdf
1 大规模图片检索问题
基于树模型的算法在分类跟聚类中很受欢迎,然而对于高维数据来说,分类可能就不是那么有效了,因为有名声狼藉infamous维数诅咒的存在空间的划分随着维数成指数性增长,举个例子来说,如果一个图片有10个特征,对每个特征分成两组,总共就会呈现\(2^{10}\)个分类。所以说空间划分的方法在检索相似的高维数据并不是很有用。
2哈希算法
2.1detour,换个思路,考虑一下更简单的问题
假定我们有一个充满整数的数组,我们想要知道这个数组是否包含了一个确定的整数,我们有三个算法用来解决这个问题:
- \(O(N)\)的解法。 我们将给定的整数遍历数组中的所有整数进行两两对比。这个遍历花费了\(O(N)\)的时间
- \(O(logN)\)的解法。 为了减少时间复杂度,我们可以在检索前对数组数据进行预处理。我们将数组分割。尽管分割数组这个预处理需要花费时间,但是它有效的提升了检索的效率。
- \(O(1)\)的解法。 为了更一步提高效率我们可以在预处理过程中使用哈希映射,因此我们可以得到一个哈希表去检索。对于给定的一个整数,平均起来会花费\(O(1)\)的时间。
回到图片检索问题上。我们也可以使用哈希算法提高检索效率,。然而不同于传统哈希的是,这个哈希算法是用来比较两个图片的相似性,而不是精确的复制品。因为当用传统哈希算法时,两个非常相似的图片会拥有不同的哈希值,就不会满足相似性检索这个要求。
2.2标准哈希
一个哈希函数是一个映射:输入一个向量x并将其映射到一个离散的值Key
\]
传统哈希也会有这样的性质:
\]
传统的哈希不满足我们的要求,我们想要去评估两个图片经过哈希之后的相似性。传统的哈希会对两个不是完全相同但是非常相似的两张图片会返回不同的值。
2.3Locality sensitive hashing:广义化的哈希
LSH是哈希算法并且拥有概率松弛的性质probabilistic relaxation,LSH具有一下性质:
如果\(similaruty(x,y)\)高,那么\(probability(h(x)=h(y))\)也高,相反的也有
如果\(similaruty(x,y)\)低,那么\(probability(h(x)=h(y))\)也低。
不同于传统哈希的是,LSH以最大概率将两个相似的对象放入同一个桶中。通过LSH,我们可以对图片数据库进行预处理,以这种方法,我们可以降低图片数据的维度。在图片检索过程中,我们不用去计算两个图片的相似性,我们可以通过使用LSH计算哈希值来评估图片之间的相似性。
3formal LSH ,LSH的严格按表述
一个有效的近似最近邻检索工具,以locality sensitive hashing为底层理论。
LSH是一个函数族,它具有将相似的输入对象比不相似的输入对象有更高的几率在范围空间内发生碰撞。 考虑\(\cal H\)一个哈希函数族将\(\cal R^D\) 映射到离散集合[0,R-1]
定义:locality sensitive hashing LSH family ,如果\(for\ any\ x,y\in R^d\) ,然后不带偏好的从函数族\(\cal H\)选一个哈希函数h满足如下的性质:
- \(if\ sim(x,y)\geq s_0\ then\ P_{r_\cal H}(h(x)=h(y))\geq p_1\)
- \(if\ sim(x,y)\leq cs_0\ then\ P_{r_\cal H}(h(x)=h(y))\leq p_2\)
"Uniformly" means without applying any preference to a particular part of a region.
5关于相似性基本的想法
我们使用LSH对图片进行预处理。在图片库中,我们对,每一张图片都计算出哈希值,并且将他们放入桶中。为了提高精确度,我们重复几次这个的处理过程,得到多个哈希表,当一个要检索的图片来到时,我们使用相同的算法来计算出他的哈希值,再根据预处理得到的哈希表来找到相似文档。
因为LSH对两个相似图片以最大概率掉进同一个桶中,所以要要检索的图片掉入的桶中包含相似图片的概率就会非常高。
References
[1] http://cdn.iopscience.com/images/1749-4699/5/1/015004/full/csd422281fig1.jpg.
{kind=link}
[2] https://www.facebook.com/notes/facebook-engineering/10-billion-photos/30695603919.
[3] Jure Leskovec, Anand Rajaraman, and Jeffrey David Ullman.Mining of massive datasets.Cambridge University Press, 2014
转译☞:https://www.cs.rice.edu/~as143/COMP441_Spring17/scribe/lect5.pdf
1 通过哈希进行亚线性检索
LSH是一个函数族,它们具有将其定义域内的相似的输入对象在范围空间中有更高的碰撞概率。考虑\(\cal H\) 一个哈希函数族将\(\cal R^D\)映射到离散的空间[0,R-1]中。
定义:locality sensitive hashing LSH family ,如果\(for\ any\ x,y\in R^d\) ,然后不带偏好的从函数族\(\cal H\)选一个哈希函数h满足如下的性质:
- \(if\ sim(x,y)\geq s_0\ then\ P_{r_\cal H}(h(x)=h(y))\geq p_1\)
- \(if\ sim(x,y)\leq cs_0\ then\ P_{r_\cal H}(h(x)=h(y))\leq p_2\)
通过(K,L)LSH算法进行亚线性检索:对于近似最近邻检索问题,为了将检索时间在sub-linear time内,思想是创造哈希表。对象集\(\cal C\) ,通过LSH函数族创造哈希表。在经典的(K,L)-LSH算法中。我们生成了L个不同的元哈希函数\(B_j(x)=[h_{j1}(x);h_{j2}(x);...;h_{jK}(x)],j\in\{1,2,...,L\}\) ,总共具有KL个适当的位置敏感哈希函数,每个元哈希函数都是由从哈希函数族中简单的哈希值串接得到的。最后得到的就有L个哈希表,
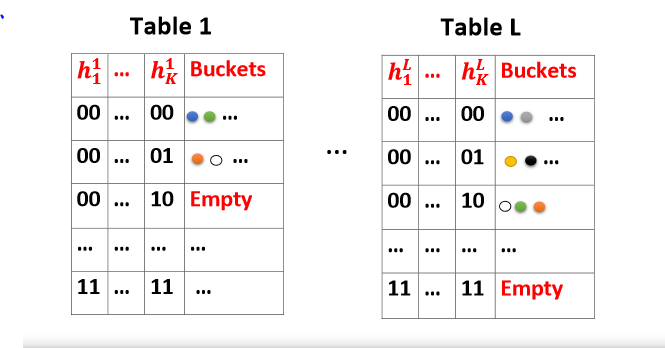
算法大体上可以分为两个阶段:
预处理阶段:我们从数据中通过将对象集所有的点,在第j个哈希表中方到位置\(B_j(x)\)中,构建L个哈希表,在表中,我们只存储点而不是向量,因为向量在存储方面不是很有效率。
检索阶段:给定检索的对象Q,我们report在\(B_j(Q)\ for\ j\in \{1,2,...,L\}\) 的所有点。这些点的个数一定比L多?我们不是扫描所有在对象集\(\cal C\) 中的数据,我们仅仅是探测L个不同的哈希桶,每一个哈希桶都分别在不同的哈希表中,因此它是亚线性的。
已经被证明了对于一个给定相似度度量对额并且适当的选择\(K=O(logn),L=O(n^\rho)\) 的LSH函数族,是非常有效率的。
定理1(sub-linear search)对于一个\((s_0,cs_0,p_1,p_2)\)-敏感的哈希函数,当\(K=O(logn),L=O(n^\rho)\),LSH解决近似最近邻检索仅需要\(O(n^\rho log_{1/p_2}n)\)检索时间,\(\rho=\frac{log(p_1)}{log(p_2)}<1\)
2基于shingle的呈现
可以由一系列关于字母的标记来呈现文档。举个例子,文档:”This is Rice University“对于k=2,也就是2-shingles集合{This is,is Rice,Rice University}
大多数网络数据都是稀疏的或者近似二元的。现代的大数据系统仅仅使用二元稀疏矩阵。
Jaccard 相似度
两个集合\(X,Y\subset\ \Omega\)的jaccard相似度得定义为:
\]
对于二元的向量,对于每一个数字(0 or 1)在向量的坐标下代表着这个方向的元素存在与否。也就有
\]
Minwise Hashing
算法:对于全体\(\Omega\)选取一个随机排列\(\pi\) ,i.e.
\]
minhash:
\]
也就是说每一次排列都会赋值新的行号,我们从最小的行号的那一行开始检索,出现第一个一个不为零的行号就是此列的minhash值
Binary vector view: the hash value of the vector is the smallest index that is not zero
Fingerprint:MinHash values can be used as fingerprint of data vector because the hash of one vector is independent of other vectors and Minhash values can be used to estimate similarity.
References
Shrivastava, Anshumali. COMP 441 Lecture5.pdf. 2017
Chapter 3 of Mining Massive Datasets Book (http://infolab.stanford.edu/~ullman/mmds/book.pdf)
hash相关的更多相关文章
- 字符串Hash相关
其实也并不是什么特别难的算法,但是我个人实在是不太喜欢字符串之类的东西(字符串神马的真的是麻烦),于是一直拖着不想看,然后模板题之类的也懒得做. Hash的思想其实也没什么复杂的,就是给定一系列字符串 ...
- redis Hash相关命令
- redis的hash, list, set类型相关命令
hash相关命令: 1. hset HSET key field value 将哈希表key中的域field的值设为value.如果key不存在,一个新的哈希表被创建并进行hset操作.如果域fiel ...
- Webpack中hash与chunkhash的区别,以及js与css的hash指纹解耦方案
文件的hash指纹通常作为前端静态资源实现增量更新的方案之一,Webpack是目前最流行的开源编译工具之一,其强大的功能也带来很多坑(当然,大部分麻烦其实都可以在官方文档中找到答案). 比如,在Web ...
- COGS 902 乐曲主题 题解 & hash入门贺
[题意] 给定一个长为n的序列,元素都是不超过88的正整数,求序列中主题的最大长度. 所谓主题是指在序列中出现了至少两次并且不相交的子串.特别的,主题可以变调,也就是说如果一个子串全部加上或减去一个数 ...
- 问题(一)---线程池,锁、堆栈和Hashmap相关
一.线程池: 多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力. 假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中 ...
- Redis in .NET Core 入门:(3) Hash
第1篇:https://www.cnblogs.com/cgzl/p/10294175.html 第2篇 String:https://www.cnblogs.com/cgzl/p/10297565. ...
- 曲演杂坛--HASH的一点理解
HASH,百度百科上做如下定义: Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列 ...
- redis数据类型[string 、list 、 set 、sorted set 、hash]
1. Keys redis本质上一个key-value db,所以我们首先来看看他的key. 首先key也是字符串类型,但是key中不能包括边界字符:由于key不是binary safe的字符串, ...
随机推荐
- python-Requests模块的使用
1. Requests简介 Requests模块是一个用于网络访问的模块,其实类似的模块有很多,比如urllib,urllib2,httplib,httplib2,他们基本都提供相似的功能,那为什么R ...
- Python:利用Entrez库筛选下载PubMed文献摘要
一个不是学生物的孩子来搞生物,当真是变成了一块废铁啊,但也是让我体会到了一把生物信息的力量. 废话不多说,开整! 任务:快速高效从PubMed上下载满足条件的文献PMID.标题(TI).摘要(AB). ...
- springboot中使用Filter、Interceptor和aop拦截REST服务
在springboot中使用rest服务时,往往需要对controller层的请求进行拦截或者获取请求数据和返回数据,就需要过滤器.拦截器或者切片. 过滤器(Filter):对HttpServletR ...
- 【JAVA基础】数组练习案例一
/* * * 输入5个学生成绩 * 计算出每个成绩与最高分的差距 * 根据差距分配等级 * * */ import java.util.Scanner; public class ArrayTask ...
- 总结MathType安装的一些小技巧
MathType在编辑数学公式确实很方便,因为它的功能很强大,能够进行多种数学符号编辑.但是在安装时我们多多少少会遇到一些问题,那这些问题该怎么解决呢?下面就让小编来分享公式编辑器安装的一些小技巧吧! ...
- MindManager思维导图应用到办公中需要注意什么
MindManager思维导图是一个易于使用的项目管理软件,能很好地提高项目组的工作效率和小组成员之间的协作性.接下来,小编就为大家介绍三个能利用好该思维导图软件办公的技巧. 一.审阅会议--合作办公 ...
- 使用iMindMap思维导图软件的活动策划模板制定策划方案
活动策划不单单是一个头脑风暴的过程,更是一个整合各项资源.条件的过程.因此我们可以合理的使用思维导图软件来做活动策划.iMindMap(Windows系统)思维导图软件提供了快捷而方便的活动策划模板, ...
- ResNet模型
ReeNet论文地址:Deep Residual Learning for Image Recognition Resnet的两种不同结构 上图左边的结构主要是针对深度较少的网络,当深度较大时则用右边 ...
- H5,Css小姐又作画了
用H5和CSS3做出自己名字缩写. <html> <head> <meta charset="utf-8"> <title>name ...
- P2943 [USACO09MAR]Cleaning Up G
一句话题意:将一个数列分成若干段,每段的不和谐度为该段内不同数字数量的平方,求不和谐度之和的最小值. 令 \(f_i\) 表示前 \(i\) 个数的最小答案,很容易就能写出暴力转移方程:\(f_i=\ ...