COS418, Distributed System, Go Language
go test -run Sequential
func TestSequentialSingle(t *testing.T) {
mr := Sequential("test", makeInputs(1), 1, MapFunc, ReduceFunc)
mr.Wait()
check(t, mr.files)
checkWorker(t, mr.stats)
cleanup(mr)
}
func Sequential(jobName string, files []string, nreduce int,
mapF func(string, string) []KeyValue,
reduceF func(string, []string) string,
) (mr *Master) {
mr = newMaster("master")
go mr.run(jobName, files, nreduce, func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF)
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, len(mr.files), reduceF)
}
}
}, func() {
mr.stats = []int{len(files) + nreduce}
})
return
}
func (mr *Master) run(jobName string, files []string, nreduce int,
schedule func(phase jobPhase),
finish func(),
) {
mr.jobName = jobName
mr.files = files
mr.nReduce = nreduce debug("%s: Starting Map/Reduce task %s\n", mr.address, mr.jobName) schedule(mapPhase)
schedule(reducePhase)
finish()
mr.merge() debug("%s: Map/Reduce task completed\n", mr.address) mr.doneChannel <- true
}
func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF)
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, len(mr.files), reduceF)
}
}
}
func() {
mr.stats = []int{len(files) + nreduce}
}
func reduceName(jobName string, mapTask int, reduceTask int) string {
return "mrtmp." + jobName + "-" + strconv.Itoa(mapTask) + "-" + strconv.Itoa(reduceTask)
}
func doMap(
jobName string, // the name of the MapReduce job
mapTaskNumber int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run
mapF func(file string, contents string) []KeyValue,
) {
dat, err := ioutil.ReadFile(inFile)
if err != nil {
debug("file open fail:%s", inFile)
} else {
kvs := mapF(inFile, string(dat))
partitions := make([][]KeyValue, nReduce)
for _ , kv:= range kvs {
r := int(ihash(kv.Key)) % nReduce
partitions[r] = append(partitions[r], kv)
}
for i := range partitions {
j, _ := json.Marshal(partitions[i])
f := reduceName(jobName, mapTaskNumber, i)
ioutil.WriteFile(f, j, 0644)
}
}
}

func mergeName(jobName string, reduceTask int) string {
return "mrtmp." + jobName + "-res-" + strconv.Itoa(reduceTask)
}
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTaskNumber int, // which reduce task this is
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
kvs := make(map[string][]string)
for m := 0; m < nMap; m++ {
fileName := reduceName(jobName, m, reduceTaskNumber)
dat, err := ioutil.ReadFile(fileName)
if err != nil {
debug("file open fail:%s", fileName)
} else {
var items []KeyValue
json.Unmarshal(dat, &items)
for _ , item := range items {
k := item.Key
v := item.Value
kvs[k] = append(kvs[k], v)
}
}
} // create the final output file
mergeFileName := mergeName(jobName, reduceTaskNumber)
file, err := os.Create(mergeFileName)
if err != nil {
debug("file open fail:%s", mergeFileName)
} // sort
var keys []string
for k := range kvs {
keys = append(keys, k)
}
sort.Strings(keys) enc := json.NewEncoder(file)
for _, key := range keys {
enc.Encode(KeyValue{key, reduceF(key, kvs[key])})
}
file.Close()
}
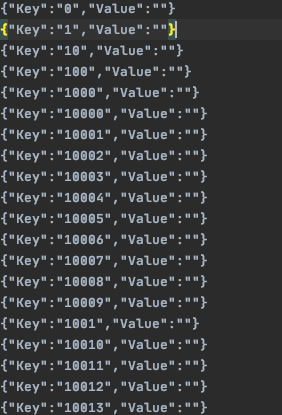
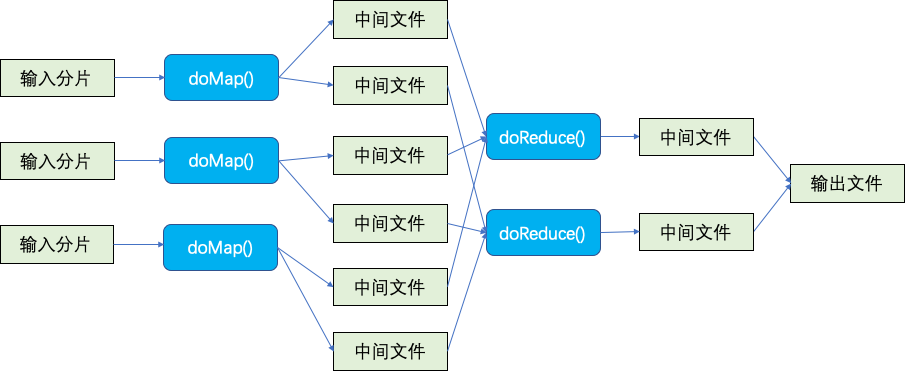
go run wc.go master sequential pg-*.txt
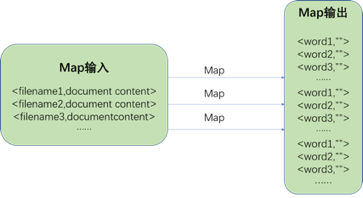
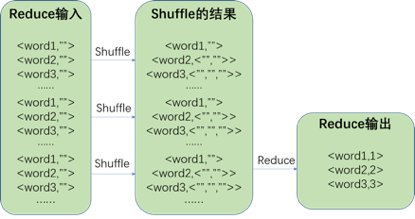
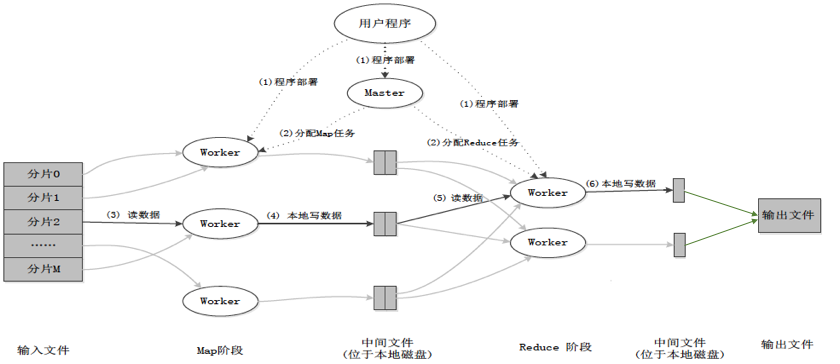
Reduce输入格式为list(<word,””> ),输出格式为list(<word,num>) 。处理过程如下图所示:
func mapF(document string, value string) (res []mapreduce.KeyValue) {
words := strings.FieldsFunc(value, func(r rune) bool {
return !unicode.IsLetter(r)
})
res = []mapreduce.KeyValue{}
for _, w := range words {
res = append(res, mapreduce.KeyValue{w, ""})
}
return res
}
func reduceF(key string, values []string) string {
return strconv.Itoa(len(values))
}
sort -n -k2 mrtmp.wcseq | tail -10
he: 34077
was: 37044
that: 37495
I: 44502
in: 46092
a: 60558
to: 74357
of: 79727
and: 93990
the: 154024
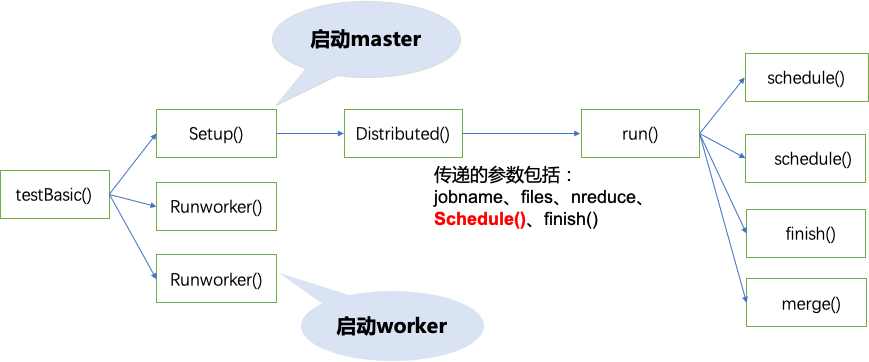
go test -run TestBasic
func TestBasic(t *testing.T) {
mr := setup()
for i := 0; i < 2; i++ {
go RunWorker(mr.address, port("worker"+strconv.Itoa(i)),
MapFunc, ReduceFunc, -1)
}
mr.Wait()
check(t, mr.files)
checkWorker(t, mr.stats)
cleanup(mr)
}
func setup() *Master {
files := makeInputs(nMap)
master := port("master")
mr := Distributed("test", files, nReduce, master)
return mr
}
func Distributed(jobName string, files []string, nreduce int, master string) (mr *Master) {
mr = newMaster(master)
mr.startRPCServer()
go mr.run(jobName, files, nreduce,
func(phase jobPhase) {
ch := make(chan string)
go mr.forwardRegistrations(ch)
schedule(mr.jobName, mr.files, mr.nReduce, phase, ch)
},
func() {
mr.stats = mr.killWorkers()
mr.stopRPCServer()
})
return
}
func(phase jobPhase) {
ch := make(chan string)
go mr.forwardRegistrations(ch)
schedule(mr.jobName, mr.files, mr.nReduce, phase, ch)
}
func() {
mr.stats = mr.killWorkers()
mr.stopRPCServer()
}
func (mr *Master) schedule(phase jobPhase) {
var ntasks int
var nios int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mr.files)
nios = mr.nReduce
case reducePhase:
ntasks = mr.nReduce
nios = len(mr.files)
}
debug("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, nios)
stats := make([]bool, ntasks)
currentWorker := 0
for {
count := ntasks
for i := 0; i < ntasks; i++ {
if !stats[i] {
mr.Lock()
numWorkers := len(mr.workers)
fmt.Println(numWorkers)
if numWorkers==0 {
mr.Unlock()
time.Sleep(time.Second)
continue
}
currentWorker = (currentWorker + 1) % numWorkers
Worker := mr.workers[currentWorker]
mr.Unlock()
var file string
if phase == mapPhase {
file = mr.files[i]
}
args := DoTaskArgs{JobName: mr.jobName, File: file, Phase: phase, TaskNumber: i, NumOtherPhase: nios}
go func(slot int, worker_ string) {
success := call(worker_, "Worker.DoTask", &args, new(struct{}))
if success {
stats[slot] = true
}
}(i, Worker)
} else {
count--
}
}
if count == 0 {
break
}
time.Sleep(time.Second)
}
debug("Schedule: %v phase done\n", phase)
}
go test -run Failure
go run ii.go master sequential pg-*.txt
func mapF(document string, value string) (res []mapreduce.KeyValue) {
words := strings.FieldsFunc(value, func(c rune) bool {
return !unicode.IsLetter(c)
})
WordDocument := make(map[string]string, 0)
for _,word := range words {
WordDocument[word] = document
}
res = make([]mapreduce.KeyValue, 0)
for k,v := range WordDocument {
res = append(res, mapreduce.KeyValue{k, v})
}
return
}
func reduceF(key string, values []string) string {
nDoc := len(values)
sort.Strings(values)
var buf bytes.Buffer;
buf.WriteString(strconv.Itoa(nDoc))
buf.WriteRune(' ')
for i,doc := range values {
buf.WriteString(doc)
if (i != nDoc-1) {
buf.WriteRune(',')
}
}
return buf.String()
}
head -n5 mrtmp.iiseq
A: 16 pg-being_ernest.txt,pg-dorian_gray.txt,pg-dracula.txt,pg-emma.txt,pg-frankenstein.txt,pg-great_expectations.txt,pg-grimm.txt,pg-huckleberry_finn.txt,pg-les_miserables.txt,pg-metamorphosis.txt,pg-moby_dick.txt,pg-sherlock_holmes.txt,pg-tale_of_two_cities.txt,pg-tom_sawyer.txt,pg-ulysses.txt,pg-war_and_peace.txt
ABC: 2 pg-les_miserables.txt,pg-war_and_peace.txt
ABOUT: 2 pg-moby_dick.txt,pg-tom_sawyer.txt
ABRAHAM: 1 pg-dracula.txt
ABSOLUTE: 1 pg-les_miserables.txt
COS418, Distributed System, Go Language的更多相关文章
- 分布式系统(Distributed System)资料
这个资料关于分布式系统资料,作者写的太好了.拿过来以备用 网址:https://github.com/ty4z2008/Qix/blob/master/ds.md 希望转载的朋友,你可以不用联系我.但 ...
- 译《Time, Clocks, and the Ordering of Events in a Distributed System》
Motivation <Time, Clocks, and the Ordering of Events in a Distributed System>大概是在分布式领域被引用的最多的一 ...
- Aysnc-callback with future in distributed system
Aysnc-callback with future in distributed system
- Note: Time clocks and the ordering of events in a distributed system
http://research.microsoft.com/en-us/um/people/lamport/pubs/time-clocks.pdf 分布式系统的时钟同步是一个非常困难的问题,this ...
- 分布式学习材料Distributed System Prerequisite List
接下的内容按几个大类来列:1. 文件系统a. GFS – The Google File Systemb. HDFS1) The Hadoop Distributed File System2) Th ...
- Notes on Distributed System -- Distributed Hash Table Based On Chord
task: 基于Chord实现一个Hash Table 我负责写Node,队友写SuperNode和Client.总体参考paper[Stoica et al., 2001]上的伪代码 FindSuc ...
- 「2014-2-23」Note on Preliminary Introduction to Distributed System
今天读了几篇分布式相关的内容,记录一下.非经典论文,非系统化阅读,非严谨思考和总结.主要的着眼点在于分布式存储:好处是,跨越单台物理机器的计算和存储能力的限制,防止单点故障(single point ...
- Note on Preliminary Introduction to Distributed System
今天读了几篇分布式相关的内容,记录一下.非经典论文,非系统化阅读,非严谨思考和总结.主要的着眼点在于分布式存储:好处是,跨越单台物理机器的计算和存储能力的限制,防止单点故障(single point ...
- Time, Clocks, and the Ordering of Events in a Distributed System
作者:Leslie Lamport(非常厉害的老头了) 在使用消息进行通信的分布式系统中,使用物理时钟对不同process进行时间同步与事件排序是非常困难的.一是因为不同process的时钟有差异,另 ...
随机推荐
- layui常用插件(一) 轮播图
轮播图 <html lang="en"> <head> <meta charset="UTF-8"> <meta ht ...
- Python之生成器、迭代器
生成器 生成器类似返回值为数组的一个函数,这个函数可以接受参数,可被调用,但只能产生一个值,所以大大节省内存. 生成器表达式的语法非常简单,只需要将列表推导式的中括号改成小括号就可以了 [x+x fo ...
- Django学习路31_使用 locals 简化 context 写法,点击班级显示该班学生信息
urls 中 进行注册 url(r'grades',views.grades) views 中编写函数 def grades(request): grades_list = Grade.objects ...
- Python os.mkdir() 方法
概述 os.mkdir() 方法用于以数字权限模式创建目录.默认的模式为 0777 (八进制).高佣联盟 www.cgewang.com 语法 mkdir()方法语法格式如下: os.mkdir(pa ...
- PHP similar_text() 函数
实例 计算两个字符串的相似度并返回匹配字符的数目: <?php高佣联盟 www.cgewang.comecho similar_text("Hello World",&quo ...
- 一个轻量级的基于RateLimiter的分布式限流实现
上篇文章(限流算法与Guava RateLimiter解析)对常用的限流算法及Google Guava基于令牌桶算法的实现RateLimiter进行了介绍.RateLimiter通过线程锁控制同步,只 ...
- charles抓取HTTPS设置,详细踩坑版
写这篇文章的背景就是,每次我在一台新电脑上用charles抓包时,总是因为各种原因无法抓到https请求,每个百度出来的回答又不是那么详细,需要通过几篇回答才能解决过程中的各种问题,所以把自己的安装经 ...
- .Net Core 实体生成器
实体生成器是什么? 实体生成器的功能就是自动将数据库中的表以及字段 转化成我们 高级编程语言中的实体类. 我们为什么要用实体生成器 在.net core开发环境下,我们可以使用efcore这个orm来 ...
- Spring MVC method POST no supported
首先:一些隐含的知识点要知道 POST 的不支持对静态资源的访问[默认情况下是这样,个人不太了解,仅总结大概思路],如果是post 而响应的是个静态资源,则很多情况下出现这种错误 因此在使用POST应 ...
- resultMap的用法以及关联结果集映射
resultType resultType可以把查询结果封装到pojo类型中,但必须pojo类的属性名和查询到的数据库表的字段名一致. 如果sql查询到的字段与pojo的属性名不一致,则需要使用res ...