hadoop 性能调优与运维
hadoop 性能调优与运维
. 硬件选择
. 操作系统调优与jvm调优
. hadoop参数调优. hadoop运维
硬件选择
1) hadoop运行环境
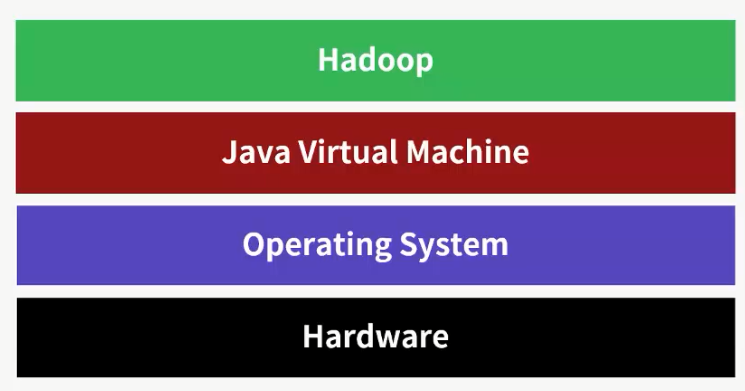
2) 原则一: 主节点可靠性要好于从节点
原则二:多路多核,高频率cpu、大内存,
namenode 100万文件的元数据要消耗800M内存,内存决定了集群保存文件数的总量, resourcemanager同时运行的作业会消耗一定的内存。
datanode 的内存需要根据cpu的虚拟核数(vcore) 进行配比,CPU的vcore数计算公式为=cpu个数 * 单cpu核数* HT(超线程)
内存容量大小 = vcore数 * 2GB(至少2GB)
原则三: 根据数据量确定集群规模
一天增加10GB, 365天,原数据1TB,replacation=3, 1.3 mapreduce 计算完保存的数据,规划容量
(1TB + 10GB*365)*3 *1.3 =17.8TB
如果一台datanode的存储空间为2TB, 18/2= 9
总节点为 = 9+2 =11
还要考虑作业并不是均匀分布的, 有可能会倾斜到某一个时间段,需要预留资源
原则四: 不要让网路I/O 成为瓶颈
hadoop 作业通常是 I/O密集型而非计算密集型, 瓶颈通常集中出现在I/O上, 计算能力可以通过增加新节点进行线性扩展,要注意网络设别处理能力。

操作系统调优
1 避免使用swap 分区 将hadoop守护进程的数据交换到硬盘的行为可能会导致操作超时。
2 调整内存分配策略
操纵系统内核根据vm.oversommit_memory 的值来决定分配策略,并且通过vm.overcommit_ratio的值来设定超过物理内存的比例。
3. 修改net.core.somaxconn参数
该参数表示socker监听backlog的上限,默认为128,socker的服务器会一次性处理backlog中的所有请求,hadoop的ipc.server.listen.queue.size参数和linux的net.core.somaxconn
参数控制了监听队列的长度,需要调大。
4.增大同时打开文件描述符的上限
对内核来说,所有打开的文件都通过文件描述符引用,文件描述符是一个非负整数,hadoop的作业经常会读写大量文件,需要增大同时打开文件描述符的上限。
5.选择合适的文件系统,并禁用文件的访问时间
ext4 xfs ,文件访问时间可以让用户知道那些文件近期被查看或修改, 但对hdfs来说, 获取某个文件的某个块 被修改过,没有意义,可以禁用。
6. 关闭THP (transparent Huge Pages)
THP 是一个使管理 Huge Pages自动化的抽象层, 它会引起cpu占用率增大, 需要关闭。
echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defraghadoop参数调优
HDFS调优
. 设置合理的块大小(dfs.block.size)
. 将中间结果目录设置为分布在多个硬盘以提升写入速度(mapred.local.dir)
. 设置datanode处理RPC的线程数,大集群可以适当加大(dfs.datanode.handler.count),默认为3,可以适当加大为10
. 设置namenode 能同时处理的请求数,(dfs.namenode.handler.count),为集群模式的自然对数(lnN)的20倍。 YARN调优
yarn的资源表示模型为ceontainer(容器),container 将资源抽象为两个维度,内存和虚拟cpu(vcore)
. 兼容各种计算框架
. 动态分配资源,减少资源浪费 容器内存
yarn.nodemanager.resource.memory-mb 最小容器内存
yarn.scheduler.minimum-allocation-mb 容器内存增量
yarn.scheduler.increment-allocation-mb 最大容器内存
yarn.scheduler.maximum-allocation-mb 容器虚拟cpu内核
yarn.nodemanager.resource.cpu-vcores 最小容器虚拟cpu内核数量
yarn.scheduler.minimum-allocation-vcores 容器虚拟cpu内核增量
yarn.scheduler.increment-allocation-vcores 最大容器虚拟cpu内核数量
yarn.scheduler.maximum-allocation-vcores MapReduce调优,调优三大原则 .增大作业并行程度
.给每个任务足够的资源
. 在满足前2个条件下,尽可能的给shuffle预留资源
hadoop运维
基础运维
. 启动和体质hadoop (包括hdfs)
./start-all.sh
./stop-all.sh .启动/停止 hdfs
./start-dfs.sh
./stop-dfs.sh .启动/停止 单个hdfs进程
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh stop namenode ./hadoop-daemon.sh start datanode
./hadoop-daemon.sh stop datanode 启动和关闭 yarn进程
sbin/start-yarn.sh 主
sbin/yarn-daemon.sh start resourcemanager 第二节点 集群节点动态扩容和卸载
.增加datanode
修改slave,添加新的datanode
./hadoop-daemon.sh start datanode 启动datanode
./hadoop dfsadmin -refreshNodes 通知namenode 增加了一个节点 2. 卸载datanode
stop datanode 命令只能停止datanode, 并不能把数据完全的迁移出来 1). 修改配置 dfs.hosts 和 dfs.hosts.exclude,把将要卸载的datanode ip添加到dfs.hosts 和dfs.hosts.exclude 末尾,执行
./hadoop dfsadmin -refresNodes #数据转移,使用web端口可以查看迁移进度 2). 停止服务器
./hadoop-deamon.sh stop datanode 3). 把dfs.hosts 和 dfs.hosts.exclude 中的 卸载的datanode ip地址删除 4). 再次执行
./haddop dfsadmin -refresNodes 5).增加 yarn 的nodemanager
修改slave文件, 直接启动
./yarn-daemon.sh start nodemanager 6).卸载nodemanger
直接停止即可
./yarn-daemon.sh start nodemanager ./hadoop-daemon.sh
namenode|secondarynamenode|datanode|journalnode|dfs|dfsadmin|fsck|balancer|zkfc) yarn-daemon.sh
resourcemanager|nodemanager
yarn 第二节点启动命令
yarn-daemon.sh start resourcemanager
常见的运维技巧
1. 查看日志
2.清理临时文件
hdfs 的临时文件路径:/data/hadoop/tmp/mapred/staging
本地临时文件路径: {mapred.local.dir}/mapred/userlogs 3.定期执行数据均衡脚本
hadoop 性能调优与运维的更多相关文章
- hadoop性能调优
1.平衡磁盘利用率 hadoop balancer -Threshold 20 或者 sh $HADOOP_HOME/bin/start-balancer.sh –t 20% 参数20是比例参数,表示 ...
- 优化系统资源ulimit《高性能Linux服务器构建实战:运维监控、性能调优与集群应用》
优化系统资源ulimit<高性能Linux服务器构建实战:运维监控.性能调优与集群应用> 假设有这样一种情况,一台Linux 主机上同时登录了10个用户,在没有限制系统资源的情况下,这10 ...
- 优化Linux内核参数/etc/sysctl.conf sysctl 《高性能Linux服务器构建实战:运维监控、性能调优与集群应用》
优化Linux内核参数/etc/sysctl.conf sysctl <高性能Linux服务器构建实战:运维监控.性能调优与集群应用> http://book.51cto.com/ar ...
- 大厂运维必备技能:PB级数据仓库性能调优
摘要:众所周知,数据量大了之后,性能是大家关注的一点,所以我们在业务开发的时候,特别关注性能,做为一个架构师,必须对性能要了解,要懂.才能设计出高性能的业务系统. 一.GaussDB分布式架构 所谓集 ...
- [大牛翻译系列]Hadoop(16)MapReduce 性能调优:优化数据序列化
6.4.6 优化数据序列化 如何存储和传输数据对性能有很大的影响.在这部分将介绍数据序列化的最佳实践,从Hadoop中榨出最大的性能. 压缩压缩是Hadoop优化的重要部分.通过压缩可以减少作业输出数 ...
- [大牛翻译系列]Hadoop(8)MapReduce 性能调优:性能测量(Measuring)
6.1 测量MapReduce和环境的性能指标 性能调优的基础系统的性能指标和实验数据.依据这些指标和数据,才能找到系统的性能瓶颈.性能指标和实验数据要通过一系列的工具和过程才能得到. 这部分里,将介 ...
- Hadoop作业性能指标及參数调优实例 (二)Hadoop作业性能调优7个建议
作者:Shu, Alison Hadoop作业性能调优的两种场景: 一.用户观察到作业性能差,主动寻求帮助. (一)eBayEagle作业性能分析器 1. Hadoop作业性能异常指标 2. Hado ...
- hbase性能调优(1)
hbase性能调优 标签: hbase 性能调优 | 发表时间:2014-05-17 15:10 | 作者:无尘道长 分享到: 出处:http://www.iteye.com 一.服务端调优 1.参数 ...
- 记一次Web服务的性能调优
前言 一个项目在经历开发.测试.上线后,当时的用户规模还比较小,所以刚刚上线的项目一般会表现稳定.但是随着时间的推移,用户数量的增加,qps的增加等因素会造成项目慢慢表现出网页半天无响应的状况.在之前 ...
随机推荐
- NPOI导出Excel - 自动适应中文宽度(帮助类下载)
前言 做了好几个Excel.Word导出,用了HTTP流导出伪Excel文件.用过Office组件(这东西在生产环境下相当麻烦,各种权限,**). 最后决定使用NPOI组件来导出,好处很多很多了,这里 ...
- [参考]wget下载整站
wget -m -e robots=off -U "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1.6) Gecko/200 ...
- 在Salesforce中为Object创建Master-Detail(Child-Relationship)关联关系
在Salesforce中可以将两个Object建立起一对多的关联关系,本篇文章就简单的叙述一下将两个Object(EricSunObj & EricSunObjC)设置成Master-Deta ...
- HDU 2082 找单词 (多重背包)
题意:假设有x1个字母A, x2个字母B,..... x26个字母Z,同时假设字母A的价值为1,字母B的价值为2,..... 字母Z的价值为26.那么,对于给定的字母,可以找到多少价值<=50的 ...
- 浏览器-09 javascript引擎和Chromium网络栈
语言的运行 C/C++语言 使用编译器直接将它们编译成本地代码(机器指令),这是由开发人员在代码编写完成之后实施; 用户只是使用这些编译好的本地代码,这些本地代码被系统的加载器加载执行,由操作系统调度 ...
- mysql解压版安装
1.下载MySQL解压版(32位) http://dev.mysql.com/downloads/mysql/
- VBA 获取Sheet最大行
compared all possibilities with a long test sheet: 0,140625 sec for lastrow = calcws.Cells.Find(&quo ...
- 1.0 iOS中的事件
本文并非最终版本,如有更新或更正会第一时间置顶,联系方式详见文末 如果觉得本文内容过长,请前往本人 “简书” 在用户使用app过程中,会产生各种各样的事件,iOS中的事件可以分为3大类型: UIK ...
- Validation-jQuery表单验证插件使用方法
http://www.cnblogs.com/shuang121/archive/2012/04/23/2466628.html 作用 jquery.validate是jquery旗下的一个验证框架, ...
- JSON字符串语法
JSON 语法是 JavaScript 对象表示语法的子集. 数据在键/值对中展示, 多个数据由逗号分隔, 花括号保存一个对象, 方括号保存一个数组 JSON具有以下形式: 1. 对象(object) ...