队列的存储结构和常见操作(c 语言实现)
一、队列(queue)
队列和栈一样,在实际程序的算法设计和计算机一些其他分支里,都有很多重要的应用,比如计算机操作系统对进程 or 作业的优先级调度算法,对离散事件的模拟算法,还有计算机主机和外部设备运行速度不匹配的问题解决等,很多很多。其实队列的本质还是线性表!只不过是一种特殊的或者说是受限的线性表,是这样的:
1)、限定在表的一端插入、另一端删除。 插入的那头就是队尾,删除的那头就是队头。也就是说只能在线性表的表头删除元素,在表尾插入元素。形象的说就是水龙头和水管,流水的水嘴是队头,进水的泵是队尾,管子中间不漏水不进水。这样呲呲的流动起来,想想就是这么个过程。
2)、先进先出 (FIFO结构)。显然我们不能在表(队列)的中间操作元素,只能是在尾部进,在头部出去,还可以类似火车进隧道的过程。(first in first out = FIFO 结构)
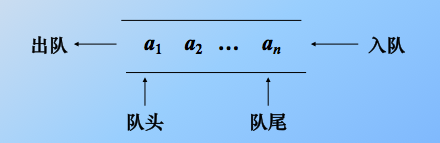
注意,当队列没有元素的时候,我们就说队列是空队列。
1、双端队列
double-ended queue:限定插入和删除在表的两端进行,也是先进先出 (FIFO)结构,类似铁路的转轨网络。实际程序中应用不多。
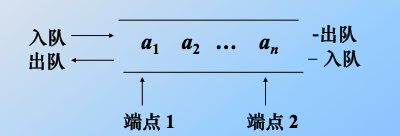
这种结构又细分为三类:
1)、输入受限的双端队列:一个端点可插入和删除,另一个端点仅可删除。
2)、输出受限的双端队列:一个端点可插入和删除,另一个端点仅可插入。
3)、等价于两个栈底相连接的栈:限定双端队列从某个端点插入的元素,只能在此端点删除。
2、链队(有链的地方,就有指针)
用链表表示的队列,限制仅在表头删除和表尾插入的单链表。一个链队列由一个头指针和一个尾指针唯一确定。(因为仅有头指针不便于在表尾做插入操作)。为了操作的方便,也给链队列添加一个头结点,因此,空队列的判定条件是:头指针和尾指针都指向头结点。
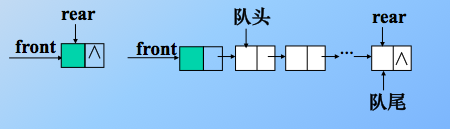
之前的链式结构,总是使用一个结点的结构来表示链表,其实不太方便,这里使用新的存储结构。定义一个结点结构,和一个队列结构。两个结构嵌套。
#ifndef queue_Header_h
#define queue_Header_h
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h> //队列的结点结构
typedef struct Node{
int data;
struct Node *next;
} Node, *Queue; //队列的结构,嵌套
typedef struct{
Queue front;
Queue rear;
} LinkQueue; //初始化
//开始必然是空队列,队尾指针和队头指针都指向头结点
void initQueue(LinkQueue *queue)
{
//初始化头结点
queue->front = queue->rear = (Queue)malloc(sizeof(Node)); if (NULL == queue->front) {
exit();
} queue->front->next = NULL;
} //判空
bool isEmpty(LinkQueue queue)
{
return queue.rear == queue.front ? true : false;
} //入队,只在一端入队,另一端出队,同样入队不需要判满
void insertQueue(LinkQueue *queue, int temp)
{
Queue q = (Queue)malloc(sizeof(Node)); if (NULL == q) {
exit();
}
//插入数据
q->data = temp;
q->next = NULL;
//rear 总是指向队尾元素
queue->rear->next = q;
queue->rear = q;
} //出队,需要判空
void deleteQueue(LinkQueue *queue)
{
Queue q = NULL; if (!isEmpty(*queue)) {
q = queue->front->next;
queue->front->next = q->next;
//这句很关键,不能丢
if (queue->rear == q) {
queue->rear = queue->front;
} free(q);
}
} //遍历
void traversal(LinkQueue queue)
{
int i = ;
Queue q = queue.front->next; while (q != NULL) {
printf("队列第%d个元素是:%d\n", i, q->data);
q = q->next;
i++;
}
} //销毁
void destoryQueue(LinkQueue *queue)
{
while (queue->front != NULL) {
queue->rear = queue->front->next;
free(queue->front);
queue->front = queue->rear;
} puts("销毁成功!");
} #endif
测试
#include "queue.h" int main(int argc, const char * argv[])
{
LinkQueue queue;
puts("初始化队列 queue");
initQueue(&queue);
traversal(queue); puts("队尾依次插入0 1 2 3");
insertQueue(&queue, );
insertQueue(&queue, );
insertQueue(&queue, );
insertQueue(&queue, );
traversal(queue); puts("先进先出,删除队列从头开始, 0 ");
deleteQueue(&queue);
traversal(queue); puts("先进先出,删除队列从头开始, 1 ");
deleteQueue(&queue);
traversal(queue); puts("先进先出,删除队列从头开始, 2 ");
deleteQueue(&queue);
traversal(queue); puts("先进先出,删除队列从头开始, 3");
deleteQueue(&queue);
traversal(queue); destoryQueue(&queue);
return ;
}
结果:
初始化队列 queue
队尾依次插入0 1 2 3
队列第1个元素是:0
队列第2个元素是:1
队列第3个元素是:2
队列第4个元素是:3
先进先出,删除队列从头开始, 0
队列第1个元素是:1
队列第2个元素是:2
队列第3个元素是:3
先进先出,删除队列从头开始, 1
队列第1个元素是:2
队列第2个元素是:3
先进先出,删除队列从头开始, 2
队列第1个元素是:3
先进先出,删除队列从头开始, 3
销毁成功!
Program ended with exit code: 0
3、顺序队列
限制仅在表头删除和表尾插入的顺序表,利用一组地址连续的存储单元依次存放队列中的数据元素。因为队头和队尾的位置是变化的,所以也要设头、尾指针。
初始化时的头尾指针,初始值均应置为 0。 入队尾指针增 1 ,出队头指针增 1 。头尾指针相等时队列为空,在非空队列里,头指针始终指向队头元素,尾指针始终指向队尾元素的下一位置。
初始为空队列,那么头尾指针相等。
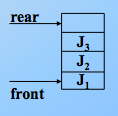
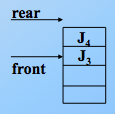
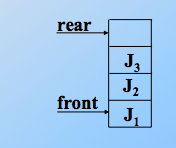
入队,那么尾指针加1,头指针不变。先进先出,J1先进队,则 rear+1,尾指针始终指向队尾元素的下一位!如,J2进队,rear 继续+1,J3进队,尾指针继续加1,如图
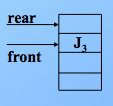
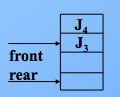
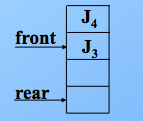
出队,则尾指针不变,头指针加1,注意这里都是加1,先进先出原则,J1先删除,front+1,指向了 J2,J2删除,front+1指向了 J3,如图
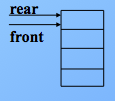
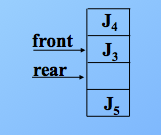
最后,J3删除,则头指针再次和尾指针相等,说明队列空了。如图
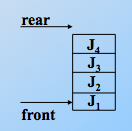
在顺序队列中,当尾指针已经指向了队列的最后一个位置的下一位置时,若再有元素入队,就会发生“溢出”。如图位置,再次入队,就会溢出。
4、循环队列的诞生
顺序队列的 “假溢出” 问题:队列的存储空间未满,却发生了溢出。很好理解,比如 rear 现在虽然指向了最后一个位置的下一位置,但是之前队头也删除了一些元素,那么队头指针经历若干次的 +1 之后,遗留下了很多空位置,但是顺序队列还在傻乎乎的以为再有元素入队,就溢出呢!肯定不合理。故循环队列诞生!
解决“假溢出”的问题有两种可行的方法:
(1)、平移元素:把元素平移到队列的首部。效率低。否决了。
(2)、将新元素插入到第一个位置上,构成循环队列,入队和出队仍按“先进先出”的原则进行。操作效率高、空间利用率高。
虽然使用循环队列,解决了假溢出问题,但是又有新问题发生——判空的问题,因为仅凭 front = rear 不能判定循环队列是空还是满。比如如图:
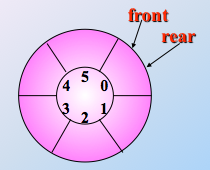 这是空循环队列的样子
这是空循环队列的样子
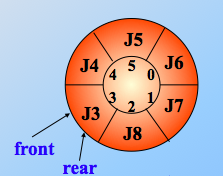 这是满循环队列的样子
这是满循环队列的样子
解决办法:
(1)、另设一个布尔变量以区别队列的空和满;
(2)、少用一个元素的空间,约定入队前测试尾指针在循环下加 1 后是否等于头指针,若相等则认为队满;(最常用)
(3)、使用一个计数器记录队列中元素的总数。
对于第2个方案,必须牺牲一个元素的空间,那么入队的时候需要测试,循环意义下的加 1 操作可以描述为:
if (rear + = MAXQSIZE)
rear = ;
else
rear ++;
利用模运算可简化为:
rear = (rear + )% MAXQSIZE
基本操作
#ifndef ___queue_Header_h
#define ___queue_Header_h
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 5 typedef struct{
int *base;
int rear;//如果队列不空,指向队尾元素的下一个位置
int front;//初始的时候指向表头
} CirularQueue; //初始化
void initQueue(CirularQueue *queue)
{
queue->base = (int *)malloc(MAX_SIZE*sizeof(int)); if (NULL == queue->base) {
exit();
} queue->front = queue->rear = ;
}
求长度
//求长度
int getLength(CirularQueue queue)
{
//这样把所以的情况都考虑到了
return (queue.rear - queue.front + MAX_SIZE) % MAX_SIZE;
}
第一种情况,长度的求法
第二种情况,长度的求法,利用模运算,两个情况合二为一!
//入队,先判满
void insertQueue(CirularQueue *queue, int e)
{
if ((queue->rear + ) % MAX_SIZE == queue->front) {
puts("循环队列是满的!");
}
else
{
queue->base[queue->rear] = e;
queue->rear = (queue->rear + ) % MAX_SIZE;
}
}
如下时为满,损失一个空间,不存储元素。方便判满
//出队
void deleteQueue(CirularQueue *queue)
{
if (queue->front == queue->rear) {
puts("队列是空的!");
}
else
{
queue->front = (queue->front + ) % MAX_SIZE;
}
} //遍历
void traversal(CirularQueue queue)
{
int q = queue.front; for (int i = ; i < getLength(queue); i++) {
printf("循环队列的第%d个元素为%d\n", i + , queue.base[q]);
q++;
}
} #endif
测试
#include "Header.h"
int main(int argc, const char * argv[]) {
CirularQueue queue;
puts("循环队列初始化:");
initQueue(&queue);
puts("循环队列初始化后长度:");
printf("%d\n", getLength(queue));
puts("循环队列5个元素入队,总长度为5,但是损失一个位置空间,实际存储4个元素。先进先出原则:");
puts("循环队列元素0入队");
insertQueue(&queue, );
puts("循环队列元素1入队");
insertQueue(&queue, );
puts("循环队列元素2入队");
insertQueue(&queue, );
puts("循环队列元素3入队");
insertQueue(&queue, );
puts("循环队列元素遍历:");
traversal(queue);
puts("循环队列元素继续入队,无法完成:");
insertQueue(&queue, );
puts("循环队列元素0出队之后,先进先出原则:");
deleteQueue(&queue);
traversal(queue);
puts("循环队列元素1出队之后,先进先出原则:");
deleteQueue(&queue);
traversal(queue);
puts("循环队列元素2出队之后,先进先出原则:");
deleteQueue(&queue);
traversal(queue);
puts("循环队列元素3出队之后,先进先出原则:");
deleteQueue(&queue);
traversal(queue);
puts("4个元素全部删除,循环队列已经空了:");
deleteQueue(&queue);
traversal(queue);
return ;
}
结果;
循环队列初始化:
循环队列初始化后长度:
0
循环队列5个元素入队,总长度为5,但是损失一个位置空间,实际存储4个元素。先进先出原则:
循环队列元素0入队
循环队列元素1入队
循环队列元素2入队
循环队列元素3入队
循环队列元素遍历:
循环队列的第1个元素为0
循环队列的第2个元素为1
循环队列的第3个元素为2
循环队列的第4个元素为3
循环队列元素继续入队,无法完成:
循环队列是满的!
循环队列元素0出队之后,先进先出原则:
循环队列的第1个元素为1
循环队列的第2个元素为2
循环队列的第3个元素为3
循环队列元素1出队之后,先进先出原则:
循环队列的第1个元素为2
循环队列的第2个元素为3
循环队列元素2出队之后,先进先出原则:
循环队列的第1个元素为3
循环队列元素3出队之后,先进先出原则:
4个元素全部删除,循环队列已经空了:
队列是空的!
Program ended with exit code: 0
小结:
若用户需要循环队列,那么要设置队列的最大长度,否则无法完成判断空,如果用户不知道最大长度是多少,那么应该使用链队。队列在程序设计中和栈一样,应用很多,未完待续。
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!

队列的存储结构和常见操作(c 语言实现)的更多相关文章
- 栈的存储结构和常见操作(c 语言实现)
俗话说得好,线性表(尤其是链表)是一切数据结构和算法的基础,很多复杂甚至是高级的数据结构和算法,细节处,除去数学和计算机程序基础的知识,大量的都在应用线性表. 一.栈 其实本质还是线性表:限定仅在表尾 ...
- 动态单链表的传统存储方式和10种常见操作-C语言实现
顺序线性表的优点:方便存取(随机的),特点是物理位置和逻辑为主都是连续的(相邻).但是也有不足,比如:前面的插入和删除算法,需要移动大量元素,浪费时间,那么链式线性表 (简称链表) 就能解决这个问题. ...
- 队列的存储结构的实现(C/C++实现)
存档 #include "iostream.h" #include "stdlib.h" #define max 20 typedef char elemtyp ...
- Berkeley DB的数据存储结构——哈希表(Hash Table)、B树(BTree)、队列(Queue)、记录号(Recno)
Berkeley DB的数据存储结构 BDB支持四种数据存储结构及相应算法,官方称为访问方法(Access Method),分别是哈希表(Hash Table).B树(BTree).队列(Queue) ...
- C++编程练习(6)----“实现简单的队列的链式存储结构“
队列的链式存储结构,其实就是线性表的单链表,只不过它只能尾进头出.简称链队列. 实现代码如下: /* LinkQueue.h 头文件 */ #include<iostream> #defi ...
- LinkedList实现队列存储结构
package com.tercher.demo; import java.util.LinkedList; public class Queue { //用LinkedList 实现队列的数据存储结 ...
- Java队列存储结构及实现
一.队列(Queue) 队列是一种特殊的线性表,它只允许在表的前段(front)进行删除操作,只允许在表的后端(rear)进行插入操作.进行插入操作的端称为队尾,进行删除操作的端称为队头. 对于一个队 ...
- 图的存储结构与操作--C语言实现
图(graph)是一种比树结构还要复杂的数据结构,它的术语,存储方式,遍历方式,用途都比较广,所以如果想要一次性完成所有的代码,那代码会非常长.所以,我将分两次来完成图的代码.这一次,我会完成图的五种 ...
- Zookeeper的基本原理(zk架构、zk存储结构、watch机制、独立安装zk、集群间同步复制)
1.Hbase集群的高可用性与伸缩性 HBase可以实现对Regionserver的监控,当个别Regionserver不可访问时,将其负责的分区分给其他Regionsever,其转移过程较快,因为只 ...
随机推荐
- mavan 命令行创建项目
1)创建简单maven项目 mvn archetype:create -DgroupId=cn.everlook.myweb -DartifactId=myweb -DpackageName=cn.e ...
- php下xcache的安装
下载xcache: wget http://xcache.lighttpd.net/pub/Releases/3.2.0/xcache-3.2.0.tar.gz 安装: tar zxvf xcache ...
- RCP:给GEF编辑器添加拖拽辅助线
当图形边缘碰触时,会产生一条帮助拖拽的辅助线 这里需要三个类: 1.SnapToGeomotry 2.SnapToGuide(非必须) 3.SnapFeedbackPolicy
- ENode 2.0 - 第一个真实案例剖析-一个简易论坛(Forum)
前言 经过不断的坚持和努力,ENode 2.0的第一个真实案例终于出来了.这个案例是一个简易的论坛,开发这个论坛的初衷是为了验证用ENode框架来开发一个真实项目的可行性.目前这个论坛在UI上是使用了 ...
- dojo Provider(script、xhr、iframe)源码解析
总体结构 dojo/request/script.dojo/request/xhr.dojo/request/iframe这三者是dojo提供的provider.dojo将内部的所有provider构 ...
- Matrix Admin 后台模板笔记
一个后台模板用久了就想换一个.上次找到了Matrix Admin.和ACE一样都是Bootstrap风格,比较容易上手.Matrix要更健壮些.感觉拿去做用户界面也是可以的. 整体风格: 1.表单验证 ...
- Oracle存在修改,不存在插入记录
接触编程以来,在数据存储方面一直用的MS SQL.Oracle这名字对我来说是如此的熟悉,但是对其内容却很陌生,最近公司的一个项目用起了Oracle,所以也开始高调的用起了Oracle.在没有接触Or ...
- js模版引擎handlebars.js实用教程——with-终极this应用
返回目录 <!DOCTYPE html> <html> <head> <META http-equiv=Content-Type content=" ...
- onCreateView中加载大位图
我的一个Fragment中,加载了一个1024*1024的图片,非常卡.解决办法 1. 将图片改为512*512 2. 异步加载. final SmartImageView mizige = (Sma ...
- JS动态设置css的几种方式
1. 直接设置style的属性 某些情况用这个设置 !important值无效 如果属性有'-'号,就写成驼峰的形式(如textAlign) 如果想保留 - 号,就中括号的形式 element. ...