用caffe跑自己的数据,基于WINDOWS的caffe
本文详细介绍,如何用caffe跑自己的图像数据用于分类。
1 首先需要安装过程见 http://www.cnblogs.com/love6tao/p/5706830.html 同时依据上面教程,生成了caffe.exe
2 构建自己的数据集。分为train和val 两个数据集,本次实验为2分类任务,一个是包含汽车的图像,一个是不包含汽车图像,其中train 为训练数据集,该文件夹中图像命名格式为trainpos0000.jpg和trainneg0000.jpg,图像通过该命名方式连续编码,val为验证数据集或者叫测试数据,该文件夹中图像命名格式为test0000.jpg,和testneg0000.jpg。如下图所示
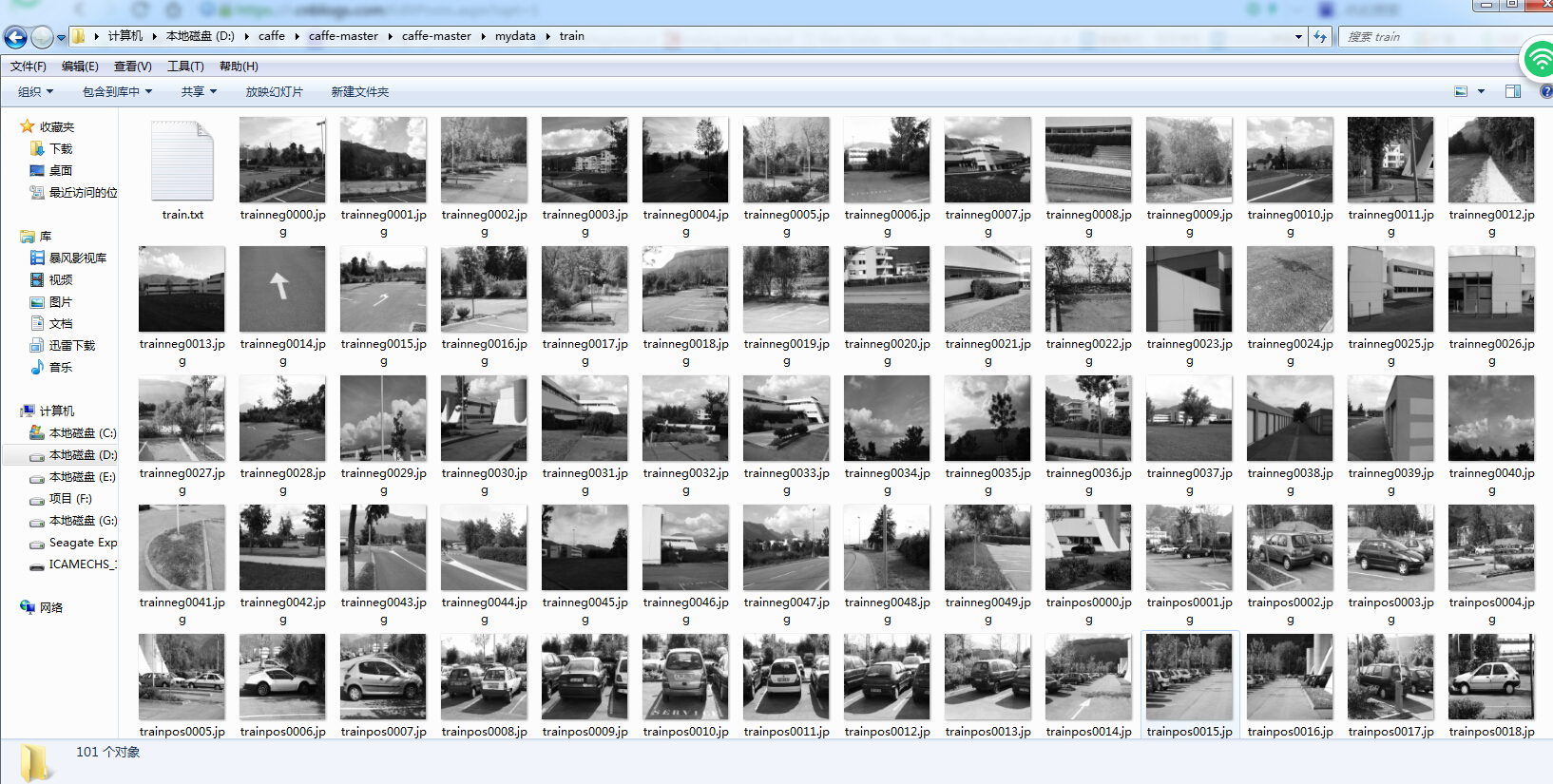
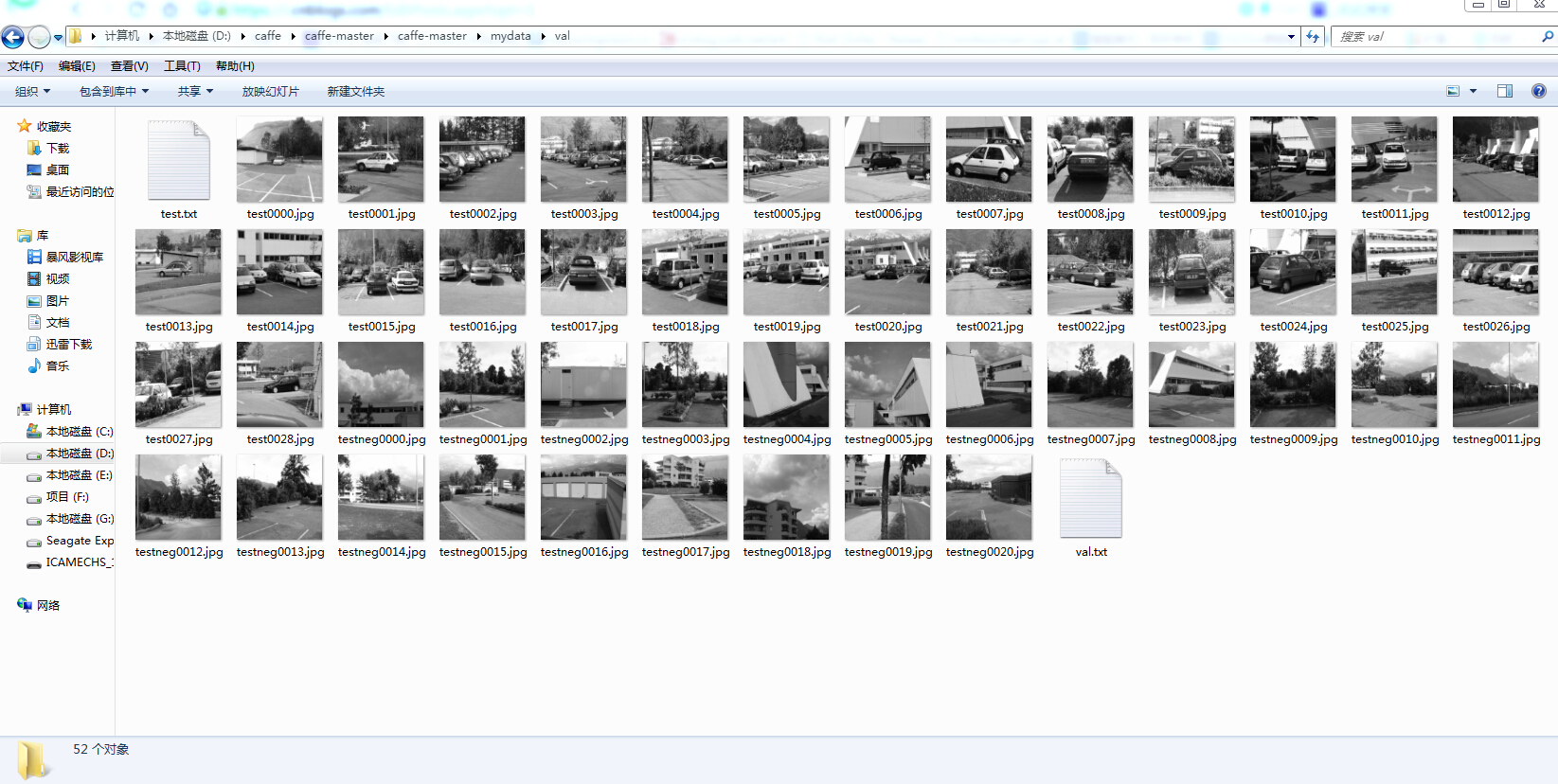
图像可以用过opencv中cvresize函数就行缩放到256*256.
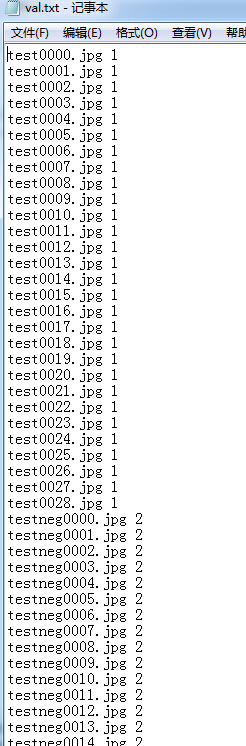
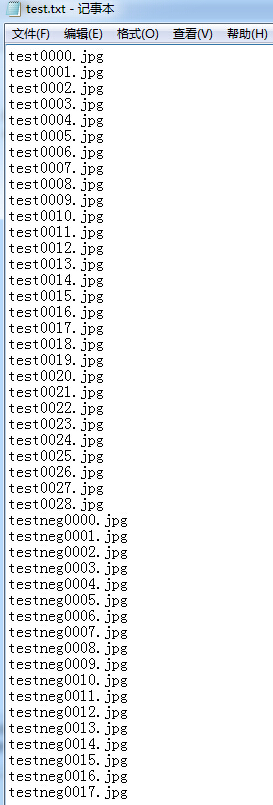
然后需要准备标签数据,通过新建train.txt val.txt和test.txt就行设置。通过windows命令行进行自动生成,首先在运行中输入cmd ,出现DOS窗口,输入d: 切换到D盘,
再输入cd D:\caffe\caffe-master\caffe-master\mydata\train 切换到train文件夹下 ,输入命令“dir/s/on/b>d:/train.txt”,则会在D盘生成一个名为train的文本文件,里面存放着全部图像的路径。 通过查找替换,最终生成的 train.txt val.txt和test.txt 。其中val.txt和test.txt 相比,test没有标签

3 讲数据集转化为caffe的数据类型
caffe的数据类型为LMDB和leveldb,caffe并不处理原始数据,而是转化为LMDB或者LEVELDB格式,这样可以保持较高的IO效率。
怎么转换呢?在caffe工程中有convert_imageset的工程,对其进行编译,形成convert_imageset.exe即可。
然后利用create_imagenet.sh使数据集生成leveldb格式的文件。create_imagenet.sh放在examples/imagenet中,将它拷贝到数据集的路径下,本文数据集
关键的是修改create_imagenet.sh中的路径使之能够进行数据转换
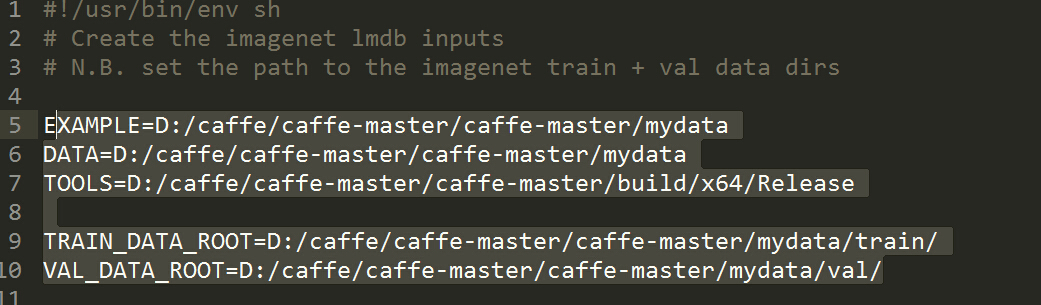
example设定为数据集的路径 data也设定为数据集路径 tools为convert_imageset.exe的路径
train_data_root 训练数据集路径 val_data_root 测试数据集路径
后面resize为false则其不需要转换为256*256
由于本文是转为leveldb文件类型 添加了这一句代码 ”--backend=leveldb\ “ 同时注意train.txt val.txt的路径是data路径下,
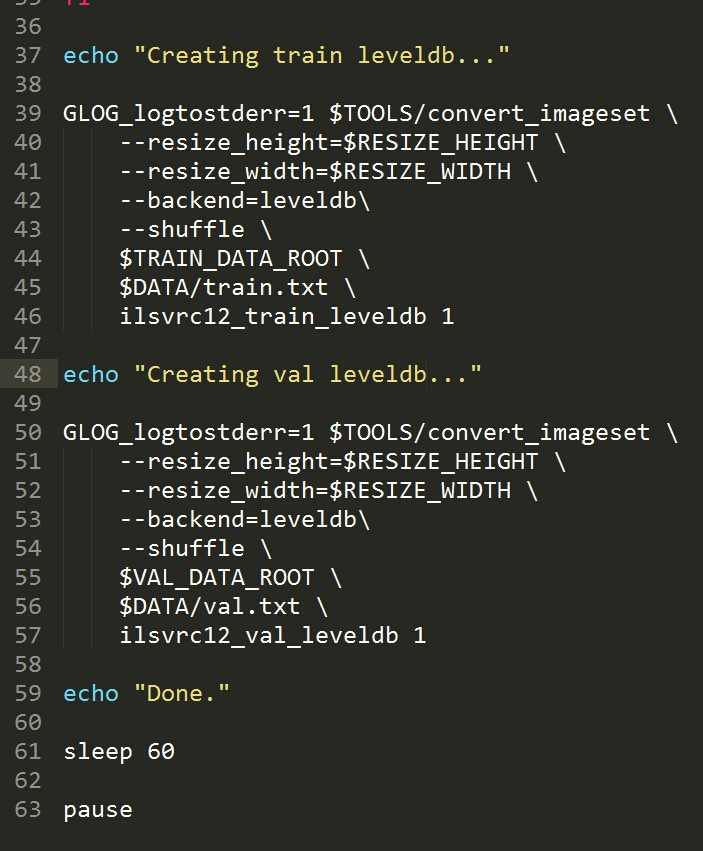
运行该程序,生成了两个leveldb文件夹,ilsvrc12_train_leveldb和ilsvrc12_val_leveldb
4 计算图像的均值
首先生成compute_image_mean.exe文件,该文件在caffe工程中也存在对应程序,对其进行编译,形成compute_image_mean.exe即可。
然后在examples/imagenet下有一个sh文件make_imagenet_mean.sh,将它拷贝到个人数据文件夹mydata中,然后打开这个文件进行编辑。
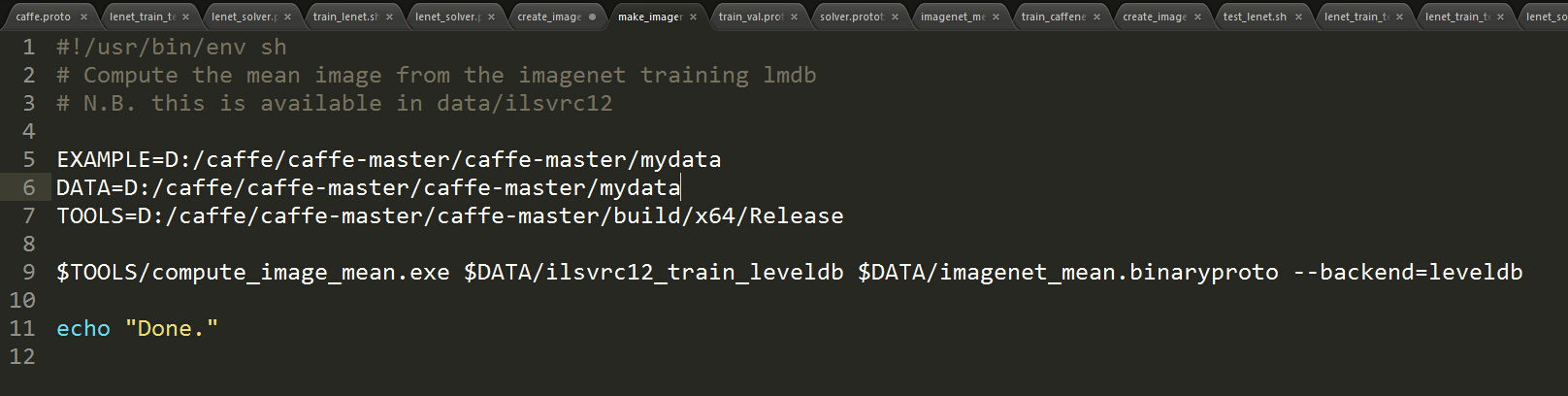
example是数据集路径 data 为数据集路径 tools为compute_image_mean.exe路径
第9行为利用exe 对train_leveldb 数据生成 imagenet_mean.binaryproto
运行make_imagenet_mean.sh后,会生成了 imagenet_mean.binaryproto
5 开始设计网络
5.1 设置train_val.prototxt文件
从caffe-root\models\bvlc_reference_caffenet中拷贝train_val.prototxt进行修改。
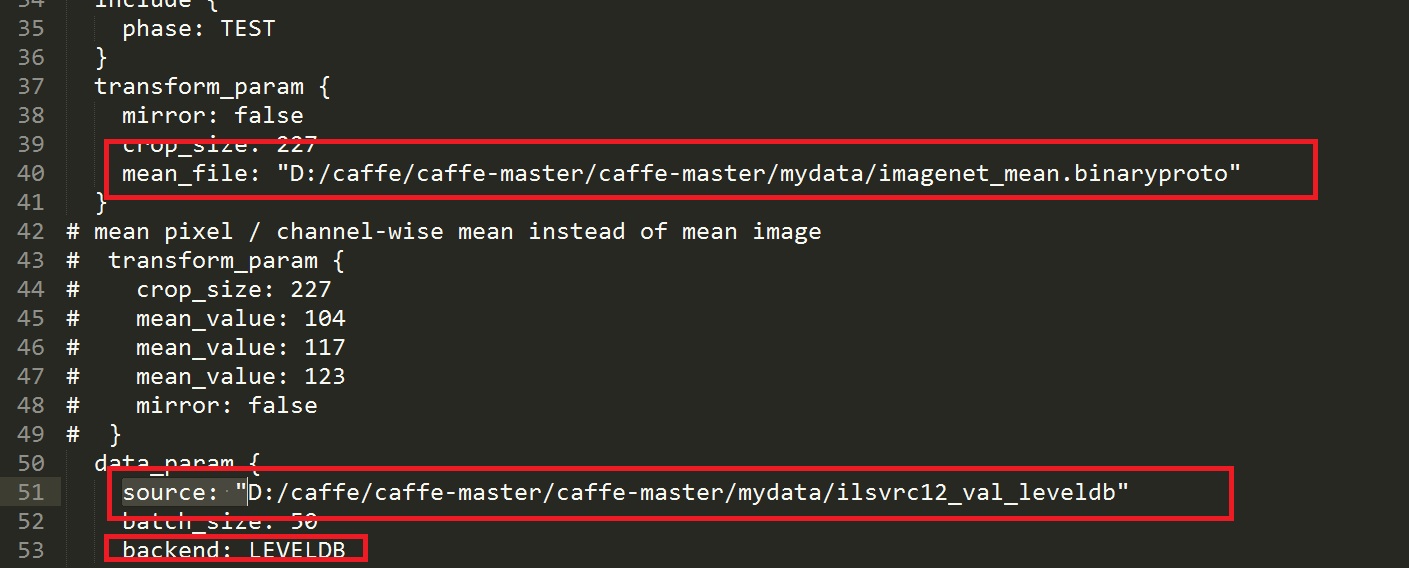
设置 mean_file: 和数据source:

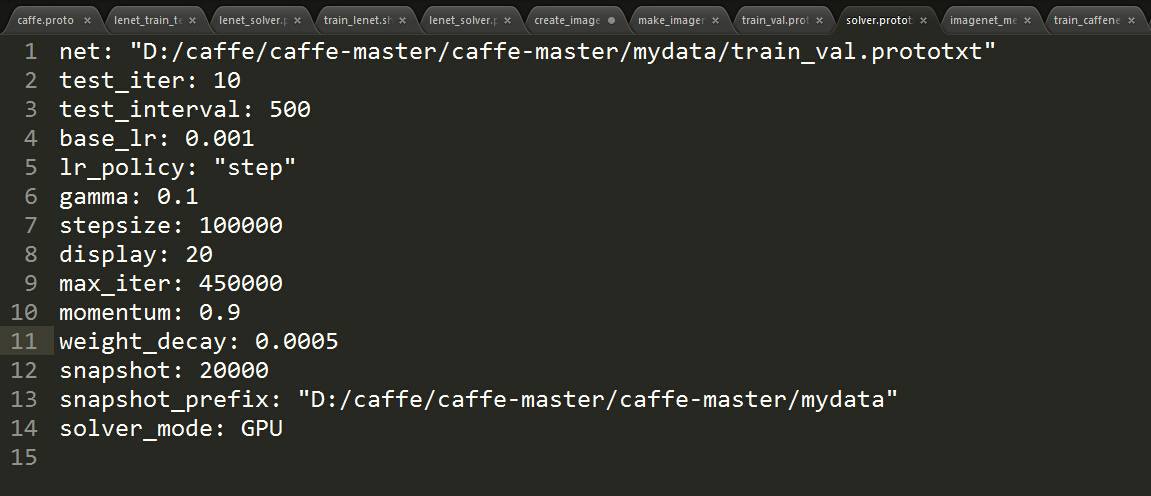
5.2 设置solver.prototxt文件
从caffe-root\models\bvlc_reference_caffenet中拷贝solver.prototxt进行修改。net的路径为上面设置的路径 ,后面迭代的参数按照实际情况修改。
5-3 训练网络,运行train_caffenet.sh文件
从caffe-root\\examples\imagenet中拷贝train_caffenet.sh进行修改。

设置caffe.exe路径 和上述solver.prototxt文件路径
训练结果:运行train_caffenet.sh文件效果
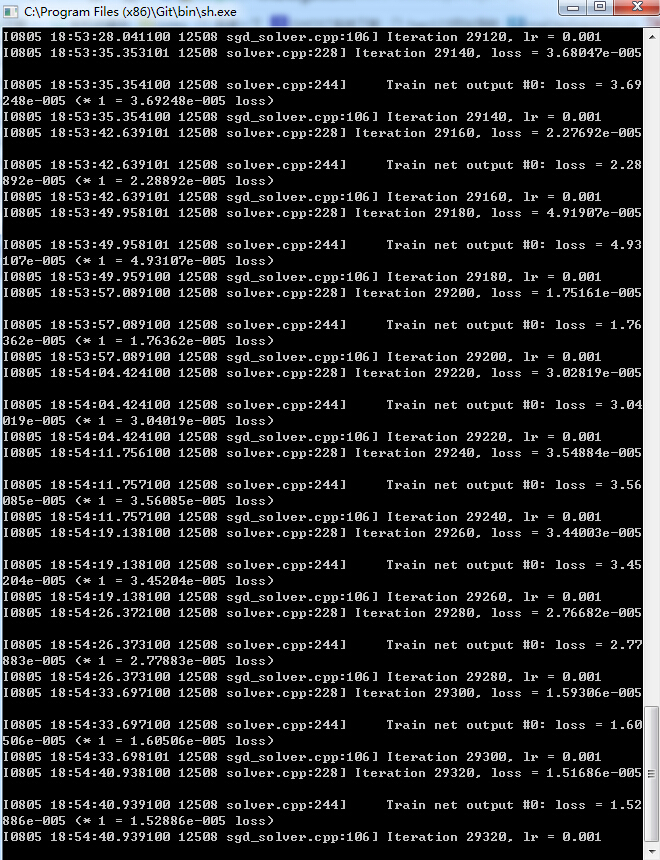
本机配置是win7+cude8.0+1080的显卡,可以看到loss在不断的降低。这是在设置好solve参数的情况下。
生成的model 为 mydata_iter_100.caffemodel
5-4 测试网络
在数据目录下新建一个文本文件,然后将后缀名改成sh。填入以下语句:

首先设置caffe.exe的路径 然后设置网络的路径,最后设置载入的训练参数路径。运行该sh文件,得到最后的分类正确率为:95%
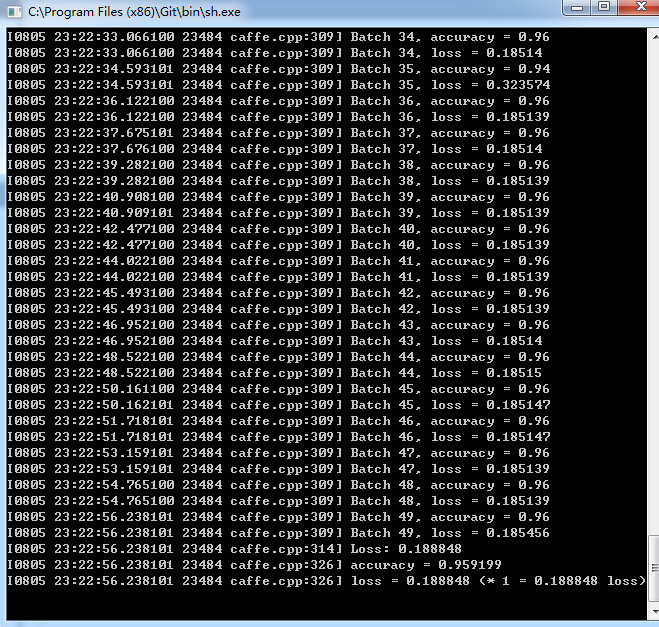
到处,整个训练和测试过程走通了,后续就是调节参数的问题了。
用caffe跑自己的数据,基于WINDOWS的caffe的更多相关文章
- Windows下用Caffe跑自己的数据(遥感影像)
1 前言 Caffe对于像我这样的初学者来说是一款非常容易上手的深度学习框架.关于用Caffe跑自己的数据这样的博客已经非常多,感谢前辈们为我们提供的这么好的学习资源.这里我主要结合我所在的行业,说下 ...
- caffe跑densenet的错误:Message type "caffe.PoolingParameter" has no field named "ceil_mode".【转自CSDN】
最近看了densenet这篇论文,论文作者给了基于caffe的源码,自己在电脑上跑了下,但是出现了Message type “caffe.PoolingParameter” has no field ...
- Windows下caffe安装详解(仅CPU)
本文大多转载自 http://blog.csdn.net/guoyk1990/article/details/52909864,加入部分自己实战心得. 1.环境:windows 7\VS2013 2. ...
- CAFFE学习笔记(五)用caffe跑自己的jpg数据
1 收集自己的数据 1-1 我的训练集与测试集的来源:表情包 由于网上一幅一幅图片下载非常麻烦,所以我干脆下载了两个eif表情包.同一个表情包里的图像都有很强的相似性,因此可以当成一类图像来使用.下载 ...
- 判断OpenCV是否为共享库,Windows基于CMake编译Caffe需要opencv共享库
判断OpenCV是否为共享库,Windows基于CMake编译Caffe需要opencv共享库 TLDR 只考虑windows下opencv预编译包的情况. 对于opencv2.4.x系列,cmake ...
- Caffe+VS2015+python3的安装(基于windows)
在网上找了许多安装Caffe的教程 感觉全都是杂乱无章的 而且也没有详细的 只能自己当小白鼠来实验一次了 本次配置:CUDA 8.0+ CUDNN +VS 2015 +Python 3.5 + Ca ...
- 你的计算机也可以看懂世界——十分钟跑起卷积神经网络(Windows+CPU)
众所周知,如果你想研究Deep Learning,那么比较常用的配置是Linux+GPU,不过现在很多非计算机专业的同学有时也会想采用Deep Learning方法来完成一些工作,那么Linux+GP ...
- Wizard Framework:一个自己开发的基于Windows Forms的向导开发框架
最近因项目需要,我自己设计开发了一个基于Windows Forms的向导开发框架,目前我已经将其开源,并发布了一个NuGet安装包.比较囧的一件事是,当我发布了NuGet安装包以后,发现原来已经有一个 ...
- VC中基于 Windows 的精确定时[转]
在工业生产控制系统中,有许多需要定时完成的操作,如定时显示当前时间,定时刷新屏幕上的进度条,上位 机定时向下位机发送命令和传送数据等.特别是在对控制性能要求较高的实时控制系统和数据采集系统中,就更需要 ...
随机推荐
- Version history of VC++, MFC and ATL
I have tried to assemble together information about the Visual C++ releases, the compiler and the fr ...
- linux安装oracle 11g rac
安装oracle 11gR2 RAC 一.网络规划及安装虚拟主机 主机名 主机版本 Ip rac1.localdomain Redhat 6.5 RAC节点1 192.168.100.11 rac2. ...
- 调试SQLSERVER (一)生成dump文件的方法
调试SQLSERVER (一)生成dump文件的方法 调试SQLSERVER (二)使用Windbg调试SQLSERVER的环境设置调试SQLSERVER (三)使用Windbg调试SQLSERVER ...
- [Asp.net 开发系列之SignalR篇]专题二:使用SignalR实现酷炫端对端聊天功能
一.引言 在前一篇文章已经详细介绍了SignalR了,并且简单介绍它在Asp.net MVC 和WPF中的应用.在上篇博文介绍的都是群发消息的实现,然而,对于SignalR是为了实时聊天而生的,自然少 ...
- Nim教程【九】
向关注这个系列的朋友们,道一声:久违了! 它并没有被我阉掉,他一定会得善终的,请各位不要灰心 Set集合类型 为了在特殊场景下提高程序的性能设置了Set类型,同时也是为了保证性能,所以Set只能容纳有 ...
- Linux 比较判断运算(if test)
200 ? "200px" : this.width)!important;} --> 介绍 本篇文章主要是列举在shell命令中常出现的一些用来做比较的运算符,这些运算符是 ...
- Objective-C 随机数
有个项目要给客户发送随机验证码, 试了下这样可以 srand(time()); code = [NSString stringWithFormat: - )) + ];
- Java-单例模式(singleton)-转载
概念: java中单例模式是一种常见的设计模式,单例模式分三种:懒汉式单例.饿汉式单例.登记式单例三种. 单例模式有一下特点: 1.单例类只能有一个实例. 2.单例类必须自己自己创建自己的唯一实例. ...
- 爱上MVC~为DisplayNameFor添加扩展,支持PagedList集合
回到目录 DisplayNameFor方法是MVC提供给我们的,它可以将模型的DisplayName特性的值显示到页面上,这对程序员来说很是方便,在进行实体设计时,可以指定它的显示名称,然后MVC引擎 ...
- Lua字符串库(整理)
Lua字符串库小集 1. 基础字符串函数: 字符串库中有一些函数非常简单,如: 1). string.len(s) 返回字符串s的长度: 2). string.rep(s,n) 返回 ...